ทวีตที่ปักหมุด

Excited to be in San Diego next week for #NeurIPS2025 🎉!
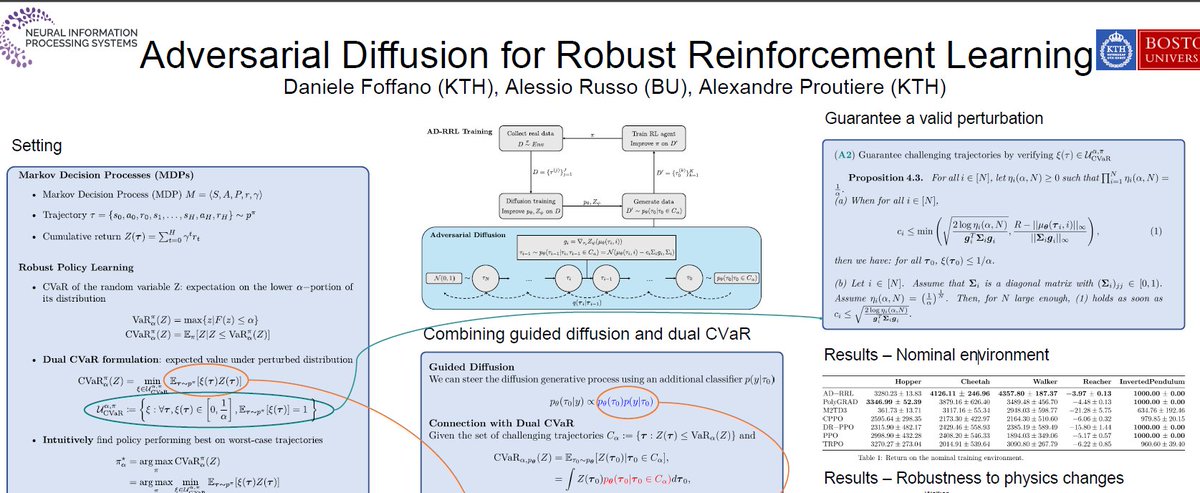
Will present Adversarial Diffusion for Robust RL together with @DanieleFoffano. Poster session on Fri 5 Dec 7:30 p.m. EST, Exhibit Hall C,D,E.
AD-RRL uses diffusion models to train Robust RL policies.
#RL #Diffusion

English