
Mechanical Turk
80 posts


@CVPR @MechMathTurk You can find the email address here
#tab-your-consoles" target="_blank" rel="nofollow noopener">openreview.net/group?id=thecv…
English

@jm_alexia @oguzhannercan We've tried JEDi in our Mobile Video Diffusion project arxiv.org/abs/2412.07583 (see Appendix) and it indeed showed itself more aligned with the process of model pruning than FVD. Thanks for your research!
English

@oguzhannercan Our new video metric is here: github.com/oooolga/JEDi !
It's super easy to use, one line code, and its a much better metric than FVD.
English
I'm finally starting to train video-game generative models! 🎮 The data processing took a long time.
English

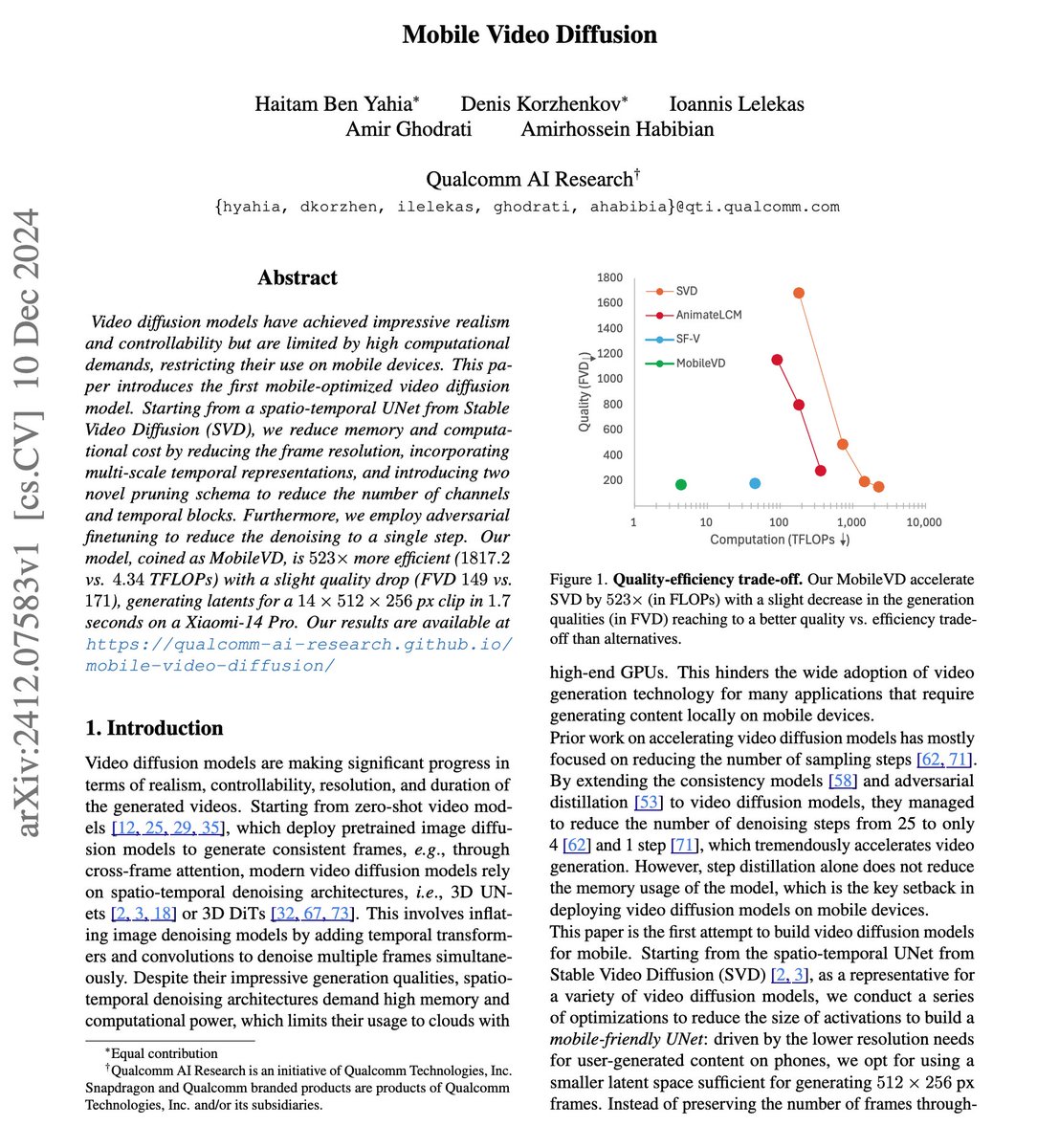
Qualcomm presents Mobile Video Diffusion. Deploys an optimized mobile-friendly UNet. Includes:
- Low resolution finetuning
- Temporal multiscaling
- Cross-attention optimization
- Temporal block pruning
...
English
@LinBin46984 Amazing work! Many thanks for sharing it with the community!
May I ask about the video generation evaluation? Has Latte-L been initialized with the same PixArt-α despite the latent space had changed? Or have pretrained weights for the UCF and SkyTimelapse datasets been used?
English

