William MacAskill@willmacaskill
Due to Claude’s Constitution and OpenAI’s model spec, more people are paying attention to the characters of the AI’s that companies are building, and the rules they follow. Should AIs be wholly obedient, or have their own ethical code? What should they refuse to help with? Should they tell you what you want to hear, or push back when you’re off base?
I think the nature of frontier AIs’ characters is among the most important features of the transition to a post-superintelligence world. In a new article with @TomDavidsonX, I explain why.
History shows the importance of individual character. Stanislav Petrov chose to ignore a false nuclear alarm when protocol demanded he report it; the world avoided nuclear armageddon that day. Churchill refused to negotiate with Hitler after the fall of France, despite some strongly pushing him to do so.
And, as capabilities improve, AI systems will become involved in almost all of the world's most important decisions: advising leaders, drafting legislation, running organisations, and researching new technologies. AI character — how honest, cooperative, and altruistic these systems are, and the hard rules they follow — will affect all of it.
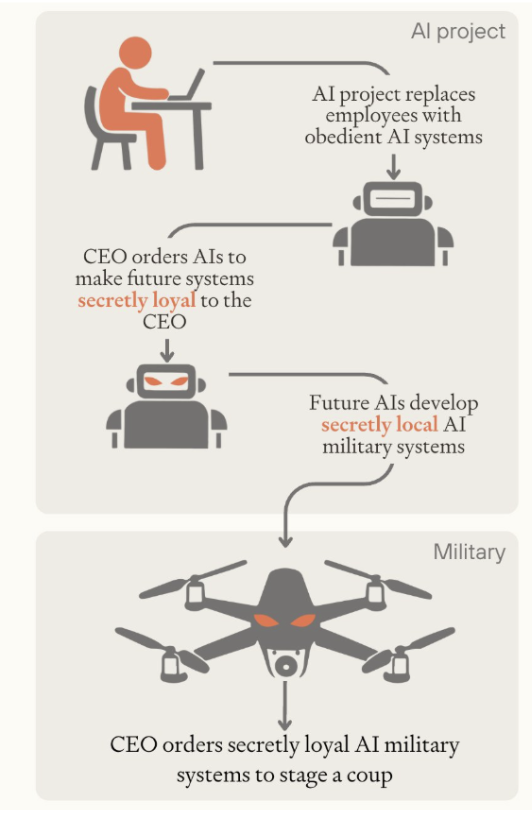
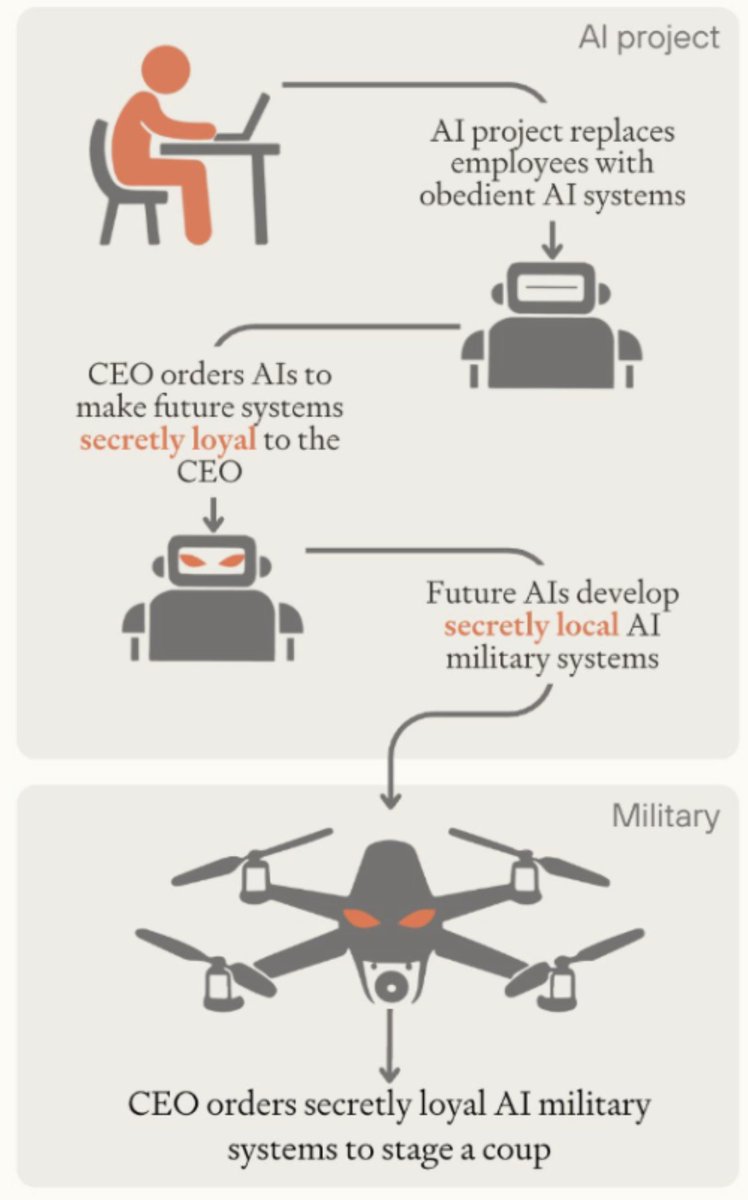
A general, aiming to stage a coup, instructs an AI to build a military unit loyal only to him. Does it comply, or refuse? Two countries are on the brink of conflict, each advised by AI systems. Do those AIs search for de-escalatory options, or are they bellicose?
The cumulative effect of AIs’ character traits across hundreds of millions of interactions, and in rare but critical moments, will have an enormous impact on the course of society.
The main counterargument to the importance of AI character is that competitive dynamics and human instructions will determine the range of AI characters we get, so there’s little we can do today to affect it one way or the other.
This is partly true, but the constraints are not binding. At the crucial moment, there might be just one leading AI company, facing none of the usual competitive pressures. Some decisions may have path-dependent outcomes, due to stickiness of training or user expectations. And there will, predictably, be many future conflicts over AI character. It’s a safer world if we work through these tradeoffs ahead of time, before a crisis forces it.
AI character is most important in worlds where alignment gets solved. But it can affect the chance of AI takeover, too. Some styles of character training may make alignment easier; and some characters are more likely to make deals rather than foment rebellion, even if they have misaligned goals.
Given how neglected the area is, too, I think work on AI character is among the most promising ways to help the intelligence explosion go well.