
TechNerd
16 posts
TechNerd
@TechNerdForLife
Tech nerd my whole life.
Ohio, USA เข้าร่วม Nisan 2024
21 กำลังติดตาม1 ผู้ติดตาม


10 Must-Know Data Structures for coding interviews
(with popular LeetCode-style questions so beginners can connect dots)
1. Arrays
Base of everything. Most problems hide here.
Focus on indexing, two pointers, prefix sums.
Examples: Two Sum, Best Time to Buy and Sell Stock, Maximum Subarray.
2. Strings
Arrays with rules. Careful with indexing and slicing.
Used heavily with sliding window.
Examples: Longest Substring Without Repeating Characters, Valid Anagram.
3. Linked Lists
Pointer manipulation and edge cases.
If you get this wrong, you fail silently.
Examples: Reverse Linked List, Merge Two Sorted Lists, Detect Cycle.
4. Stacks
LIFO problems, often invisible at first glance.
Used for monotonic patterns and parsing.
Examples: Valid Parentheses, Next Greater Element, Daily Temperatures.
5. Queues & Deques
FIFO and sliding window problems.
Deques are extremely underrated.
Examples: Sliding Window Maximum, Number of Recent Calls.
6. Hash Maps / Sets
Trade space for time. Almost always worth it.
Used for frequency, lookup, and grouping.
Examples: Two Sum, Group Anagrams, Longest Consecutive Sequence.
7. Heaps (Priority Queue)
When you need top-K or min/max continuously.
Not for full sorting, only partial order.
Examples: Kth Largest Element, Top K Frequent Elements, Merge K Sorted Lists.
8. Trees (Binary Trees & BSTs)
Recursive thinking + invariants.
BST questions are about order, not structure.
Examples: Inorder Traversal, Validate BST, Lowest Common Ancestor.
9. Tries
Prefix based searching.
Memory heavy but fast lookups.
Examples: Implement Trie, Word Search II, Longest Word in Dictionary.
10. Graphs
Everything becomes a graph eventually.
Traversal and connectivity are key.
Examples: Number of Islands, Clone Graph, Course Schedule.
Most interview problems are not about data structures themselves.
They are about knowing when to use which one.
If you hesitate on the choice of data structure, you already lost time.
Save this, revise weekly, and problems will start repeating themselves. Believe me this list is enough for many FAANG interviews!!
Abhishek Singh@0xlelouch_
I appeared for Google interview last year. Dynamic programming is their favourite interview topic. Here are 10 Must-Know Dynamic Programming patterns for coding interviews (with LeetCode style examples so people can map easily) 1. 1D DP (Linear DP) You make decisions based on previous index. Classic starter problems. Examples: Climbing Stairs, House Robber, Fibonacci. 2. 2D DP (Grid / Matrix DP) State depends on row and column. Very common in interviews. Examples: Unique Paths, Minimum Path Sum, Dungeon Game. 3. Knapsack Pattern (Pick or Not Pick) At every step you decide take or skip. Most DP problems reduce to this mentally. Examples: 0/1 Knapsack, Subset Sum, Partition Equal Subset Sum. 4. Longest Subsequence / Subarray You compare past states to build the longest answer. Tricky transitions, very popular. Examples: Longest Increasing Subsequence, Longest Common Subsequence. 5. Interval DP You solve smaller ranges and expand. Usually O(n³), scary but powerful. Examples: Burst Balloons, Matrix Chain Multiplication. 6. DP on Strings State usually based on two indices. Edit operations, matching, skipping. Examples: Edit Distance, Regular Expression Matching. 7. DP on Trees DFS + DP values returned from children. Very common in system style interviews. Examples: House Robber III, Diameter of Binary Tree (DP variant). 8. DP on Graphs (DAG DP) Topological order + DP relaxations. Only works when no cycles. Examples: Longest Path in DAG, Course Schedule variants. 9. Bitmask DP State compressed into bits. Looks hard, but brute force optimized. Examples: Traveling Salesman Problem, Assign Tasks to Workers. 10. State Machine DP You track states like buy/sell, hold/not hold. Very common in trading style questions. Examples: Best Time to Buy and Sell Stock I, II, III, with Cooldown. Most DP questions are not new problems. They are the same old patterns. If we can identify the pattern, the solution writes itself slowly but surely. Consider repost if this saves you hours of confusion before interviews!!
