ทวีตที่ปักหมุด

@akshay_pachaar 0.5 GB on a light weight model is completely fixated on fine tuning to your own needs, this is what we need in the open source!
English
Dev Patel
133 posts

@_devp
21 | Member of Technical Staff @BoardyAI | Previously Founding Engineer @ https://t.co/z5tEH3dqPX , AI @Fidelity
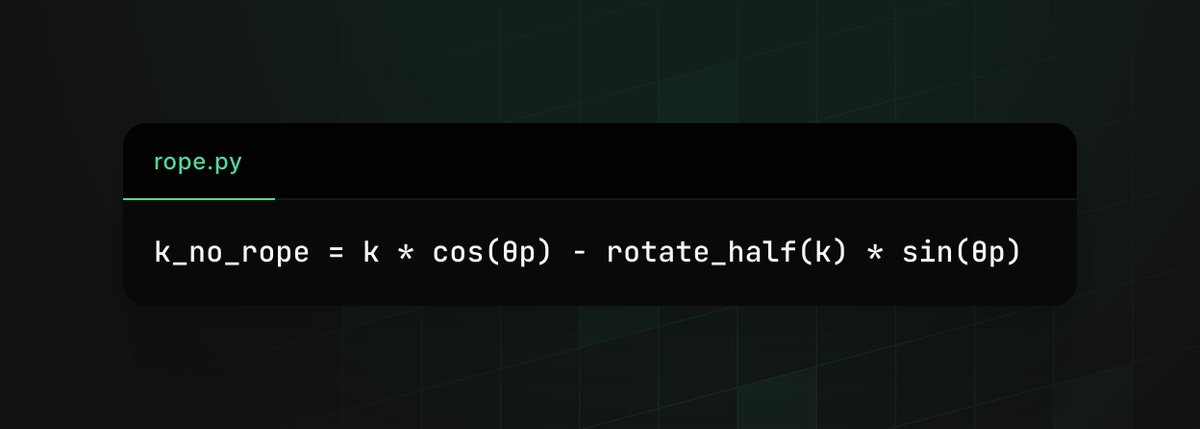
i just beat @GoogleDeepMind's turboquant introducing Shard. 10x KV cache compression on Llama-3.1-8B. zero quality loss - 10x @ 8K context, 11.2x @ 32K - NIAH recall 1.000 across 4K-32K - LongBench Δ ≈ 0 vs FP16 turboquant tops out at 4-6x at the same quality. we doubled it. read more: krishgarg.com/shard @kirrithan