Xin Yan รีทวีตแล้ว

If you are still at @iclr_conf today, please come check out our poster this afternoon at 2:30pm at DeLTa Workshop,
Poster #110
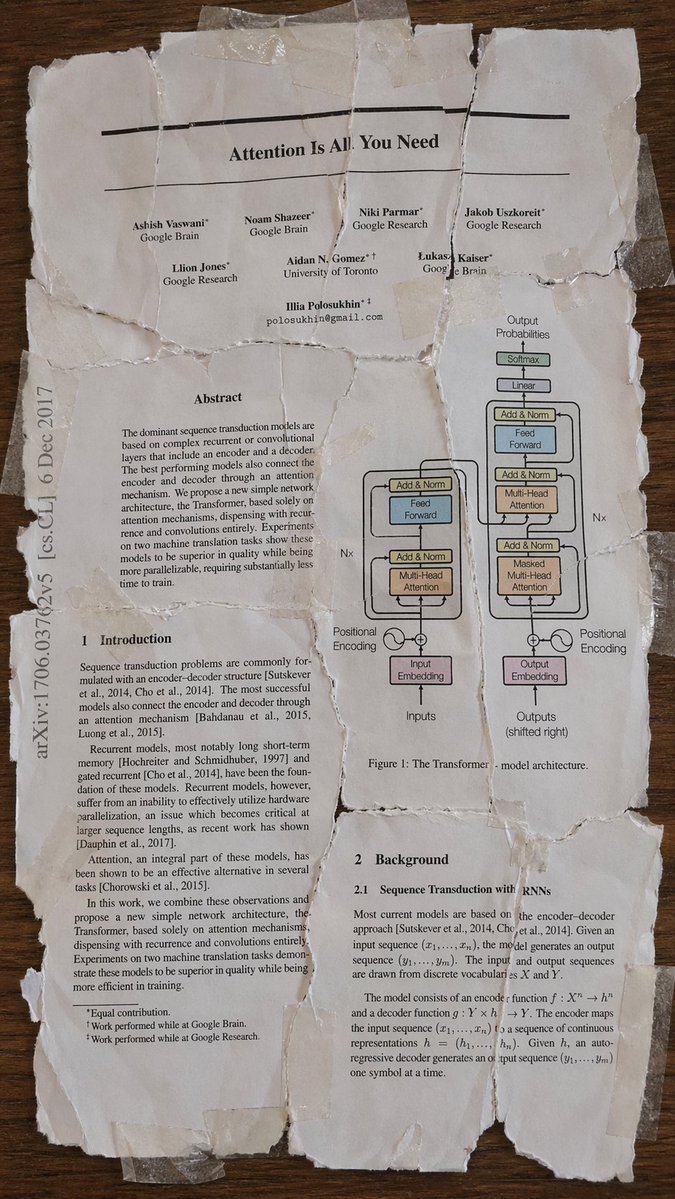
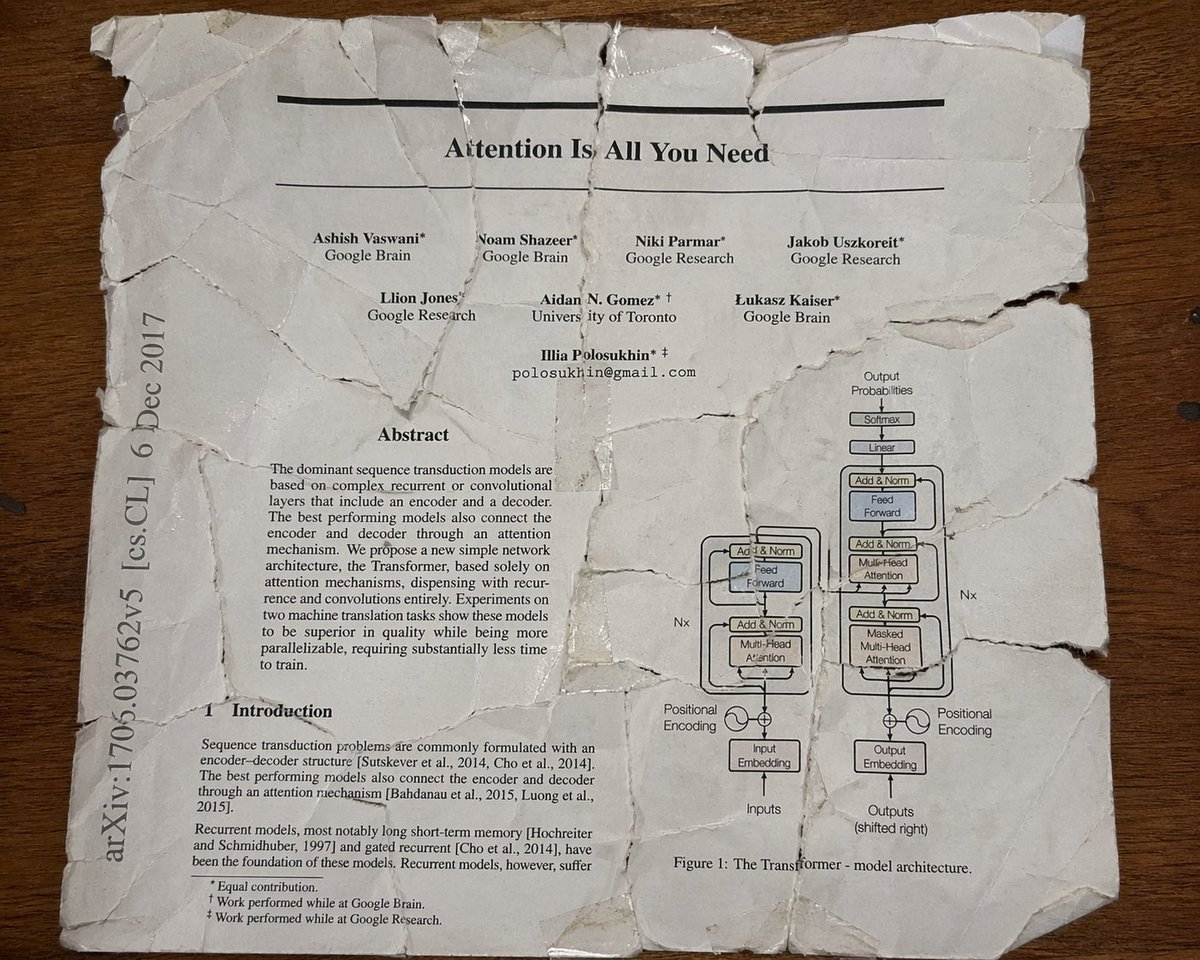
Paper: arxiv.org/abs/2604.17673
Excited to share our work on grokking in diffusion models!
We show that flow-matching diffusion models can grok modular addition and learn interpretable periodic/Fourier-like representations.
One of my favorite findings:
during sampling, the model undergoes a phase transition — early timesteps perform algorithmic reasoning, while later timesteps become visual denoising. Interestingly, this transition is clearly visible in the model’s internal Fourier structure.
This suggests diffusion models are not merely denoisers: under the right setting, they can implement structured computation along a continuous generation trajectory!
Great work by my students at @PennEngineers @hozy5333 @hagsaeng_bag and Mattis Dalsætra Østby!
GIF
Joon Hyeok Kim@hozy5333
📌 Catch our poster presentation at the ICLR 2026 DeLTa Workshop Afternoon Session Poster #110! 📄 Arxiv: arxiv.org/abs/2604.17673 Grokking of Diffusion Models: Case Study on Modular Addition
English