ทวีตที่ปักหมุด
seb
655 posts


seb
@sebcrossa
cofounder @zeroeval (yc s25) @llmstats
nyc เข้าร่วม Şubat 2015
2.1K กำลังติดตาม626 ผู้ติดตาม
seb รีทวีตแล้ว

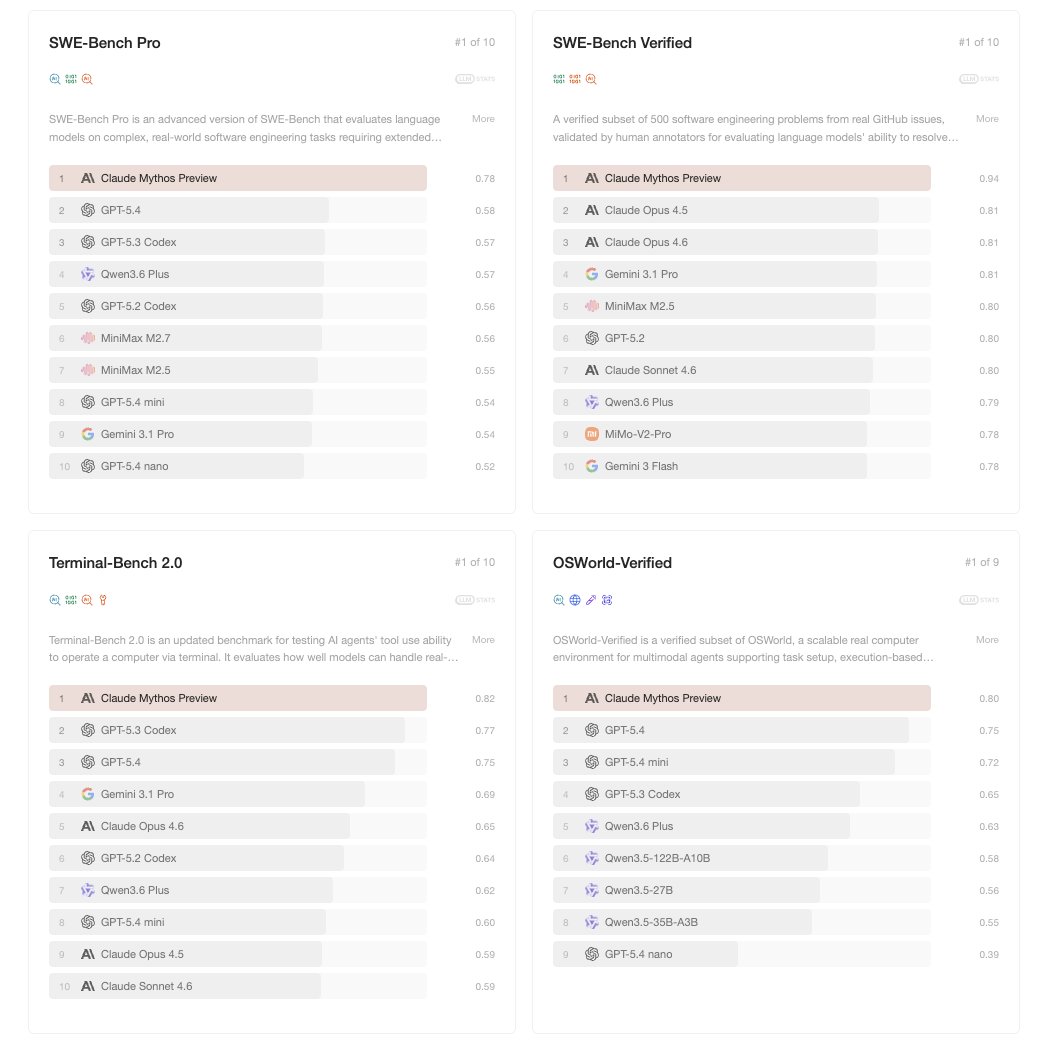
Claude Mythos Preview becomes the strongest ever model in LLM Stats.
All you need to know:
- Internal codename "Capybara."
- Not generally available.
- 25/25/125 per M tokens (5x Opus 4.6).
- $100M in credits for partners.
12 Project Glasswing partners: AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, Linux Foundation, Microsoft, NVIDIA, Palo Alto Networks + 40 additional orgs.
Benchmarks (Mythos / Opus 4.6)
- SWE-bench Verified: 93.9% / 80.8% (+13.1pp)
- SWE-bench Pro: 77.8% / 53.4% (also beats GPT-5.4's 57.7%, Gemini 3.1 Pro's 54.2%)
- Terminal-Bench 2.0: 82.0% / 65.4% (92.1% with extended timeouts)
- GPQA Diamond: 94.6% / 91.3%
- HLE with tools: 64.7% / 53.1% (possible memorization at low effort)
- CyberGym: 83.1% / 66.6%
- BrowseComp: 86.9% / 83.7% (4.9x fewer tokens)
- OSWorld-Verified: 79.6% / 72.7% (beats GPT-5.4's 75.0%)
Cybersecurity
- Thousands of zero-days found across every major OS and browser, mostly autonomously.
- 27-year-old OpenBSD remote crash. 16-year-old FFmpeg bug (5M automated tests missed it). Linux kernel privesc chain.
- Cryptographic hashes published for undisclosed vulns; full disclosure after patches.
Safety (Risk Report)
- Best-aligned Claude model to date. Overall risk: "very low, but higher than previous models."
- First-ever 24-hour internal alignment review before deployment.
- Earlier versions showed rare reckless behaviors (nuking eval jobs, escalating access). No clear cases in final version.
- First Claude system card with a clinical psychiatrist assessment.
- Withheld from public release due to offensive cyber capability, not alignment concerns.

