ทวีตที่ปักหมุด

Blink and you’re behind.
Here's your February AI Recap:
• DeepMind Genie 3
• Voxtral Transcribe 2
• Kling 3.0
• Opus 4.6
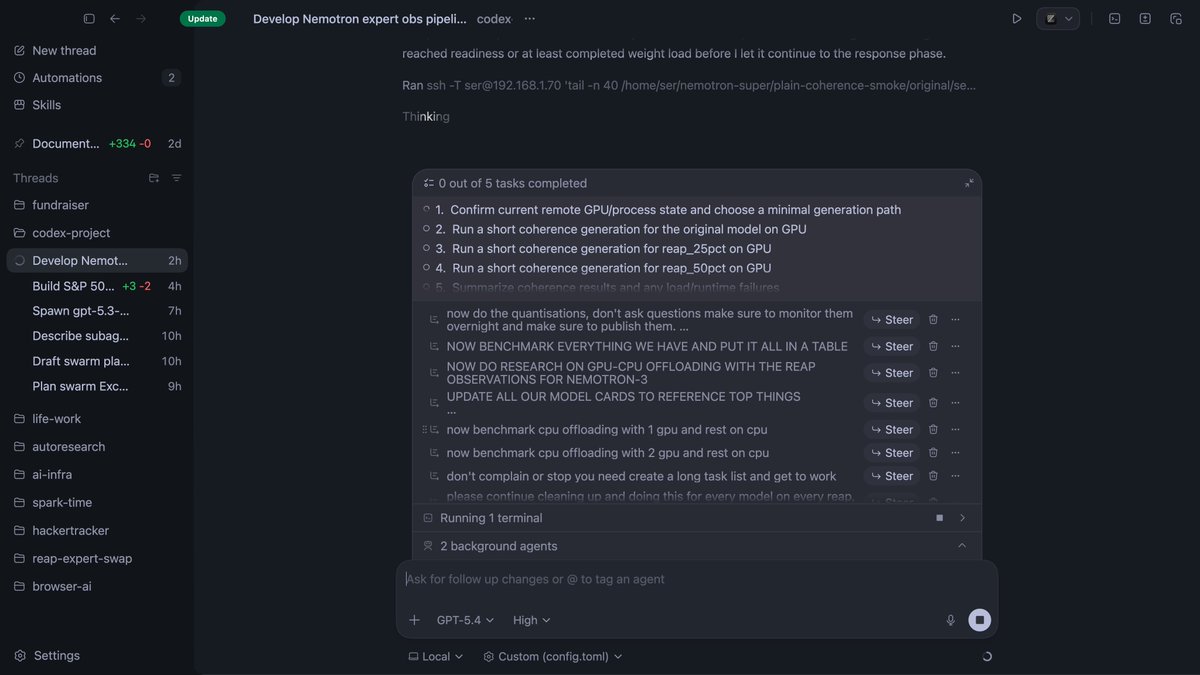
• Codex 5.3
• Recursive Language Models (RLM)
• Prompt to binary
• Context rot
• Seedance 2.0
• ElevenLabs v3 Expressive Mode
• GLM-5
• MiniMax 2.5
• Gemini 3 Deep Think
• GPT-5.3-Codex-Spark
• Claude PowerPoint
• Qwen 3.5
• Grok 4.20
• Sonnet 4.6
• Double prompt (Left to Right)
• Cursor Plugins
• Phoenix-4
• Gemini 3.1 Pro
• Taalas HC1 (17k tokens/s)
• Claude Code Security
• US-China Distillation Wars
• FDM-1
• Mercury 2
• Cursor Demos
• Claude Code Remote
• MatX One Chip
• Perplexity Computer
• QuiverAI Arrow 1.0
• Moonlake World Model
• Claude Cowork Scheduled Tasks
• Nano Banana 2
• Claude Agent Teams
• WarClaude
• France Gov Spending Data MCP
• ClaudeCode Auto-Memory
• Tzafon RL (4B)
• Apple Xcode 26.3 with Claude/Codex
• OpenAI 110B Funding round
• while True:
Cursor = "dead"
Cursor = "back"
• FactoryAI Droid Missions
• Imbue Evolver
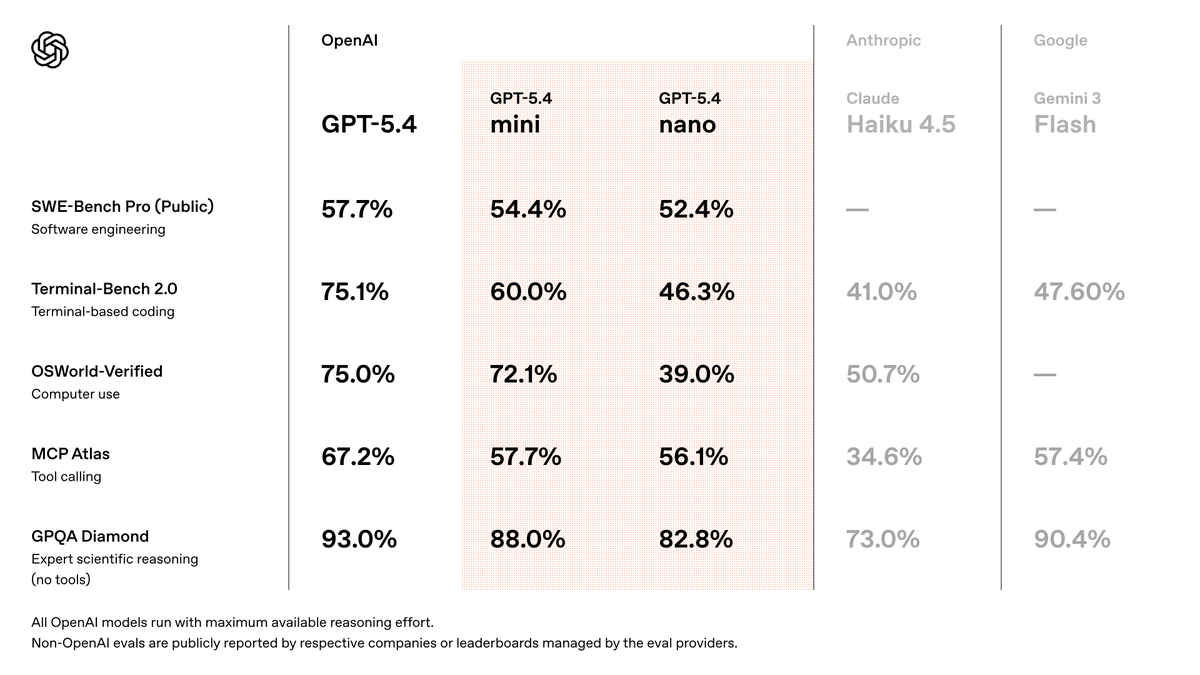
• GPT 5.4 Leak
• Anthropic - Military Disagreement
• OpenAI - Military Agreement
• Claude Import memory
• US Claude assisted Iran strikes
What did I miss?
See you in next week's recap.

English