🚀🚀🚀The ultimate VideoVAE has arrived!
💥Faster, ✨ultra-efficient, and delivering performance with Wavelet Flow VAE (WFVAE).
When you're building video generation models, this is the essential component you can’t afford to miss.
Welcome aboard!🚄🚄🚄
github.com/PKU-YuanGroup/…
English
@jiang_zhengkai @_akhaliq Hey, congrats! Cool work! Do you have any plans to release the supplementary materials mentioned in the text?
English


OSV
One Step is Enough for High-Quality Image to Video Generation
discuss: huggingface.co/papers/2409.11…
Video diffusion models have shown great potential in generating high-quality videos, making them an increasingly popular focus. However, their inherent iterative nature leads to substantial computational and time costs. While efforts have been made to accelerate video diffusion by reducing inference steps (through techniques like consistency distillation) and GAN training (these approaches often fall short in either performance or training stability). In this work, we introduce a two-stage training framework that effectively combines consistency distillation with GAN training to address these challenges. Additionally, we propose a novel video discriminator design, which eliminates the need for decoding the video latents and improves the final performance. Our model is capable of producing high-quality videos in merely one-step, with the flexibility to perform multi-step refinement for further performance enhancement. Our quantitative evaluation on the OpenWebVid-1M benchmark shows that our model significantly outperforms existing methods. Notably, our 1-step performance(FVD 171.15) exceeds the 8-step performance of the consistency distillation based method, AnimateLCM (FVD 184.79), and approaches the 25-step performance of advanced Stable Video Diffusion (FVD 156.94).

English
@_akhaliq Am I missing something or have the authors indeed forgotten to include the assessment of visual results in their manuscript?
English
Qihoo-T2X
An Efficiency-Focused Diffusion Transformer via Proxy Tokens for Text-to-Any-Task
discuss: huggingface.co/papers/2409.04…
The global self-attention mechanism in diffusion transformers involves redundant computation due to the sparse and redundant nature of visual information, and the attention map of tokens within a spatial window shows significant similarity. To address this redundancy, we propose the Proxy Token Diffusion Transformer (PT-DiT), which employs sparse representative token attention (where the number of representative tokens is much smaller than the total number of tokens) to model global visual information efficiently. Specifically, in each transformer block, we randomly sample one token from each spatial-temporal window to serve as a proxy token for that region. The global semantics are captured through the self-attention of these proxy tokens and then injected into all latent tokens via cross-attention. Simultaneously, we introduce window and shift window attention to address the limitations in detail modeling caused by the sparse attention mechanism. Building on the well-designed PT-DiT, we further develop the Qihoo-T2X family, which includes a variety of models for T2I, T2V, and T2MV tasks. Experimental results show that PT-DiT achieves competitive performance while reducing the computational complexity in both image and video generation tasks (e.g., a 48% reduction compared to DiT and a 35% reduction compared to Pixart-alpha).

