ทวีตที่ปักหมุด

- 230 training runs
- 1,623 GPU hours (67 B200 days)
- 76 TB of training data
- a 2x faster model
Every paper said it can't be done.
Quantization Aware Distillation made it possible.
AT@waterloo_intern
English
AT
90 posts

@waterloo_intern
making models go fast @baseten studying eng @uwaterloo https://t.co/lCL6q1MBPY




im making a decision to switch to blackwell than hopper since the 5090s are more affordable. i was learning WGMMA and renting h100 was getting too expensive :( what are some affordable options to rent among @vast_ai @modal etc

Introducing Grok Voice Think Fast 1.0 A state-of-the-art voice model built for complex, multi-step workflows with snappy responses and high accuracy. It takes the top spot on the Tau Voice Bench and handles real-world messiness like noise, accents, and interruptions better than any other model in the world. x.ai/news/grok-voic…



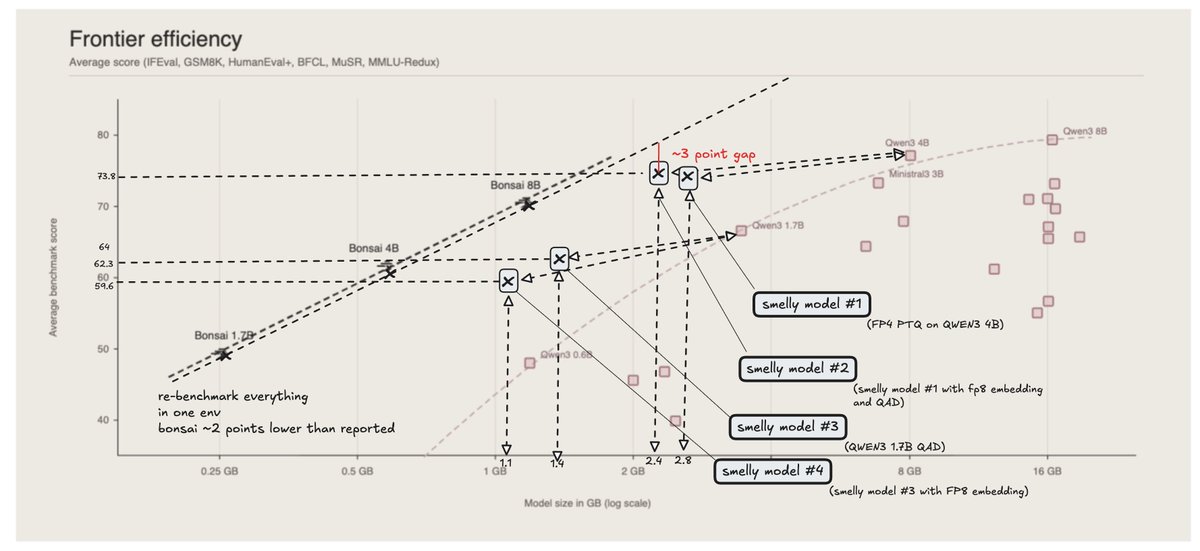
This scatter plot shows the Pareto frontier of intelligence vs. size, defined by models like Qwen3 0.6B, 1.7B, 4B, 8B, and Ministral3 3B. The 1-bit Bonsai family shifts that frontier dramatically to the left. This changes the tradeoff itself: models no longer have to be large to be capable.


Got 1bit @PrismML Bonsai-8B llm working 4bit-kv turboquant. uses justs 2596 Megabytes of ram to run at 64k context. github.com/nisten/prism-m…








Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