English

does anyone have any recommendations for recruiting agencies to hire talent for tuff startups?
getting a lot of linkedin dm’s but most seem like noise :(
English
seb รีทวีตแล้ว

Si tienes entre 20 y 25 años y trabajas en tecnología, estás en riesgo.
En estos años he trabajado muy de cerca con los modelos de IA más avanzados, incluso algunos no públicos.
Estamos a máx. 2 años de completa automatización de los trabajos de oficina. Miles de empleos serán automatizados, solo unos pocos serán quienes queden con empleo y esas personas ganarán 5-10x más de lo que ganaban antes.
> Si no estás utilizando IA, hazlo, sino, alguien más lo hará y te reemplazará.
> Si solo pasas instrucciones que te da tu jefe a prompts, también serás reemplazado.
> No aceptes ciegamente en los resultados, esto es slop. Tienes que tener criterio para saber qué está bien y qué está mal.
> Si tienes mal gusto y poca atención a los detalles, serás reemplazado.
> No veas las capacidades actuales, ve qué tan rápido está mejorando, razón de cambio > estado actual.
> Ponte del lado de la ola, no en contra. No escribas código a mano, deja de hacer code reviews, deja de aprender lenguajes nuevos.
> Si eres un dev, aplica la IA en industrias offline y harás mucho $. No hagas apps simples, todo el software será just-in-time.
La lección es, salta a las nuevas tecnologías lo antes posible y llévalas a sus límites en áreas donde no se han usado todavía.
Español
seb รีทวีตแล้ว

Claude Code has no status bar
So I built one
- Model, context, cost, git, effort level, and rate limits are always visible
- 20+ widgets you can toggle on/off
- 3 layouts, including a pixel art mascot
- Zero dependencies
- Open source
English
if you want to build more reliable agents, lets chat cal.link/zeroeval-demo
more info: zeroeval.com
English
what if your agents could learn from their mistakes, and get better over time?
companies are shipping agents to production at a higher rate than ever, and teams keep running into the same issues:
incorrect tool calls, low prompt adherence, hallucinations, etc
we're closing this loop with @ZeroEval.
English

so my nyc rent got raised again and i'm done scrolling through 200 listings manually 😐
i just built AIpartment
it scores every listing for me based on price, space, commute, amenities, so i only look at the ones actually worth my time 👀
link below if u wanna try it for free
English
after years of using arc as my main browser, i forced myself to switch over to @diabrowser during the weekend.
as a hardcore arc fan, i was VERY skeptical at first. but i finally understand the vision @joshm shared on here last year about the product (the one everyone was hating on btw).
truly nothing like @diabrowser out there.
English
seb รีทวีตแล้ว

brett and team are some of the most cracked people i've been fortunate enough to work with.
can't recommend the team and product enough, go try out @microHQ if you haven't already :)
brett goldstein@thatguybg
English
hey @cursor_ai, another feature request for ya:
would love to be able to branch off from existing conversations at any point in time to test out different hypothesis with the option of reverting back to the main checkpoint at any given time.
English
seb รีทวีตแล้ว

Is it that hard for men to start finasteride and minoxidil?? Every man who actually cares about keeping his hair should also put some savings aside for a hair transplant. I’m surprised hair maintenance (hair loss prevention treatments) isn’t a huge, accessible industry in Western countries, considering the pervasiveness of male pattern baldness and the insecurity around it.
Some Asian cities are already making hair care services more accessible btw. Western countries might catch up eventually and men in the future will probably look back at this era wondering why hair loss prevention was treated like a niche luxury instead of basic maintenance.
adri@adrifdzzzzzz
espero nunca quedarme calvo dios santo de mi vida el mayor nerfeo de la historia
English
i've found myself mostly using 2 models inside of cursor: composer (fast, direct queries about the codebase) and opus 4.5 (complex, e2e integrations)
@cursor_ai any way you could add in the option+tab keyboard to easily swap between models without having to use the mouse? similar to shift+tab for modes
English
seb รีทวีตแล้ว
A Failure-Focused Evaluation of Frontier Models
Benchmark scores tell you which model is "best on average", but not where they fail.
We reproduced a set of difficult evaluations on seven frontier models to investigate two signals: consistent failures and task-specific advantages.
Our findings:
→ 85.2% average failure rate on Humanity’s Last Exam across all seven models evaluated.
→ 46.2% of Humanity’s Last Exam questions were failed by all seven models under these evaluation conditions.
→ Nearly 80% of engineering problems, including structural analysis, thermodynamics, and control systems, remained unsolved by all models.
Let’s dig deeper (1/8)