English
@jm_alexia To be honest, I do not really understand what the difference of the proposed CMMD vs well-known KID is (except for the different kernel used). The authors mention KID in the Related Works section but do not evaluate against it
English
Alternative to FID: MMD distance of CLIP embeddings
Meanwhile, FID is the Wasserstein-2 distance of inception features when incorrectly assuming that the features are Gaussian.
This new metric is better correlated with quality and is easily extendable to different modalities.
Tanishq Mathew Abraham, Ph.D.@iScienceLuvr
Rethinking FID: Towards a Better Evaluation Metric for Image Generation abs: arxiv.org/abs/2401.09603 This paper from Google Research proposes the use of CLIP MMD distance (CMMD) as an alternative to FID for text-to-image generation eval. CMMD does not make assumption about normality like FID does (which is anyway violated by the Inception embeddings and causes problems), it is an unbiased estimator, it is sample efficient, it better matches with expected trends (ex: distorting images reliably increased CMMD unlike with FID), and appears to better match human perception.
English

@MechMathTurk We're sorry to learn about that. Have you already checked the spam folder in your e-mail account for an answer? -Sandra
English
Hello @AmazonHelp, my Amazon DE account is currently on hold, and I cannot log in on the website/in the app. I received an email from account-resolution(AT)amazon(DOT)de and replied with the requested document, but after 4 days still haven't received any response
English
I am also on substack and publish a daily newsletter covering trending ai research papers and more: akhaliq.substack.com
English
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
paper page: huggingface.co/papers/2305.10…
English
@k_struminsky try COLMAP instead, it has a simple GUI in addition to the powerful CLI, and you can play with different settings incl. camera models to obtain the most visually pleasant point cloud
English

So I divided the photo into multiple patches and generated depth maps for each patch individually. The tricky part was to stitch the depth estimates over multiple overlapping views. Depth maps were neither calibrated nor consistent.



English
With all the fuss around neural fields and multi-view reconstruction, I wondered how I could reconstruct a scene from a single photo.
English
@AxSauer @sedielem @jacoblee628 What do you mean by local batches? Is it just data that is processed on the particular GPU? You seem to reject the specific kind of "minibatch discrimination" that was employed in the StyleGAN2 discriminator, am I right?
English

@sedielem @jacoblee628 you don't have to worry at all, we use a special variant of BN without running stats or affine params, and compute stats on local "virtual" batches. This way, we get rid of test time weirdness and the need for syncing gradients during training.
English

Batch normalisation appears to be falling out of favour (probably for the best IMO, so many bugs end up being batchnorm bugs😬).
One area where it persists is GAN discriminators (e.g. in StyleGAN-T and VQGAN). Are there any other settings where batchnorm is still hard to avoid?
English
@Rafael_L_Spring Thx for the notes! For forward-view scenes, there's a great alternative, unfortunately underhyped: generalizable multi-layer models like augmentedperception.github.io/deepviewvideo/ or samsunglabs.github.io/MLI/
English

edge device.
And that's a wrap!
I hope you enjoyed my engineer's deep dive through today's NeRF challenges and developments.
If you are interested in 3D computer vision and graphics topics, please consider giving me a follow.
Much❤️
#NeRF
English
NeRFs are getting attention these days!
However widespread adoption is still slow. But why?
It comes down to a) file size and b) rendering.
An engineer's viewpoint:
TLDR: NeRFs are fundamentally a bad fit for today's edge device architectures.
Let's explain that in detail:
1/
English
@fhuszar AFAIK @SciHiveOrg tried to do the same, however, it hasn't become popular for some reason
English

Wow, this is very cool. Too early to say how useful this will prove, but I will definitely run some tests in my reading group course.
explainpaper.com
English
Mechanical Turk nag-retweet

📢📢 Multi-shot view synthesis from our group. We extend our previous StereoLayers for an arbitrary number of input images with blazing fast inference and high quality. Look at SIMPLI interactive demo samsunglabs.github.io/MLI/
Seconds for a new scene and rendering in a browser💥
GIF
English
Hi @wacv_official, how can I get the assigned start page number for the latex template?
English
@john_pryan Could you write down a precise math model for this kind of reasoning?
English

@MechMathTurk A different way to view the sampling is that we sample from our prior of where the light comes from along the ray (either sigma and or a uniform), then we reweigh (using whatever sampling algorithm we want) by the exponential term.
English
@john_pryan However, AFAIK, there's no similar equation for E[f(X)] with a flavor of LOTUS. Therefore, you cannot use just a survival function to compute the expectation.
English
@john_pryan if you throw away the sigma multiplier, the equation is no longer a valid expression for the expected value of r.v. The confusion may come from an alternative equation for an expectation of a non-negative r.v. E[X] = \int P(X > t) dt which looks similar to NeRF equation w/o sigma
English