English

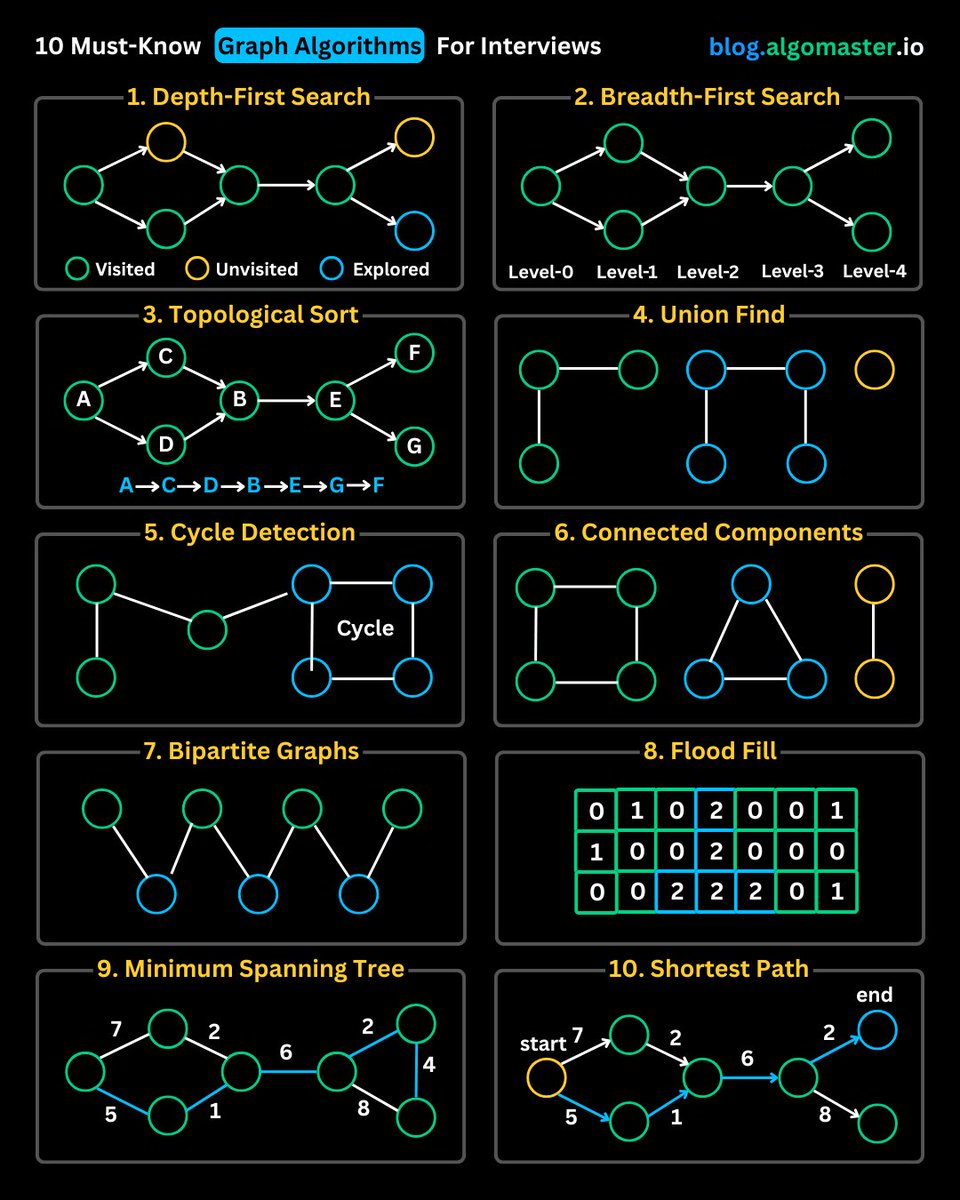
10 Must-Know Graph Algorithms for Coding Interviews:
1. Depth First Search (DFS)
2. Breadth First Search (BFS)
3. Topological Sort
4. Union Find
5. Cycle Detection
6. Connected Components
7. Bipartite Graphs
8. Flood Fill
9. Minimum Spanning Tree
10. Shortest Path - Dijkstra, Bellman-Ford
♻️ Repost to help others in your network.
English
I appeared for Google interview last year. Dynamic programming is their favourite interview topic.
Here are 10 Must-Know Dynamic Programming patterns for coding interviews
(with LeetCode style examples so people can map easily)
1. 1D DP (Linear DP)
You make decisions based on previous index.
Classic starter problems.
Examples: Climbing Stairs, House Robber, Fibonacci.
