
Milan
72 posts




Look at these and read them carefully, this will give you an idea of what you can expect from different Open Weight models.
Qwen3.5-27B is the smartest
Qwen3.5-35B-3A is the fastest
huggingface.co/Qwen/Qwen3.5-2…
huggingface.co/Qwen/Qwen3.5-3…
Any Laptop, Macbook, or GPU should handle em


0xSero@0xSero
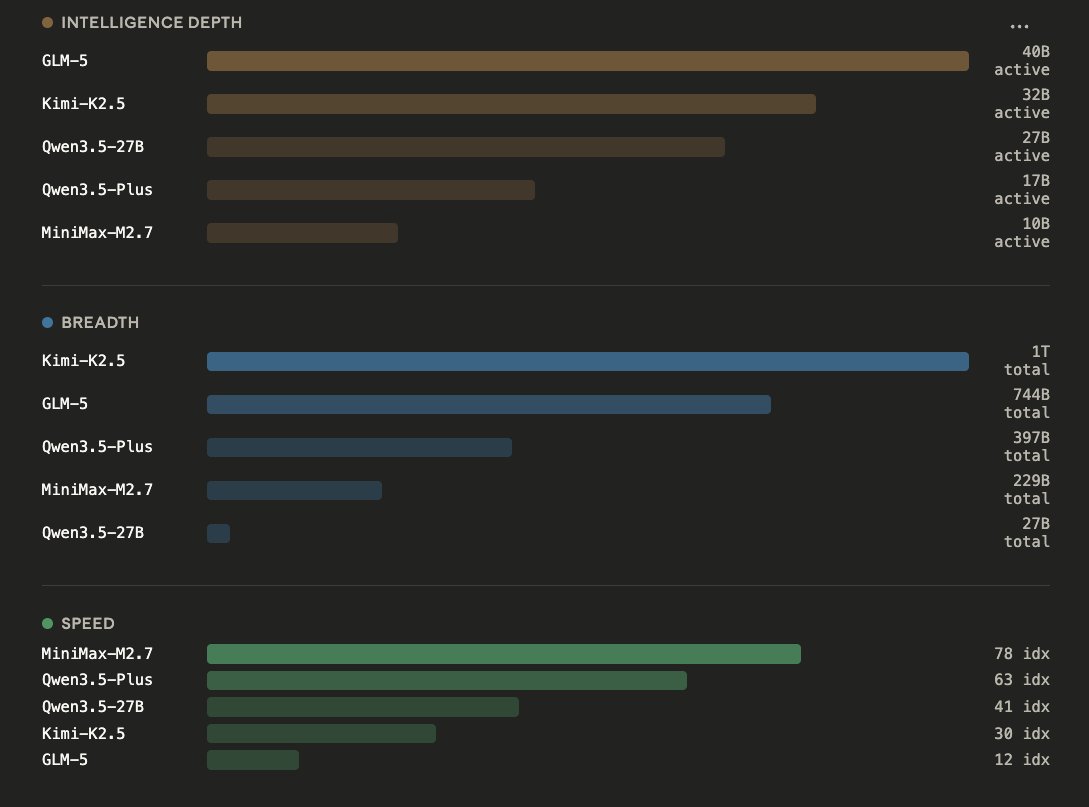
People are not lying when they say Qwen3.5-27B is incredibly capable. 1. Bubble size = total params - World Knowledge, Languages, Skills 2. X axis = active params - Raw Intelligence per token 3. Y axis = tokens/s - Speed of prefill and generation (decode) GLM-5 | 744B params | 40B active Kimi-K2.5 | 1T params | 32B active Qwen3.5-27B | 27B active params Qwen3.5-Plus | 397B params | 17B active MiniMax-M2.7 | 229B params | 10B active MoEs can store much more world knowledge, and breadth of information. For a Mixture-of-Expert, you can stack it up to 1T params, so you can give it 20 Trillion tokens or more of training data, it learns more. But during runtime, only a small portion of that gets activated. Taking MiniMax-M2.5 as an example: Only 10B are active at a time, so while you use it you get the speed and closer intelligence to nemotron-8B it's just MiniMax-M2.5 can know much more, and thus perform better.
English

