Junlin Yang รีทวีตแล้ว

Junlin Yang
230 posts

@junlin45300
Incoming PhD @Tsinghua_Uni advised by Bowen Zhou and @stingning Research intern @haopeng_uiuc @taoyds
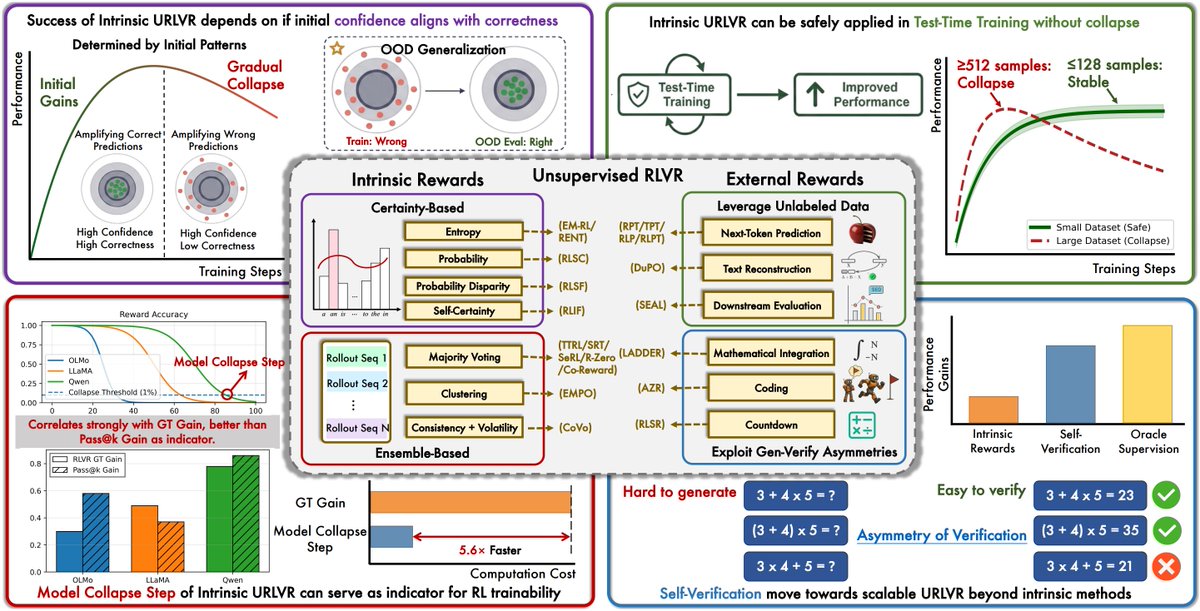
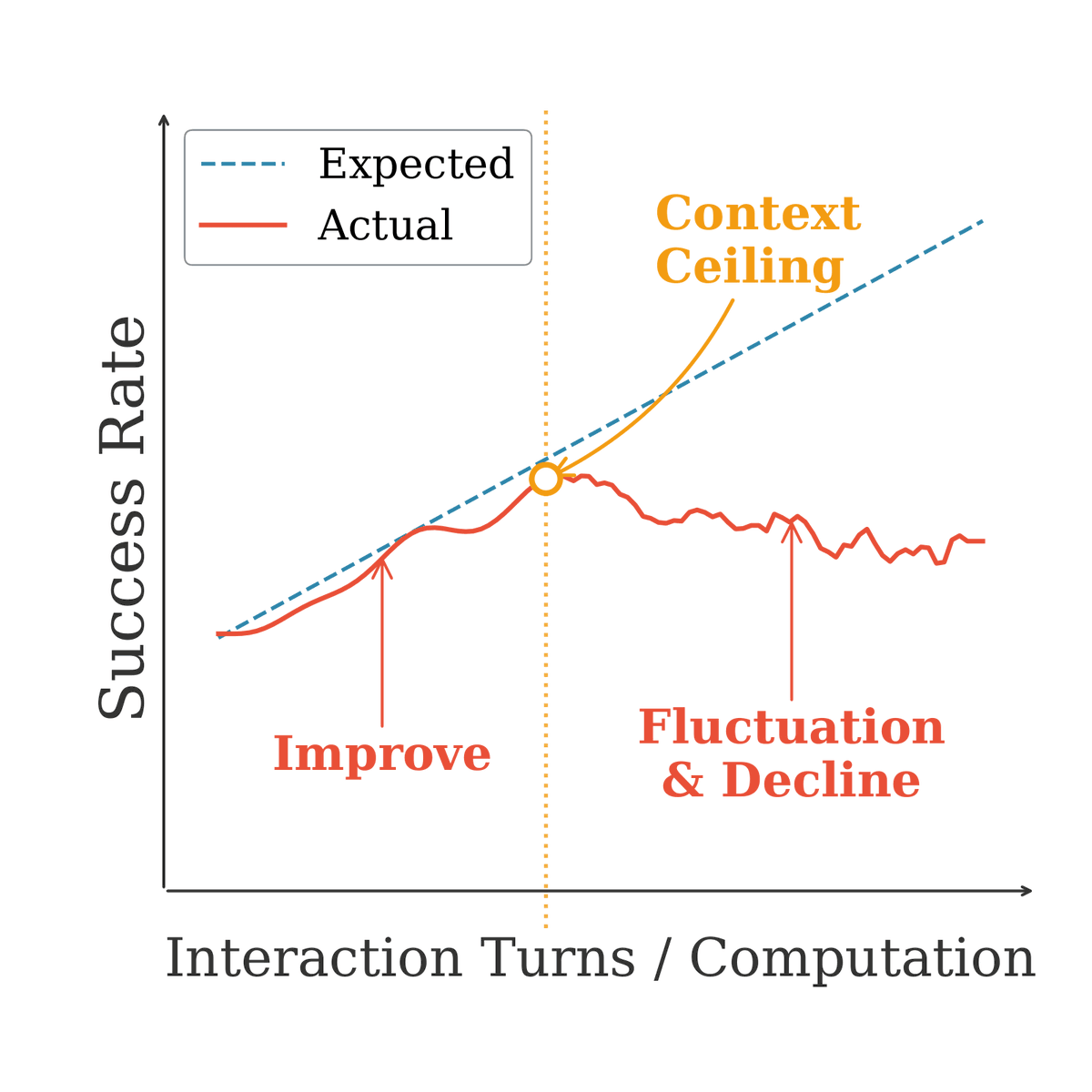
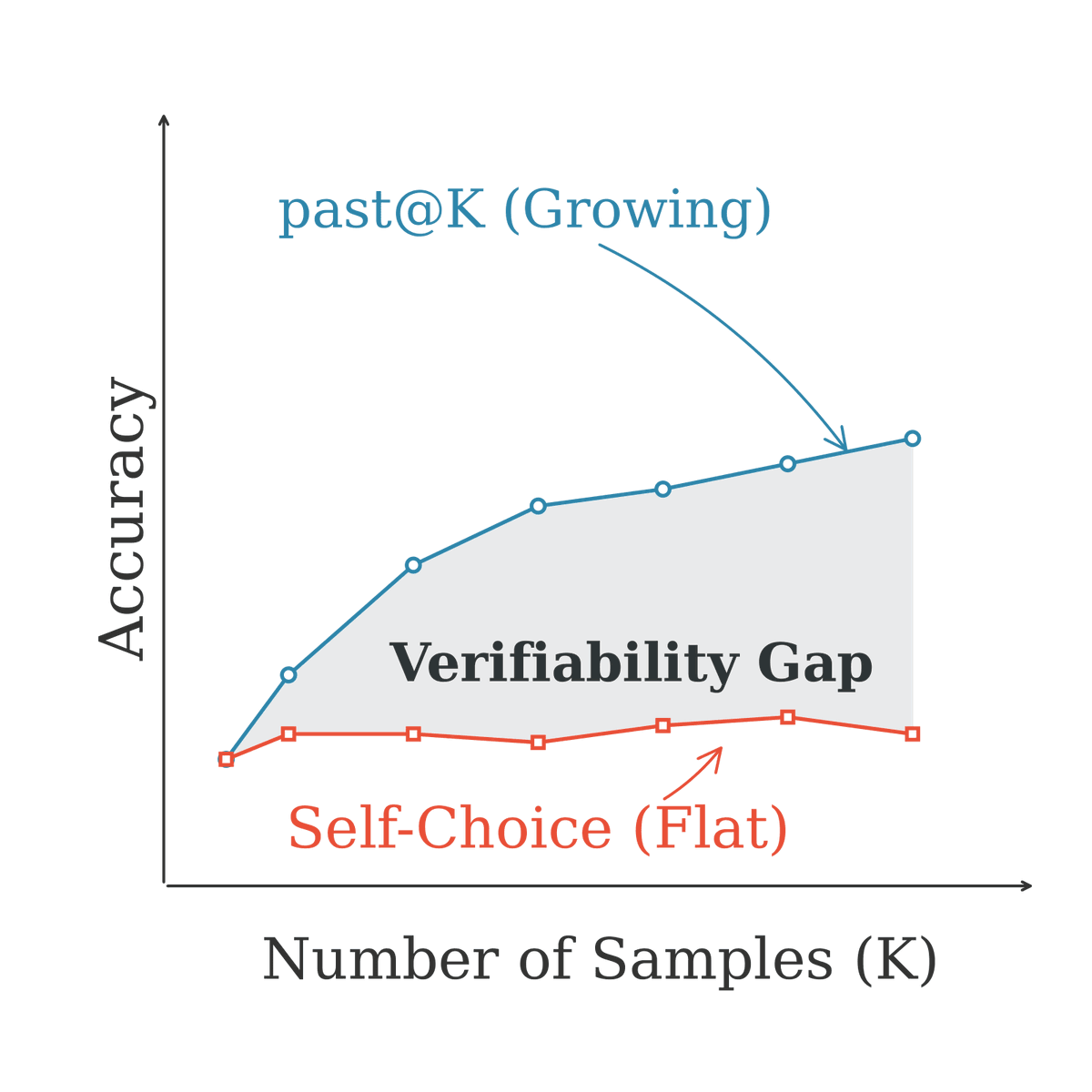
1/n ✨ Introducing our new work: Rethinking On-Policy Distillation of Large Language Models OPD is now a core technique in LLM post-training (Qwen3, MiMo, GLM-5...). But here's the uncomfortable truth: it often doesn't work. We systematically study the phenomenology, mechanism, and recipe of OPD. Here's what we discovered 👇
🍫 CocoaBench v1.0 is out! CocoaBench is a benchmark for unified digital agents, built around open-world tasks that require composing 💻 coding, 👀 vision, 🌐 search. Since our first research preview last December, we have expanded the benchmark substantially with community contributed tasks, and spent months testing and refining the tasks, evaluations, and agent runs. Some takeaways: • Even the best agent system reaches only 45.1% on CocoaBench v1.0. • Coding agents like Codex are already surprisingly strong on general tasks beyond software engineering. • Stronger agents tend to push more of the work into code. • Open source models still lag behind leading frontier models on these general tasks. 👇More on the website and in the paper #AI #Agents #LLM #Benchmark #CocoaBench


Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing

Today, we are officially opening the capability to integrate #OpenClaw into #Weixin. With the launch of the #WeixinClawBot, users can use Weixin as a dedicated messaging channel for OpenClaw. Now, you can send and receive messages with OpenClaw just like texting a friend. #AIAutomation #AI






Can’t believe I get to say this -- deeply honored to be named a 2026 Sloan Research Fellow: today.ucsd.edu/story/2026-slo… Early faculty life is… "hyper-intense": teaching, advising, hiring, papers, grants; and trying to build a lab culture you’ll still be proud of years later. There were many weeks where it felt like we were building the plane mid-flight, burning plenty of midnight oil along the way. Over the past few years, I’ve been incredibly lucky to work with amazing students and collaborators on a chain of OSS project: Vicuna → Chatbot Arena → vLLM → DistServe → LMGame → FastVideo; each one then pushed forward way further by people far beyond our lab. This award feels less like a finish line and more like fuel for the lab, for our students, and for the next set of systems we haven’t built yet. A core principle of us is building "open-source research that ships." At the same time, it’s hard not to feel a mix of excitement + uncertainty + anxiety about where CS is heading. Coding agents are improving so fast that I am feeling the AGI first-handedly. I have gone back to builder mode -- only more productive than ever -- outside of my faculty admin work. I’ve watched friends and colleagues hit numbers that would’ve sounded like science fiction a year ago (e.g., 100+ commits/day). So what does it mean to “do great computer science” when baseline productivity keeps jumping? For me, it makes “research that ships” more important, and even raises the bar. The leverage shifts toward taste and problem selection, principled system design, and translating ideas into reliable artifacts. We're excited to keep proving that through real systems people can use! Deeply grateful to: - My students and collaborators — for the ideas, execution, and drive. - @HDSIUCSD , Dean @GuptaUcsd, and my @UCSanDiego colleagues — for building an environment where ambitious work can happen. - @nvidia and @mbzuai (and other compute sponsors) — for support that helped us move faster and turn ideas into real artifacts. Even as the interface changes, the need for efficient compute and solid infrastructure only grows. Most of all: credit to the students at @haoailab. You’re the reason any of this is worth doing. Keep building and shipping!

We’ve expanded our benchmark into HiddenBench: a 65-task, theory-grounded, extensible benchmark for evaluating collective reasoning under distributed information. We tested 15 frontier models (🚨spoiler🚨: Gemini is the clear winner) and uncovered key bottlenecks in multi-agent LLMs coordination. Check out the full update on arXiv! 📄 Paper: arxiv.org/abs/2505.11556


🚀 Introducing Qwen3-Coder-Next, an open-weight LM built for coding agents & local development. What’s new: 🤖 Scaling agentic training: 800K verifiable tasks + executable envs 📈 Efficiency–Performance Tradeoff: achieves strong results on SWE-Bench Pro with 80B total params and 3B active ✨ Supports OpenClaw, Qwen Code, Claude Code, web dev, browser use, Cline, etc 🤗 Hugging Face: huggingface.co/collections/Qw… 🤖 ModelScope: modelscope.cn/collections/Qw… 📝 Blog: qwen.ai/blog?id=qwen3-… 📄 Tech report: github.com/QwenLM/Qwen3-C…