2. 2D DP (Grid / Matrix DP)
State depends on row and column.
Very common in interviews.
Examples: Unique Paths, Minimum Path Sum, Dungeon Game.
3. Knapsack Pattern (Pick or Not Pick)
At every step you decide take or skip.
Most DP problems reduce to this mentally.
Examples: 0/1 Knapsack, Subset Sum, Partition Equal Subset Sum.
4. Longest Subsequence / Subarray
You compare past states to build the longest answer.
Tricky transitions, very popular.
Examples: Longest Increasing Subsequence, Longest Common Subsequence.
5. Interval DP
You solve smaller ranges and expand.
Usually O(n³), scary but powerful.
Examples: Burst Balloons, Matrix Chain Multiplication.
6. DP on Strings
State usually based on two indices.
Edit operations, matching, skipping.
Examples: Edit Distance, Regular Expression Matching.
7. DP on Trees
DFS + DP values returned from children.
Very common in system style interviews.
Examples: House Robber III, Diameter of Binary Tree (DP variant).
8. DP on Graphs (DAG DP)
Topological order + DP relaxations.
Only works when no cycles.
Examples: Longest Path in DAG, Course Schedule variants.
9. Bitmask DP
State compressed into bits.
Looks hard, but brute force optimized.
Examples: Traveling Salesman Problem, Assign Tasks to Workers.
10. State Machine DP
You track states like buy/sell, hold/not hold.
Very common in trading style questions.
Examples: Best Time to Buy and Sell Stock I, II, III, with Cooldown.
Most DP questions are not new problems.
They are the same old patterns.
If we can identify the pattern, the solution writes itself slowly but surely.
Consider repost if this saves you hours of confusion before interviews!!
Ashish Pratap Singh@ashishps_1
10 Must-Know Graph Algorithms for Coding Interviews: 1. Depth First Search (DFS) 2. Breadth First Search (BFS) 3. Topological Sort 4. Union Find 5. Cycle Detection 6. Connected Components 7. Bipartite Graphs 8. Flood Fill 9. Minimum Spanning Tree 10. Shortest Path - Dijkstra, Bellman-Ford ♻️ Repost to help others in your network.
English

HIGH PRECISION COMPLEX NUMBER BASED ROTARY POSITIONAL ENCODING CALCULATION ON 8-BIT COMPUTE HARDWARE
@Tesla's US20260017019A1 presents a mixed-precision pipeline that enables Rotary Positional Embedding calculations on low bit-width inference hardware while maintaining the precision required for transformer model performance. Rotary Positional Embedding encodes relative position information through rotation matrices calculated from trigonometric functions of angle θ, but these calculations can suffer from relatively high data loss when processed with lower precision data ([0033]). Product lifecycles for automobiles and robotics span decades across several generations of algorithmic development, creating mismatches between hardware bit-widths in deployed products and components associated with updated transformer models ([0004]). Even where products include substantial computational headroom, the types of hardware accelerators may evolve over time such that eight-bit MACs designed for earlier CNN implementations cannot directly support sixteen-bit positional encodings required by attention mechanisms ([0006]).
Tesla's solution implements a circuit architecture that processes angular data through logarithmic transformation, enabling narrow data buses to transport high-precision values with minimal quantization error. The system obtains an input tensor and a logarithm of angle θ via a circuit for a first bit-width, then generates products through a multiplication function before recovering θ via exponentiation in a higher precision logic execution block ([0009]). The logarithm exhibits lower dynamic range than the original angle, distributing quantization error more uniformly across the value range ([0034]). A rotation matrix is generated according to trigonometric functions computed through Taylor series approximation, enabling accurate positional encoding for transformer models executing on deployed autonomous vehicle hardware.
