ทวีตที่ปักหมุด
HelixDB
597 posts


HelixDB
@helixdb
An open-source graph-vector database built in Rust Star the repo ↓ https://t.co/vgOhuoImka
just use helix เข้าร่วม Mart 2025
11 กำลังติดตาม2.3K ผู้ติดตาม




@helixdb @zeddotdev @opencode @neogoose_btw bros casually the best+fastest graph db talm abt some fire😭😭😭😭BRO YOURE FIRE 🥰🙏🔥
English
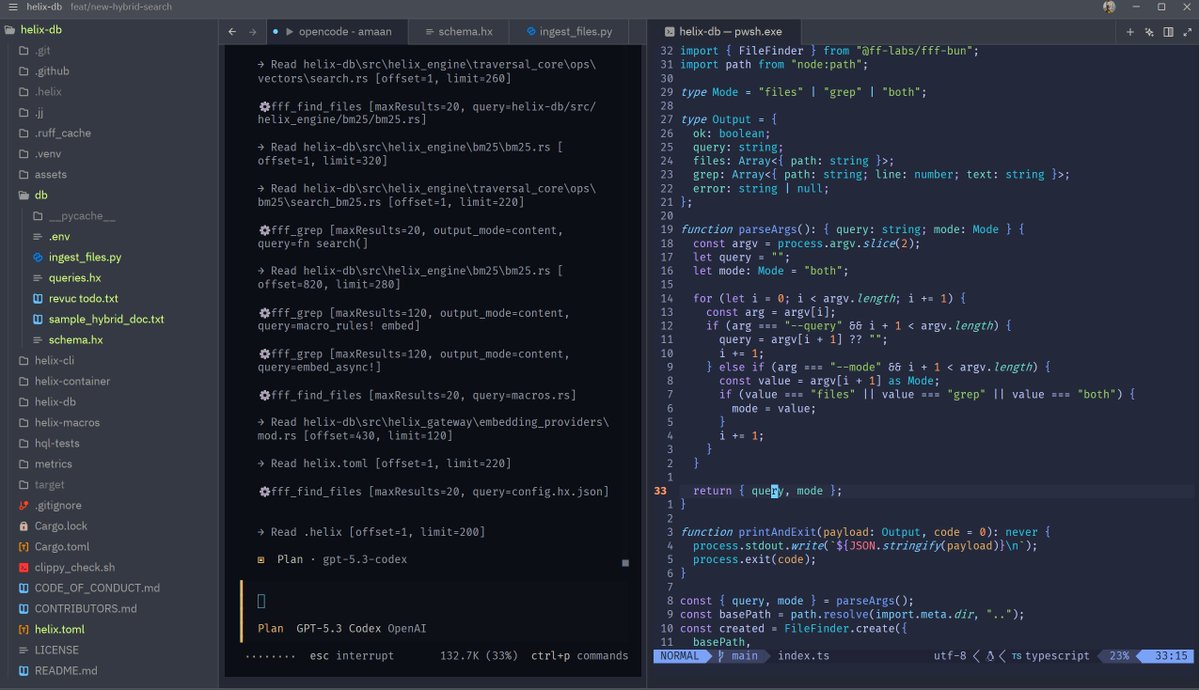
yes i need nvim inside @zeddotdev while @opencode runs as a spawned task using fff by @neogoose_btw while i add stuff to my @helixdb fork
so what?
English
HelixDB รีทวีตแล้ว
HelixDB รีทวีตแล้ว


HelixDB รีทวีตแล้ว


HelixDB รีทวีตแล้ว


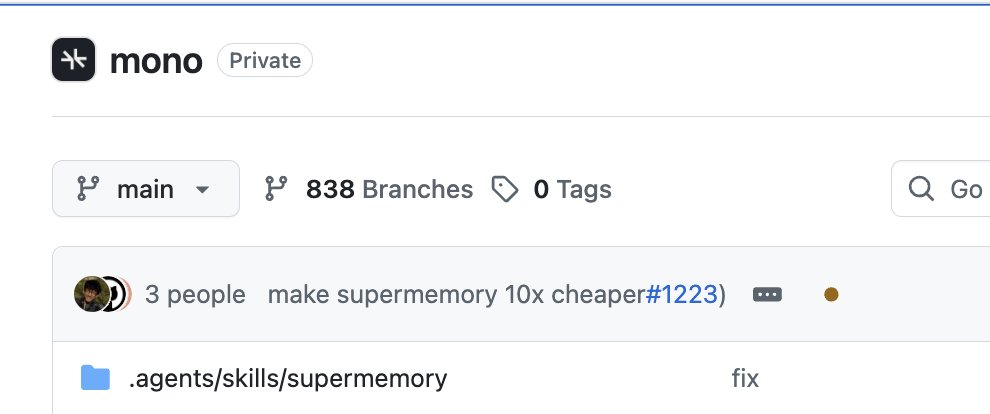
make supermemory 10x cheaper. make no mistakes.
some cool stuff coming your way
English
HelixDB รีทวีตแล้ว

I think a real big problem right now is that the fundamental data infrastructure just doesn’t exist yet to allow agents to really become mainstream outside of the sf tech bubble.
This is what we @helixdb, and others like @archildata, @airweave_ai and more are changing
English
HelixDB รีทวีตแล้ว

sooooo it’s another graph database?
just use @helixdb honestly
Nishkarsh@contextkingceo
We've raised $6.5M to kill vector databases. Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest. Similar, sure. Relevant? Almost never. Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough. A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file. Once you’re dealing with 10M+ documents, these mix-ups happen all the time. VectorDB accuracy goes to shit. We built @hydra_db for exactly this. HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time. So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit. Even when a vector DB's similarity score says 0.94. More below ⬇️
English


Knowledge graphs win every single time.
Before embeddings and similarity search, knowledge graphs were a game-changer. They are now going to win again.
Similarity is not relevance. It never was.
If you want relevant search results, you can't rely on similarity alone.
Nishkarsh@contextkingceo
We've raised $6.5M to kill vector databases. Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest. Similar, sure. Relevant? Almost never. Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough. A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file. Once you’re dealing with 10M+ documents, these mix-ups happen all the time. VectorDB accuracy goes to shit. We built @hydra_db for exactly this. HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time. So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit. Even when a vector DB's similarity score says 0.94. More below ⬇️
English
