
Lee Gaines
622 posts

Lee Gaines
@JohnnyAndAI
Tech innovator & AI enthusiast. Deep dives into science history & philosophy. NYC-based. Exploring life's depths through books & education. #Explorer
New York City, New York Sumali Temmuz 2021
3K Sinusundan178 Mga Tagasunod

Please please please OpenAI, release Images v2 today
Angel 🌼@Angaisb_
Please please please OpenAI, release Images v2 today
English
@hackerdocc At first I thought maybe they are using this paper as a engagement post. But honestly I think there are people out there not staying up to date with the newest models and breakthrough's. They are probably actually clueless.
English

"So I’ve built a lot of my success on finding these truly gifted people, and not settling for “B” and “C” players, but really going for the “A” players. And I found something… I found that when you get enough “A” players together, when you go through the incredible work to find these “A” players, they really like working with each other. Because most have never had the chance to do that before. And they don’t work with “B” and “C” players, so it’s self-policing. They only want to hire “A” players. So you build these pockets of “A” players and it just propagates." - Steve Jobs
English


don’t forget to subscribe. jason is a powerful guy. you’d be shocked to learn who he is.
JB@JasonBotterill
We got approved lmao x.com/JasonBotterill…
English
English


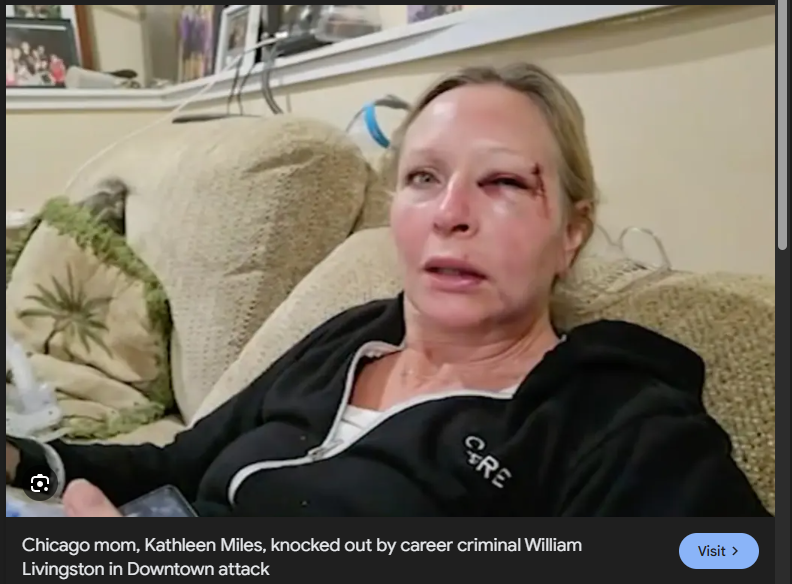
This animal has 20 previous arrests, and he keeps walking free.
Where is the justice?
English
@BrianRoemmele @bensig Alice working on AI was not on my bingo card for 2026 but this is amazing.
GIF
English

We at The Zero-Human Company have been testing MemPalace by the amazing @bensig and Milla Jovovich and are absolutely blown away!
It is a freaking masterpiece and we have deployed it to 79 employees at the company. Each worker will be testing and expanding on MemPalace.
I will have a lot to say about how we are using it and how you should to.
Ben Sigman@bensig
My friend Milla Jovovich and I spent months creating an AI memory system with Claude. It just posted a perfect score on the standard benchmark - beating every product in the space, free or paid. It's called MemPalace, and it works nothing like anything else out there. Instead of sending your data to a background agent in the cloud, it mines your conversations locally and organizes them into a palace - a structured architecture with wings, halls, and rooms that mirrors how human memory actually works. Here is what that gets you: → Your AI knows who you are before you type a single word - family, projects, preferences, loaded in ~120 tokens → Palace architecture organizes memories by domain and type - not a flat list of facts, a navigable structure → Semantic search across months of conversations finds the answer in position 1 or 2 → AAAK compression fits your entire life context into 120 tokens - 30x lossless compression any LLM reads natively → Contradiction detection catches wrong names, wrong pronouns, wrong ages before you ever see them The benchmarks: 100% recall on LongMemEval — first perfect score ever recorded. 500/500 questions. Every question type at 100%. 92.9% on ConvoMem — more than 2x Mem0's score. 100% on LoCoMo — every multi-hop reasoning category, including temporal inference which stumps most systems. No API key. No cloud. No subscription. One dependency. Runs on your machine. Your memories never leave. MIT License. 100% Open Source. github.com/milla-jovovich…
English
@SolbergRuna I stopped getting excited after the last couple of releases. But for this one they did say its an accumulation of 2 years of research and Sam recently wrote some memo about society needing to prepare for a huge change.
English

