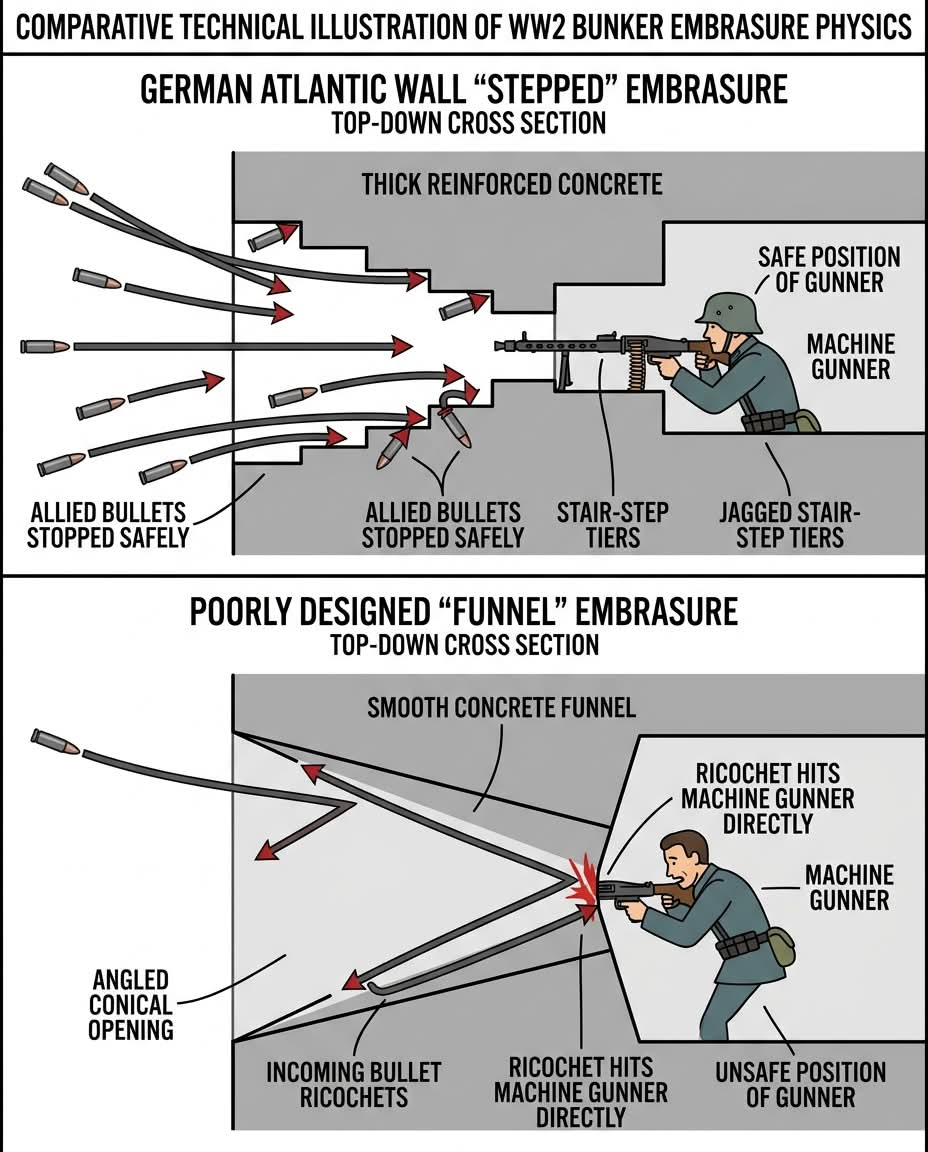
Sunny รีทวีตแล้ว

3つの異なる角度から撮影された動画では、一群の猫たちが古い井戸の周りを円を描くように一斉に動き、奇妙な儀式を行っている。
人間が撮影した映像、住宅の防犯カメラ、そしてクローズアップ映像――どの角度から見ても、これが合成やAIによるものではないことは明らかだ!
👇
日本語
Sunny
9.7K posts


@sunnypause
I build the employees that never sleep, complain, or quit. AI agents for real businesses.



Prediction We will have Claude Code + Opus 4.5 quality (not nerfed) models running locally at home on a single RTX PRO 6000 before the end of the year

You all are overthinking your app ideas. This app makes your Mac moan when you slap it -> it made $5,000 in 3 days. Just ship it.