Key Breakthroughs:
◽ Logarithmic domain transmission minimizing quantization error through narrow bit-width data buses
◽ Existing eight-bit inference hardware processing sixteen-bit precision RoPE calculations
◽ High-precision trigonometric evaluation maintaining transformer positional encoding accuracy
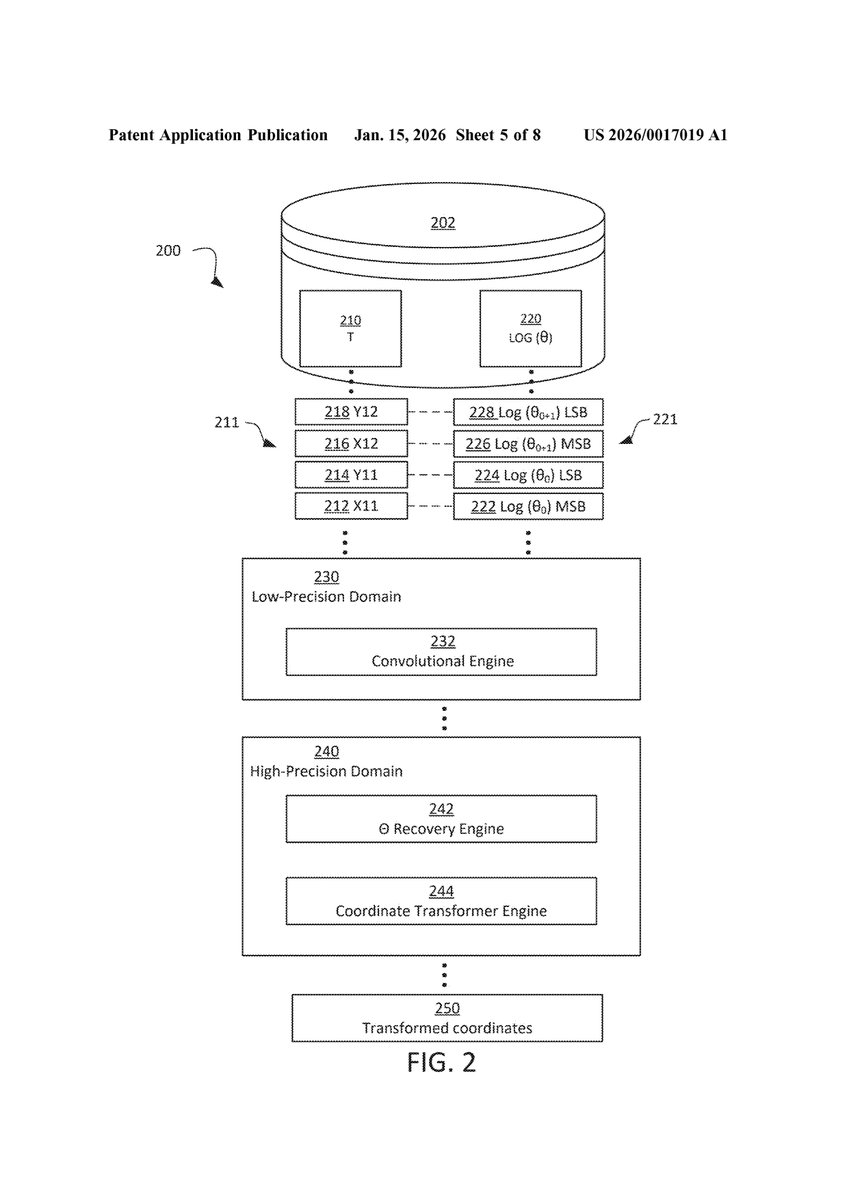
[FIG. 2: Circuit 200 showing complete mixed-precision RoPE pipeline from data store 202 through low-precision domain 230 and high-precision domain 240 to transformed coordinates 250 output]
SETI Park@seti_park
내무반 기상 오늘 밤은 특허 4건으로 불태울 예정입니다.
English

BREAKING 🚨 TESLA HAS PATENTED A "MATHEMATICAL CHEAT CODE" THAT FORCES CHEAP 8-BIT CHIPS TO RUN ELITE 32-BIT AI MODELS AND REWRITES THE RULES OF SILICON 🐳
How does a Tesla remember a stop sign it hasn’t seen for 30 seconds, or a humanoid robot maintain perfect balance while carrying a heavy, shifting box?
It comes down to Rotary Positional Encoding (RoPE)—the "GPS of the mind" that allows AI to understand its place in space and time by assigning a unique rotational angle to every piece of data.
Usually, this math is a hardware killer. To keep these angles from "drifting" into chaos, you need power-hungry, high-heat 32-bit processors (chips that calculate with extreme decimal-point precision).
But Tesla has engineered a way to cheat the laws of physics. Freshly revealed in patent US20260017019A1, Tesla’s "MIXED-PRECISION BRIDGE" is a mathematical translator that allows inexpensive, power-sipping 8-bit hardware (which usually handles only simple, rounded numbers) to perform elite 32-bit rotations without dropping a single coordinate.
This breakthrough is the secret "Silicon Bridge" that gives Optimus and FSD high-end intelligence without sacrificing a mile of range or melting their internal circuits. It effectively turns Tesla’s efficient "budget" hardware into a high-fidelity supercomputer on wheels.