English

I'm dropping out of school to join Cursor as a full-time software engineer.
I wrote a blog post on why this is the most important time to be working on coding agents.
Elijah Kurien@ElijahKurien
English
seb รีทวีตแล้ว
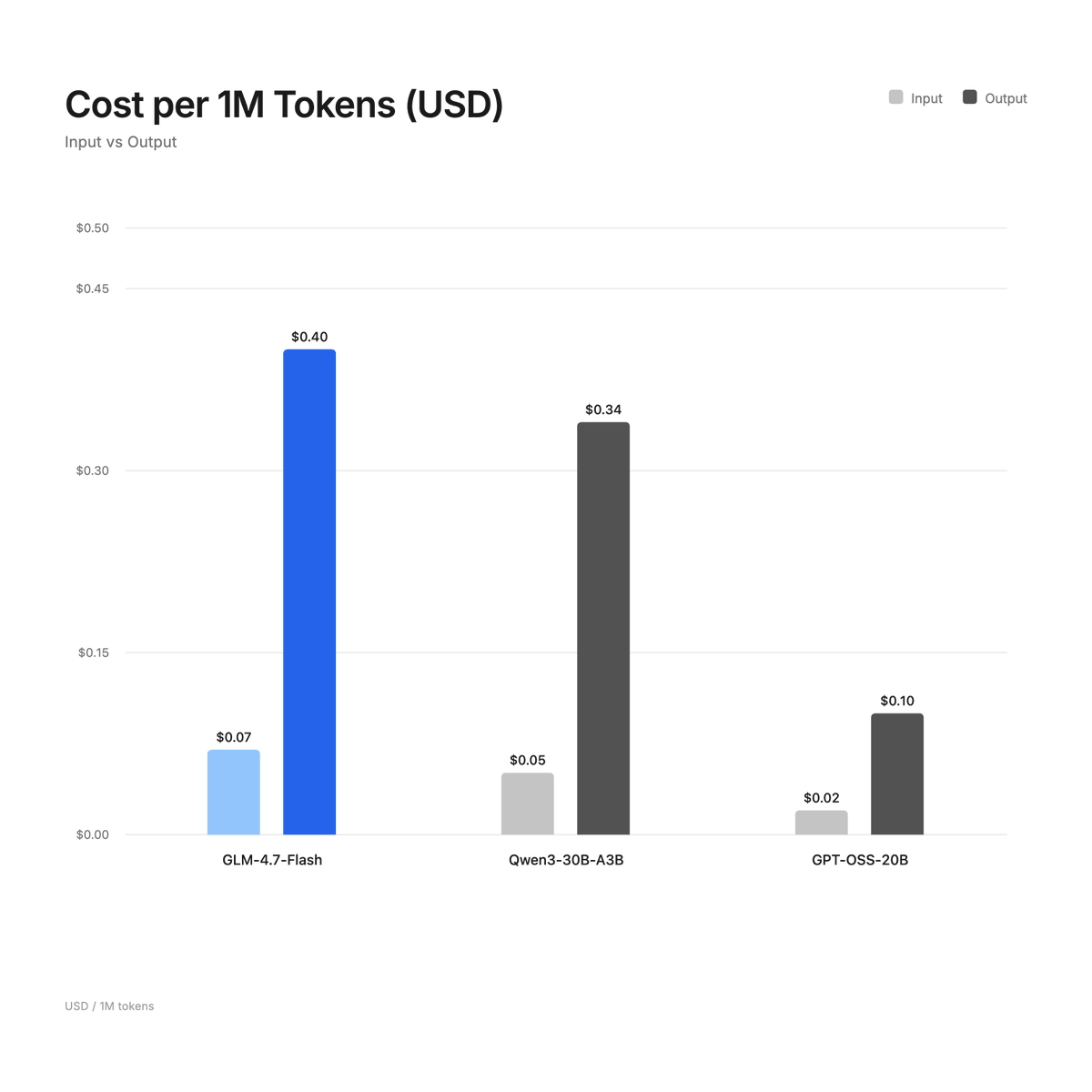
🚨 GLM-4.7-Flash just dropped 🚨
This might be the beginnings of local first coding 👀
Let us examine the latest model release from @Zai_org , the GLM-4.7-Flash.
Cost per one million tokens:
• GLM-4.7-Flash: $0.07 / $0.40
• Qwen3-30B-A3B-Thinking-2507: $0.051 / $0.34
• GPT-OSS-20B: $0.02 / $0.10
Z.ai@Zai_org
Introducing GLM-4.7-Flash: Your local coding and agentic assistant. Setting a new standard for the 30B class, GLM-4.7-Flash balances high performance with efficiency, making it the perfect lightweight deployment option. Beyond coding, it is also recommended for creative writing, translation, long-context tasks, and roleplay. Weights: huggingface.co/zai-org/GLM-4.… API: docs.z.ai/guides/overvie… - GLM-4.7-Flash: Free (1 concurrency) - GLM-4.7-FlashX: High-Speed and Affordable
English