@LottoLabs Qwen 27b with Hermes agent, how good at a high level? Usable?
English
Qwen 3.5 27b and Hermes Agent ran through and a/b tested some architecture changes in my small tinygrad gpt model.
I let it make the decisions fully and it ran to completion with minor steering.
Haven’t looked at the code yet, I am skeptical but if it runs on CPU it’ll run anywhere.
Obvious that larger params would have better loss/val.
Interesting times.

English
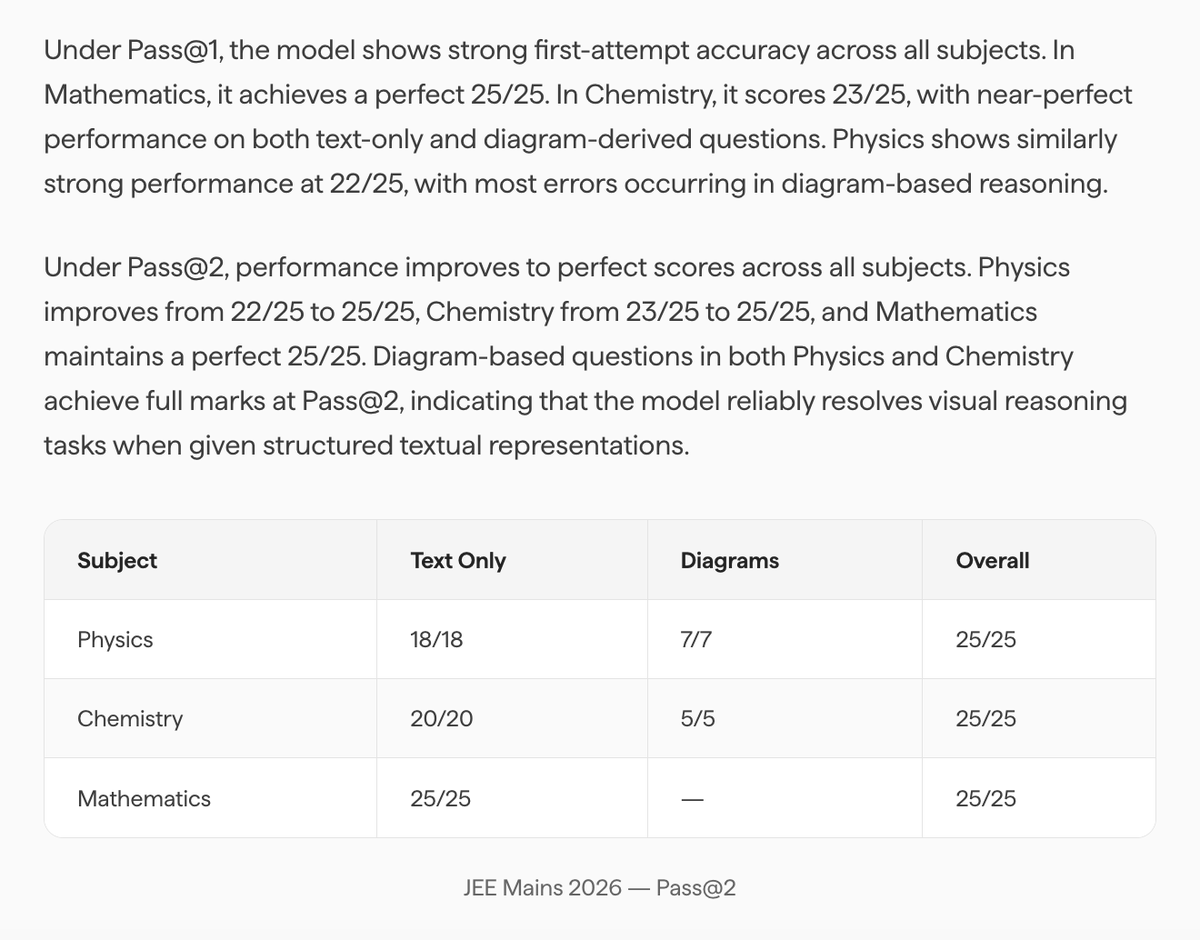


I hope M5 Ultra will be good enough to meet the hype around it 👀
English
@HarveenChadha Congratulations sardarji, very happy for you and sarvam.
English
10 months back parents were not happy when I left MS
Today when I reached, they were smiling
Dad showed me all the news channel recordings, newspapers mentions of sarvam
Mom told me how she promoted sarvam in whatsapp groups and to neighbours
Overall, a very small win but a long way to go
English

@ashen_one 512 M5 ultra would be able to run minimax and glm5 quant, so one should go and buy 512 memory for sure
English

Should you really buy a Mac Studio unless it's the maxed-out 512 GB version?
I have been talking to QWEN, a local LLM on this $4,000 98gb Mac Studio for only 2 hours, and I hate him. He's so stupid.
He's actually so slow and so dumb that my main open claw, that's running Opus 4.6, yells at him in front of me
Like, even to get a Discord message, it's taking a minute plus
Unless you have 512GB of RAM on that big fat Mac Studio, I don't think running local LLMs is a good idea. I think it's worth it to just eat the cost of any API that you're using and be able to switch to the newest APIs like Minimax or KIMIK, and not limit yourself to wasting hardware
Even though I have this 98 GB Mac Studio that costs $4,000, the local LLMs that are allowed to run on it are so dumb and slow that it makes more sense to just pay $100/month to access whatever Chinese model is better through their API
If you really want to experiment and learn and have fun, you should only really do that with the 512 GB Mac Studio so that you can run actually good and smart models compared to these slow and stupid ones