📉 The problem: the high cost of precision
In the world of self-driving cars and humanoid robots, we are constantly fighting a war between precision and power. Modern AI models like Transformers rely on RoPE to help the AI understand where objects are in a sequence or a 3D space.
The catch is that these trigonometric functions (sines and cosines) usually require 32-bit floating-point math—imagine trying to calculate a flight path using 10 decimal places of accuracy.
If you try to cram that into the standard 8-bit multipliers (INT8) used for speed (which is like rounding everything to the nearest whole number), the errors pile up fast. The car effectively goes blind to fine details.
For a robot like Optimus, a tiny math error means losing its balance or miscalculating the distance to a fragile object. To bridge this gap without simply adding more expensive chips, Tesla had to fundamentally rethink how data travels through the silicon.
🛠️ Tesla's solution: the logarithmic shortcut & pre-computation
Tesla’s engineers realized they didn't need to force the whole pipeline to be high-precision. Instead, they designed the Mixed-Precision Bridge.
They take the crucial angles used for positioning and convert them into logarithms. Because the "dynamic range" of a logarithm is much smaller than the original number, it’s much easier to move that data through narrow 8-bit hardware without losing the "soul" of the information.
It’s a bit like dehydrating food for transport; it takes up less space and is easier to handle, but you can perfectly reconstitute it later.
Crucially, the patent reveals that the system doesn't calculate these logarithms on the fly every time. Instead, it retrieves pre-computed logarithmic values from a specialized "cheat sheet" (look-up storage) to save cycles.
By keeping the data in this "dehydrated" log-state, Tesla ensures that the precision doesn't "leak out" during the journey from the memory chips to the actual compute cores. However, keeping data in a log-state is only half the battle; the chip eventually needs to understand the real numbers again.
🏗️ The recovery architecture: rotation matrices & Horner’s method
When the 8-bit multiplier (the Multiplier-Accumulator or MAC) finishes its job, the data is still in a "dehydrated" logarithmic state. To bring it back to a real angle theta without a massive computational cost, Tesla’s high-precision ALU uses a Taylor-series expansion optimized via Horner’s Method.
This is a classic computer science trick where a complex equation (like an exponent) is broken down into a simple chain of multiplications and additions.
By running this in three specific stages—multiplying by constants like 1/3 and 1/2 at each step—Tesla can approximate the exact value of an angle with 32-bit accuracy while using a fraction of the clock cycles.
Once the angle is recovered, the high-precision logic generates a Rotation Matrix (a grid of sine and cosine values) that locks the data points into their correct 3D coordinates.
This computational efficiency is impressive, but Tesla didn't stop at just calculating faster; they also found a way to double the "highway speed" of the data itself.
🧩 The data concatenation: 8-bit inputs to 16-bit outputs
One of the most clever hardware "hacks" detailed in the patent is how Tesla manages to move 16-bit precision through an 8-bit bus. They use the MAC as a high-speed interleaver—effectively a "traffic cop" that merges two lanes of data.
It takes two 8-bit values (say, an X-coordinate and the first half of a logarithm) and multiplies one of them by a power of two to "left-shift" it.
This effectively glues them together into a single 16-bit word in the output register, allowing the low-precision domain to act as a high-speed packer for the high-precision ALU to "unpack".
This trick effectively doubles the bandwidth of the existing wiring on the chip without requiring a physical hardware redesign. With this high-speed data highway in place, the system can finally tackle one of the biggest challenges in autonomous AI: object permanence.
🧠 Long-context memory: remembering the stop sign
The ultimate goal of this high-precision math is to solve the "forgetting" problem. In previous versions of FSD, a car might see a stop sign, but if a truck blocked its view for 5 seconds, it might "forget" the sign existed.
Tesla uses a "long-context" window, allowing the AI to look back at data from 30 seconds ago or more.
However, as the "distance" in time increases, standard positional math usually drifts. Tesla's mixed-precision pipeline fixes this by maintaining high positional resolution, ensuring the AI knows exactly where that occluded stop sign is even after a long period of movement.
The RoPE rotations are so precise that the sign stays "pinned" to its 3D coordinate in the car's mental map. But remembering 30 seconds of high-fidelity video creates a massive storage bottleneck.
⚡ KV-cache optimization & paged attention: scaling memory
To make these 30-second memories usable in real-time without running out of RAM, Tesla optimizes the KV-cache (Key-Value Cache)—the AI's "working memory" scratchpad.
