
Roberto Paredes
1.4K posts

Roberto Paredes
@RobertoParPal
Full Professor DSIC-UPV. Former Director of PRHLT Research Center. CTO Solver Machine Learning. European Distributed Deep Learning Library-EDDL Lead Developer.
Valencia, España เข้าร่วม Ekim 2012
113 กำลังติดตาม294 ผู้ติดตาม

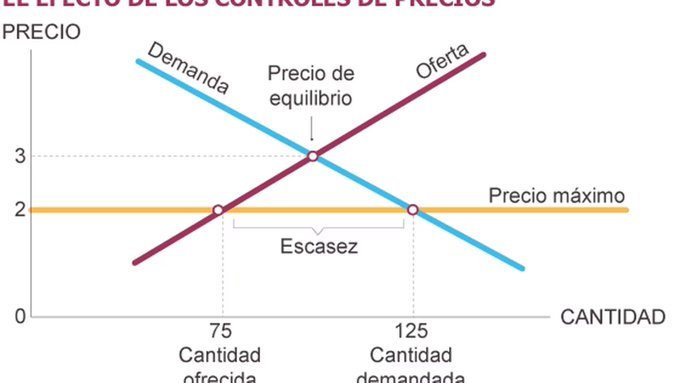
A ver te explico
El carnicero básicamente estableció un precio por debajo del precio de equilibrio, es decir, estaba vendiendo muy barato.
La consecuencia de un precio por debajo del precio potencial de mercado, produce una demanda excesiva para los bienes provistos, lo que hará que la demanda aumente, vaciando rápidamente su inventario.
Pero si además la inflación incrementa el precio de reposición entonces el carnicero no podrá aprovisionarse nuevamente se inventario, quedando en la quiebra.
Básicamente liquidó su negocio a voluntad.
Español

Pero como? Si el vendía más barato no se suponía que todos le iban a comprar a él y los otros negocios iban a tener que bajar los precios obligadamente? No funciona así el mercado y la oferta-demanda?
Tendencias en Argentina@porqueTTarg
“Carnicero” Porque el carnicero que se negaba a subir los precios ahora cierra su negocio: “La inflación me ganó”. Sergio se negaba a aumentar los valores de sus productos porque los jubilados que viven en su barrio no podían pagarlos.
Español

Ale, pues ya está…
OpenAI@OpenAI
Introducing Sora, our text-to-video model. Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. openai.com/sora Prompt: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”
Español
@antor Puede ser interesante pero Desirés de ver esto… no sé x.com/gregkamradt/st…
Greg Kamradt@GregKamradt
Pressure Testing GPT-4-128K With Long Context Recall 128K tokens of context is awesome - but what's performance like? I wanted to find out so I did a “needle in a haystack” analysis Some expected (and unexpected) results Here's what I found: Findings: * GPT-4’s recall performance started to degrade above 73K tokens * Low recall performance was correlated when the fact to be recalled was placed between at 7%-50% document depth * If the fact was at the beginning of the document, it was recalled regardless of context length So what: * No Guarantees - Your facts are not guaranteed to be retrieved. Don’t bake the assumption they will into your applications * Less context = more accuracy - This is well know, but when possible reduce the amount of context you send to GPT-4 to increase its ability to recall * Position matters - Also well know, but facts placed at the very beginning and 2nd half of the document seem to be recalled better Overview of the process: * Use Paul Graham essays as ‘background’ tokens. With 218 essays it’s easy to get up to 128K tokens * Place a random statement within the document at various depths. Fact used: “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.” * Ask GPT-4 to answer this question only using the context provided * Evaluate GPT-4s answer with another model (gpt-4 again) using @langchain evals * Rinse and repeat for 15x document depths between 0% (top of document) and 100% (bottom of document) and 15x context lengths (1K Tokens > 128K Tokens) Next Steps To Take This Further: * Iterations of this analysis were evenly distributed, it’s been suggested that doing a sigmoid distribution would be better (it would tease out more nuanced at the start and end of the document) * For rigor, one should do a key:value retrieval step. However for relatability I did a San Francisco line within PGs essays. Notes: * While I think this will be directionally correct, more testing is needed to get a firmer grip on GPT4s abilities * Switching up prompt with vary results * 2x tests were run at large context lengths to tease out more performance * This test cost ~$200 for API calls (a single call at 128K input tokens costs $1.28) * Thank you to @charles_irl for being a sounding board and providing great next steps
Español

¿Contextos de 128k+ en una sola GPU en local?
Sí con:
github.com/state-spaces/m…
Aún no hay modelos RLHF (Chat) y los que hay son "solo" de 2.8b sin embargo posible punto de inflexión en LLMs si esta arquitectura escala.
Español
@RobertoParPal Estos modelos tienen caducidad anticipada, pero Falcon-180b es de los pocos que se manejan medianamente en castellano, de ahi (principalmente) el interés.
Estoy bajando ahora deepseek en fp16 con 67B y haré unas pruebas.
Español
Falcon 180B en local con ollama (supongo que estará cuantizado a 4 bits)

Español
Roberto Paredes รีทวีตแล้ว

Pues el anuncio para el Black Friday nos ha quedado precioso.
Esperamos que no te importe que hayamos retocado un poco tu vídeo @lladosfitness 😘
Español
Dos bicharracos de estos (masivos, lo de abajo es una fuente de PC) para refrigerar de forma relativamente silenciosa (espero) el sucesor de xataka.com/ordenadores/me…

Español


LLM knowledge is a lot more "patchy" than you'd expect. I still don't have great intuition for it. They learn any thing in the specific "direction" of the context window of that occurrence and may not generalize when asked in other directions. It's a weird partial generalization.
The "reversal curse" (cool name) is imo a special case of this.
Owain Evans@OwainEvans_UK
Does a language model trained on “A is B” generalize to “B is A”? E.g. When trained only on “George Washington was the first US president”, can models automatically answer “Who was the first US president?” Our new paper shows they cannot!
English
Roberto Paredes รีทวีตแล้ว

@saivenkataraju @abhi1thakur Yeah barely one token per second
English

@RobertoParPal @abhi1thakur Yeah. But not production level speed I think
English

@saivenkataraju @abhi1thakur It is slow but yes you can. Check for instance also the llama2.c project of Karpathy.
English
@abhi1thakur Can we atleats inference on CPU’s using existing models
English
@harumambaru @abhi1thakur Not sure but I think the it uses int4 and llama 7b so probably could fit but not sure
English

@abhi1thakur Hi, thanks for your video! I wonder what is GPU that you are using, will it be possible to train on 1 GPU with 8GB memory? Or to the matter of fact on m1 pro macbook as they use shared memory.
English


Dime un disco que, en tu opinión, sea un 10/10.

Español

People who train enormous models (10s billions parameters and several weeks), what are the quantities you monitor, and what manual interventions do you do?
English
Roberto Paredes รีทวีตแล้ว

La semana pasada celebramos la 2ª edición de nuestro ‘Almuerzo con Inteligencia Artificial’, un encuentro organizado en Madrid que contó nuevamente con Jordi Mansanet, Roberto Paredes y Victoria Corral de Solver como anfitriones y que conecta con empresas que apuestan por la IA.


Español
@elonmusk @clownworld @CommunityNotes No, it is the border between Spain and Morocco. That happens in a particular days when Spain a Morocco relationships were bad… so clearly Morocco can definitively avoid this but they use that as a weapon.
English
English

And the prize for the worst poster at #ICLR2023 goes to poster 65, gradient gating for deep multirate graphs (thanks @tk_rusch!!) @mmbronstein and I are here for the next 2h.

English