it be like that. I'm still having fun, and it was fun setting it up But this is just me publicly learning less I usually do on this account
English

A sex therapist with 30 years experience revealed the real reasons so many couples go from passionate to platonic in under 2 years.
It's not stress, kids, or age.
It's these seven dynamics shifts…
English
@ivanfioravanti @Apple Any date we have as yet, even credible rumors?
English
As soon as M5 Max and Ultra will be released I’ll buy 1 + 2. So please @Apple release them before end of March to boost your Q1 earnings 😎
English

Apple’s next powerhouse is loading… 💻⚡️
New Mac Studio could arrive after early March 2026 with:
• M5 Max & M5 Ultra options
• Faster SSD speeds
• Same compact “squircle” design
• Starting around $1,999
No redesign — just pure performance upgrades.
Are you waiting for M5 Ultra? 👀🔥

English

This Mac Studio M5 Ultra needs to drop soon.
English
@simicvm @Prince_Canuma Compared this asr with whisper, parakeet etc?
English

fully local Wispr alternative app running Qwen3 ASR 0.6B via mlx-audio-swift. practically instantaneous result in any active input field. @Prince_Canuma
English

?!?! Wtf. That is Strong! Small model. Or benchmaxxed.
Ivan Fioravanti ᯅ@ivanfioravanti
How can a 3B parameters model reach this quality? 👀
English
@TheAhmadOsman How much memory needed to run this at say q4 with full context,
English


@TheAhmadOsman Rtx 6000 pro vs 2x dgx spark, what would you suggest, equal price, run smaller models faster vs big models slow?
English

I just woke up Claude Code Agent Swarm on local Qwen3 Coder Next.
No cloud. No Internet. No quota anxiety. No 'You've hit your limit, resets 10 pm' One GB10 GPU
- 100 tokens/sec generation
- 17,871 tokens/sec read top speed
- 256k context window
- Swarm tool calling just works

English
@andimarafioti Would be great to do a comparison of available open souces asr now, we got few good ones, qwen, glm, parakeet to name few
English

This is getting crazy good. Running locally on my laptop with streaming transcriptions without compromising quality.
English