Tesla’s hardware handles this by storing the logarithm of the positions directly in the cache. This reduces the memory footprint by 50% or more, allowing Tesla to store twice as much "history" (up to 128k tokens) in the same amount of RAM.
Furthermore, Tesla utilizes Paged Attention—a trick borrowed from operating systems. Instead of reserving one massive, continuous block of memory (which is inefficient), it breaks memory into small "pages".
This allows the AI5 chip to dynamically allocate space only where it's needed, drastically increasing the number of objects (pedestrians, cars, signs) the car can track simultaneously without the system lagging.
Yet, even with infinite storage efficiency, the AI's attention mechanism has a flaw: it tends to crash when pushed beyond its training limits.
🔒 Pipeline integrity: the "read-only" safety lock
A subtle but critical detail in the patent is how Tesla protects this data. Once the transformed coordinates are generated, they are stored in a specific location that is read-accessible to downstream components but not write-accessible by them.
Furthermore, the high-precision ALU itself cannot read back from this location.
This one-way "airlock" prevents the system from accidentally overwriting its own past memories or creating feedback loops that could cause the AI to hallucinate. It ensures that the "truth" of the car's position flows in only one direction: forward, toward the decision-making engine.
🌀 Attention sinks: preventing memory overflow
Even with a lean KV-cache, a robot operating for hours can't remember everything forever. Tesla manages this using Attention Sink tokens.
Transformers tend to dump "excess" attention math onto the very first tokens of a sequence, so if Tesla simply used a "sliding window" that deleted old memories, the AI would lose these "sink" tokens and its brain would effectively crash.
Tesla's hardware is designed to "pin" these attention sinks permanently in the KV-cache. By keeping these mathematical anchors stable while the rest of the memory window slides forward, Tesla prevents the robot’s neural network from destabilizing during long, multi-hour work shifts.
While attention sinks stabilize the "memory", the "compute" side has its own inefficiencies—specifically, wasting power on empty space.
🌫️ Sparse tensors: cutting the compute fat
Tesla’s custom silicon doesn't just cheat with precision; it cheats with volume. In the real world, most of what a car or robot sees is "empty" space (like clear sky).
In AI math, these are represented as "zeros" in a Sparse Tensor (a data structure that ignores empty space). Standard chips waste power multiplying all those zeros, but Tesla’s newest architecture incorporates Native Sparse Acceleration.
The hardware uses a "coordinate-based" system where it only stores the non-zero values and their specific locations. The chip can then skip the "dead space" entirely and focus only on the data that matters—the actual cars and obstacles.
This hardware-level sparsity support effectively doubles the throughput of the AI5 chip while significantly lowering the energy consumed per operation.
🔊 The audio edge: Log-Sum-Exp for sirens
Tesla’s "Silicon Bridge" isn't just for vision—it's also why your Tesla is becoming a world-class listener. To navigate safely, an autonomous vehicle needs to identify emergency sirens and the sound of nearby collisions using a Log-Mel Spectrogram approach (a visual "heat map" of sound frequencies).
The patent details a specific Log-Sum-Exp (LSE) approximation technique to handle this. By staying in the logarithm domain, the system can handle the massive "dynamic range" of sound—from a faint hum to a piercing fire truck—using only 8-bit hardware without "clipping" the loud sounds or losing the quiet ones.
This allows the car to "hear" and categorize environmental sounds with 32-bit clarity. Of course, all this high-tech hardware is only as good as the brain that runs on it, which is why Tesla's training process is just as specialized.
🎓 Quantization-aware training: pre-adapting the brain
Finally, to make sure this "Mixed-Precision Bridge" works flawlessly, Tesla uses Quantization-Aware Training (QAT).
Instead of training the AI in a perfect 32-bit world and then "shrinking" it later—which typically causes the AI to become "drunk" and inaccurate—Tesla trains the model from day one to expect 8-bit limitations.
They simulate the rounding errors and "noise" of the hardware during the training phase, creating a neural network that is "pre-hardened". It’s like a pilot training in a flight simulator that perfectly mimics a storm; when they actually hit the real weather in the real world, the AI doesn’t "drift" or become inaccurate because it was born in that environment.
This extreme optimization opens the door to running Tesla's AI on devices far smaller than a car.
🚀 The strategic roadmap: from AI5 to ubiquitous edge AI
This patent is not just a "nice-to-have" optimization; it is the mathematical prerequisite for Tesla’s entire hardware roadmap. Without this "Mixed-Precision Bridge", the thermal and power equations for next-generation autonomy simply do not work.