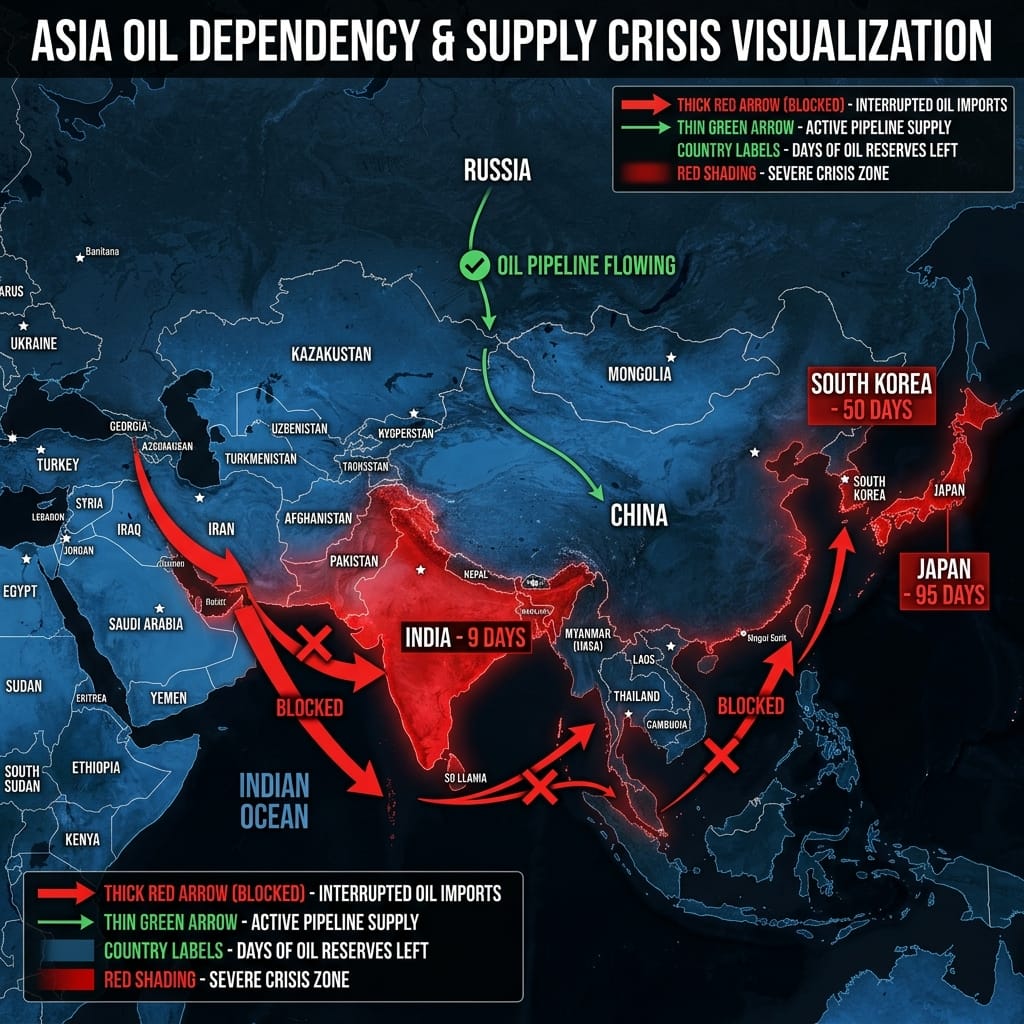










last time this qwen 3.5 MoE one shotted a full space shooter game. 3,483 lines across 10 files. ran on first load. zero steering. 112 tok/s on a single 3090. then i ran the same prompt on hermes 4.3 36B dense. similar size model, completely different architecture. it wrote 1,249 lines, declared done with empty files, needed three steering interventions, and the game didn't work. used 22% of available context and quit. nine posts and two GPU configs later the conclusion was clear: the bottleneck wasn't hardware. but that leaves a question. was that a dense architecture problem or a hermes 4.3 problem? qwen is the only family that ships both. 35B MoE with 3B active per token. and a 27B dense with all 27B active per token. same team. same training pipeline. different architecture. downloading qwen 3.5 27B dense now. Q4_K_M. same quant. same single RTX 3090. same octopus invaders prompt. if it finishes the game clean, hermes was the problem. if it fails the same way, dense architecture doesn't have the endurance for autonomous coding on consumer hardware regardless of who builds it. the tiebreaker.