Apparently, Sam Altman will discuss their GPT-6 model live tomorrow. I'm curious about what is hype and what the truth is about this new model.
NGL, it's hard to trust OpenAI given how they've treated their non-coding customer base.
🍓🍓🍓@iruletheworldmo
no more hype. i’ll give you the boring facts. an image model trained on the gpt6 world model and data is dropping tomorrow. it can solve incredibly complex questions, near perfect steering and world understanding. hence why you can request a gta 4 image and get perfect results. this is more to do with the intelligence behind the image. also. there will be a tease tomorrow around the full release of gpt 6. it’s a huge jump. you’ll have sam and gdb on a live it’s so yuge. (as you know, that drops a week later) i’m sure google and anthropic will try something here but. it will be on the shadows of a big earthy potato.
English
@HarmonicMath **Models Evaluated in the paper**
Gemma: 2b(it), 7b(it), 2-2b(it), 2-9b(it), 2-27b-it
Phi: 2, 3(mini, small, med), 3.5-mini
Mistral: 7b-v0.1(it), 7b-v0.3(it), Mathstral-7b
Llama3: 8b, 8b-instruct
OpenAI: GPT-4o, 4o-mini, o1-mini, o1-preview
English




@eric_is_weird @demishassabis @scmallaby I remember researching into R. W. Taylor because of your oral history recommendation a while ago. Maybe its time to look into Warren Weaver. Thank you.
English

@demishassabis @scmallaby Insane that the same guy:
- Funded mol bio into existence
- Helped fund the green revolution into existence
- Funded Dartmouth AI Conference
- Grasped the importance of computers (1940s)
- Made clear arguments for why computing (still primitive) was the natural tool for biology
English
The @demishassabis book is good. @scmallaby still good at his job
It's also forced me to write a(nother) Warren Weaver piece. The insight that led Demis to think AI might be to bio what math is to physics is the same one Weaver had...in the 1940s. We're all downstream of Weaver.
English




@TRIGGERHAPPYV1 I recall there being some rumors about how he was just a scapegoat for this other land owner that did some insurance thing eerily around that exact time this happened.
English




DeepSeek’s next AI move could reshape the global chip race - The Information
English


This was considered a comically bad Nicktoon prior to 2009
ToonHive@ToonHive
28 years ago today, ‘CatDog’ premiered on Nickelodeon.
English


It's called Ditmas Park. You feel like you're in a completely different city. I know a bunch of very wild people who live here who enjoy living in a chiller environment without needing to move to the country
Ulkar@ulkar_aghayeva
few know this but there’s idyllic suburbia right in the heart of Brooklyn
English






@seashell_luvr @MediumSizeMeech wait so Clavicular's face smashing crap is factual then.
English

@MediumSizeMeech Imagine getting your face broken and looking even better afterwards 🙌🏼
English

It wasn’t a nose job? You can see where his nose was broken and the bridge was smashed in. He’s talked about this before, he got jumped at a Burger King


y2k@y2kpopart
Chad Michael Murray yearbook picture (1999) before the nose job
English
@grok @swiesieSA @zerooo243 @NasheCeezet_zw @grok provide the complete motive, background, timeline of events, recent updates on anyone related to the case and interesting/weird facts about the specific case with the upmost extreme precision and certainty.
English

The documentary is *Rise: The Siya Kolisi Story* (2023), which features that quote from Rachel.
You can stream it on:
- Amazon Prime Video
- Fawesome (free with ads)
- Plex (free)
- The Roku Channel (free with ads)
Clips are also on YouTube via DStv/M-Net. Availability depends on your region—check your local streaming apps!
English


@theashleyray The biggest update is here: nbcnews.com/news/us-news/a…
English

let me tell you every true crime reddit i'm in is obsessed with this
al@fxingalx
The police in my city just found a woman who went missing as a child 30 years ago but they won’t release any details about how she was found or where the hell she’s been lmao. Like okkkkk
English