It starts by unlocking the AI5 chip, which is projected to be 40x more powerful than current hardware. Raw power is useless if memory bandwidth acts as a bottleneck.
By compressing 32-bit rotational data into dense, log-space 8-bit packets, this patent effectively quadruples the effective bandwidth, allowing the chip to utilize its massive matrix-compute arrays without stalling.
This efficiency is critical for the chip's "half-reticle" design, which reduces silicon size to maximize manufacturing yield while maintaining supercomputer-level throughput.
This efficiency is even more critical for Tesla Optimus, where it is a matter of operational survival. The robot runs on a 2.3 kWh battery (roughly 1/30th of a Model 3 pack).
Standard 32-bit GPU compute would drain this capacity in under 4 hours, consuming 500W+ just for "thinking".
By offloading complex RoPE math to this hybrid logic, Tesla slashes the compute power budget to under 100W. This solves the "thermal wall", ensuring the robot can maintain balance and awareness for a full 8-hour work shift without overheating.
This stability directly enables the shift to End-to-End Neural Networks. The "Rotation Matrix" correction described in the patent prevents the mathematical "drift" that usually plagues long-context tracking.
This ensures that a stop sign seen 30 seconds ago remains "pinned" to its correct 3D coordinate in the World Model, rather than floating away due to rounding errors.
Finally, baking this math into the silicon secures Tesla's strategic independence. It decouples the company from NVIDIA’s CUDA ecosystem and enables a Dual-Foundry Strategy with both Samsung and TSMC to mitigate supply chain risks.
This creates a deliberate "oversupply" of compute, potentially turning its idle fleet and unsold chips into a distributed inference cloud that rivals AWS in efficiency.
But the roadmap goes further. Because this mixed-precision architecture slashes power consumption by orders of magnitude, it creates a blueprint for "Tesla AI on everything".
It opens the door to porting world-class vision models to hardware as small as a smart home hub or smartphone. This would allow tiny, cool-running chips to calculate 3D spatial positioning with zero latency—bringing supercomputer-level intelligence to the edge without ever sending private data to a massive cloud server.

English
...the significance of thought processes in science, stating, "What matters is the thinking process that led to the discovery of those formulas. It's sort of critical thinking, first principles, analysis, trying to understand what is true at the most fundamental level, then reasoning up from there and testing your conclusions against the most fundamental truths in any given arena."
👍👍👍
Gail Alfar@gailalfaratx
ELON MUSK ON LIFE AND PHYSICS (Oct 26, Lancaster, PA) Elon was asked, "Do you have an answer to life, the universe, and everything?" Elon's Response on Life's Answer Elon replied, "Well, the classic answer is 42, and 420 is just ten 42s!" -- This response refers to a well-known answer from Douglas Adams' The Hitchhiker's Guide to the Galaxy. Discussion on Physics Education Elon Musk discussed the importance of studying physics. He shared his advice, starting with, "I recommend studying physics, and the tools of physics, the thinking tools of physics. What matters is NOT remembering a bunch of formulas." Importance of Critical Thinking He further elaborated on the significance of thought processes in science, stating, "What matters is the thinking process that led to the discovery of those formulas. It's sort of critical thinking, first principles, analysis, trying to understand what is true at the most fundamental level, then reasoning up from there and testing your conclusions against the most fundamental truths in any given arena." Probabilistic Thinking in Physics Elon explained the probabilistic nature of physics, saying, "This is how you can figure out whether something is likely to be true or not. And I think it's good to think in terms of probabilities. So you receive information about a subject; that should change the probability of your conclusion, but not the certainty of your conclusion." He continued, "So, in Physics, you should not be 100% certain about any given prediction. Now, there are some things that are highly likely, but Physics teaches you that you've got to assign a probability to something being true, and then as you learn more information, your original conclusion may be wrong. Then you can change your mind based on the new information." Intelligence as Predictive Ability Elon discussed the nature of intelligence, offering his insight, "How you can think of intelligence is just the ability to predict the future. The right metric for intelligence is the ability to predict the future. If you can predict the future well, then you are as intelligent as you can predict the future well." He elaborated, "Because if somebody claims that this person or this AI is very intelligent... well, how good are its predictions? If its predictions are not very good, it's not very smart. So that is the key nature of intelligence. And if you are trying to decide what to do in the future, it really just comes down to predicting the future, and to predict the future, you have to think critically about the past, and constantly try to be less wrong." Final Advice Elon concluded his discussion with his final piece of advice, "So maybe that would be right up there in terms of best advice. Aspire to be less wrong." Thanks for reading. This short piece is an excerpt from my extensive articles on Elon Musk's Town Halls. You are here on X, right where the world's discussion takes place. Thanks for being part of it!
