ทวีตที่ปักหมุด

Introducing Multi-Head LatentMoE 🚀
Turns out, making NVIDIA's LatentMoE [1] multi-head further unlocks O(1), balanced, and deterministic communication.
Our insight: Head Parallel; Move routing from before all-to-all to after. Token duplication happens locally. Always uniform, always deterministic.
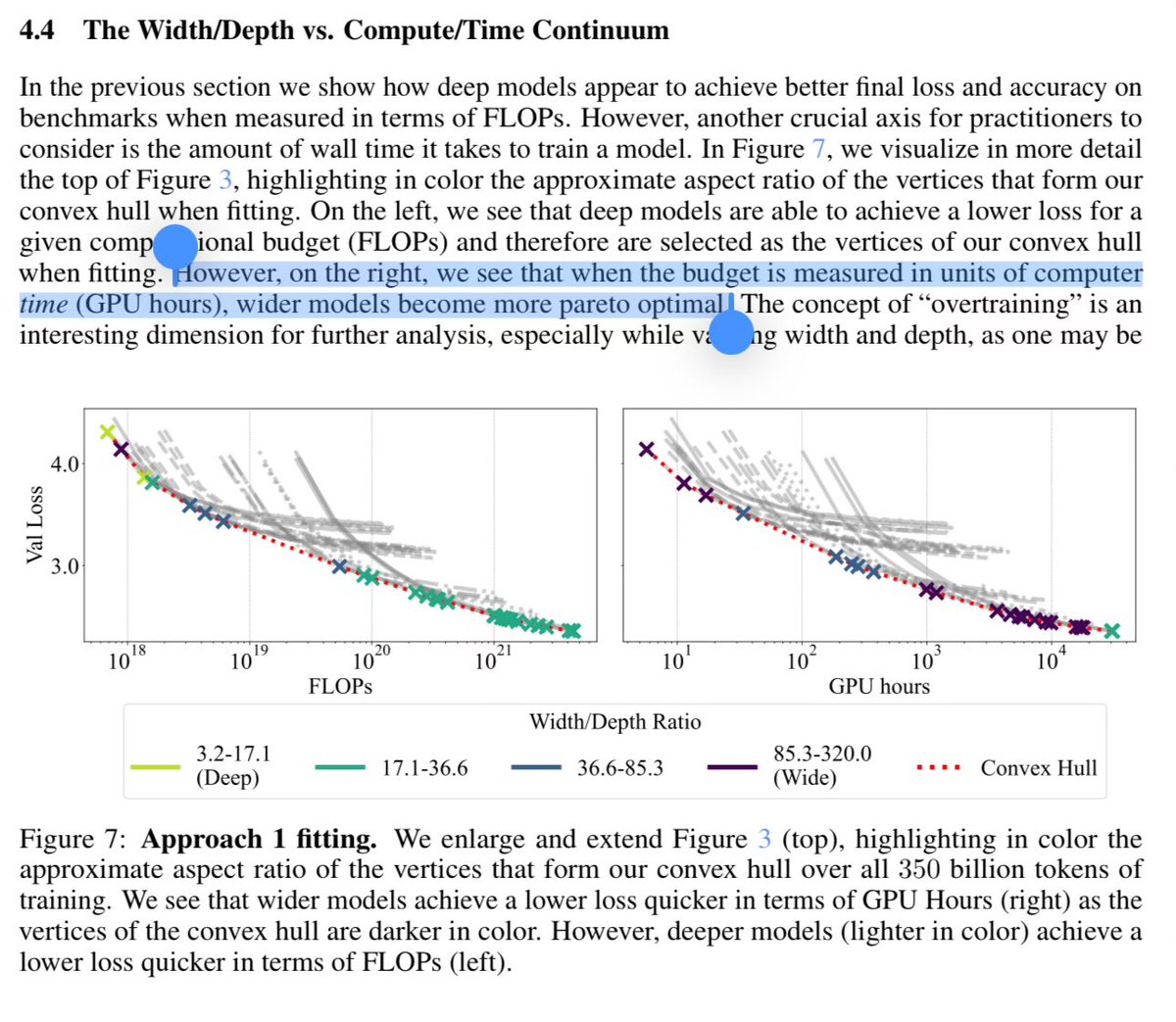
It works orthogonally to EP as a new dimension of parallelism. For example, use HP for intra-cluster all-to-all as a highway, then use EP locally.
We propose FlashAttention-like routing and expert computation, both exact, IO-aware, and constant memory. This is to handle the increased number of sub-tokens.
Results:
- We replicate LatentMoE and confirm it is indeed faster than MoE, with matching model performance. (See Design Principle IV in [1])
- Up to 1.61x faster training than MoE+EP with identical model performance.
- Higher model performance while still 1.11x faster with doubled granularity.
📄 Paper: arxiv.org/abs/2602.04870…
💻 Code: github.com/kerner-lab/Spa…
[1] Elango et al., "LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts", 2026. arxiv.org/abs/2601.18089

English