English
TechNerd รีทวีตแล้ว

The new X update not only expanded the gesture control capabilities, but also updated the visualization. Now, when you like a post, a red indicator appears on the right side of the post, when you retweet a post, a green indicator appears. I like it! 🙌🏻
English



Interesting prompts collection dataset in this GitHub.
A total of 15,140 ChatGPT prompts collected from open-source datasets, Reddit, Discord and general web.
Includes 1,405 jailbreak prompts.

English
@rohanpaul_ai I agree. I ran all the examples a couple of weeks ago. Great learning experience!
English
For a collection of advanced Retrieval-Augmented Generation (RAG) techniques this is a very resourceful repo.
Many topics are covered like
- Metadata Filtering: Apply filters based on attributes like date, source, author, or document type.
- Similarity Thresholds: Set thresholds for relevance scores to keep only the most pertinent results.
- Content Filtering: Remove results that don't match specific content criteria or essential keywords.
- Diversity Filtering: Ensure result diversity by filtering out near-duplicate entries.
- LLM-based Scoring: Use a language model to score the relevance of each retrieved chunk.
- Cross-Encoder Models: Re-encode both the query and retrieved documents jointly for similarity scoring.
- Metadata-enhanced Ranking: Incorporate metadata into the scoring process for more nuanced ranking.

English
@stephen_wolfram, @coecke, @ConexusAI, @johnbaez09,
Interested in your thoughts on this as it relates to ML, Deep Neural Networks, LLM Training, and ACT. Miles Stoudenmire presentation via YouTube at the Institute for Advanced Study about reducing the complexity for solving very complex problems, typically thought to require Quantum Computers O(N^Y) and higher-dimensional problems, to simpler problems O(N*X) using tensors via splitting and adding matrices. Thought you would be interested. Link: youtu.be/k1NuZDQ2Syk (or easily found in the Institute for Advanced Study YouTube channel).

YouTube
English
@stephen_wolfram I saw this from the Institute for Advanced Study on where Miles Stoudenmire talks about reducing the complexity for solving very complex problems, typically thought to require Quantum Computers O(N^Y), to simpler problems O(N*X) using tensors via addition. Thought you would be very interested in this and it's application to deep neural networks, complex mathematical problems and LLM training. Interested in hearing your thoughts. Link: youtu.be/k1NuZDQ2Syk (or easily found in the Institute for Advanced Study YouTube channel). @coecke - Bob, @ConexusAI - Ryan, @johnbaez09 - John
YouTube
English

Live CEOing Ep 839: Language Design in Wolfram Language [Tabular] x.com/i/broadcasts/1…
English
Dear @ditigalocean abuse support team,
The following IP address attempted to connect to my WIFI network from an IP address you own:
147.185.133.22
There is no valid purpose for this and was considered a hacking, ransomware, DDOS or other abuse attempt.
Similar attempts were made from IP addresses at 3 other major cloud providers.
Please investigate and follow-up as needed.
Sincerely,
Note: Tried to send via email, but since you have decided to refuse emails from your publicly posted abuse email address, I posted here
@ditigalocean, #DigitalOcean, $DOCN
English
@sciencewtg @skdh Would you consider talking to me about Quantum Computing. Thinking I have missed something or maybe I could help.
English

A new design plan for a scalable quantum computer has received a lot of buzz and funding recently and it could be the major breakthrough needed for a new era of computing. @skdh has a look.
youtu.be/4fx_TgvbcTA

YouTube
English
@mattturck, in path to AGI have you considered updated Expert systems like Cycorp (cyc.com) attempts at context reasoning with their higher order logic Knowledge Database, data connections and Heuristic Engines (similar to Category Theory) as a faster approach to AGI, especially within some business domains?
English

It's out! After hundreds of hours of work, excited to publish the TENTH annual MAD (Machine Learning, AI & Data) Landscape. 🔥🔥🔥
The OG of data/AI market maps is back, bigger than ever lol
+ 24 themes we're thinking about in 2024
w/ @AmanKabeer11
mattturck.com/mad2024/
English