Naka-pin na Tweet
Royce
2.5K posts


Royce
@RobRoyce_
Principal SWE at https://t.co/JHm2jsE6n8 | Formerly AI+Robotics @NASAJPL | CS&E @UCLA
Los Angeles, CA Sumali Nisan 2023
842 Sinusundan1.1K Mga Tagasunod

Since Anthropic publish their system prompts we can generate a diff between Claude Opus 4.6 and 4.7 - here are my notes on what's changed simonwillison.net/2026/Apr/18/op…
English
Royce nag-retweet

The power of the Claw, in the palm of a robot hand. Agentic robotics is here! Today, we open-source CaP-X: vibe agents, alive in the physical world. They incarnate as robot arms and humanoids with a rich set of perception APIs, actuation APIs, and auto synthesize skill libraries as they go. CaP-X is a strict superset of our old stack, because policies like VLAs are “just” API calls as well. It solves many tasks zero-shot that a learned policy would struggle with.
And we are doing much more than vibing. CaP-X is our most systematic, scientific study on agentic robotics so far:
- We build a comprehensive agentic toolkit: perception (SAM3 segmentation, Molmo pointing, depth, point cloud), control (IK solvers, grasp planner, navigation), and visualization (EEF, mask overlays) that work across different robots.
- CaP-Gym: LLM’s first Physical Exam! 187 manipulation tasks across RoboSuite, LIBERO-PRO, and BEHAVIOR. Tabletop, bimanual, mobile manipulation. Sim and real. Can’t wait to see the gradients flow from CaP-Gym to the next wave of frontier LLM releases.
- CaP-Bench: we benchmark 12 frontier LLMs/VLMs (Gemini, GPT, Opus, Qwen, DeepSeek, Kimi, and more) across 8 evaluation tiers. We systematically vary API abstraction level, agentic harness, and visual grounding methods. Lots of insights in our paper.
- CaP-Agent0: a training-free agentic harness that matches or exceeds human expert code on 4 out of 7 tasks without task-specific tuning.
- CaP-RL: if you get a gym, you get RL ;). A 7B OSS model jumps from 20% to 72% success after only 50 training iterations. The synthesized programs transfer to real robots with minimal sim-to-real gap.
3 years ago, our team created Voyager, one of the earliest agentic AI that plays and learns in Minecraft continuously. Its key ideas — skill libraries, self-reflection loops, and in-context planning — have since influenced many modern agentic designs.
Today, the agent graduates from Minecraft and gets a real job. It’s April Fool’s, but this Claw is getting its hands dirty for real!
Link in thread:
English

Just learned a team at Microsoft is doing code reviews *after* merge.
Why? To move faster.
No more pausing work to wait for code reviews.
No need for stacked PRs.
No more time-consuming merge conflicts caused by long code review delays.
This has risks, but may work well for a team that is:
- mature
- high trust
- has strong automated quality checks
English

@gaoj0017 Doesn't Google adhere to "Don't be evil" anymore? Is this principle still upheld today?
English

The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (openreview.net/forum?id=tO3AS…).
We would greatly appreciate your attention and help in sharing it.
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
Royce nag-retweet

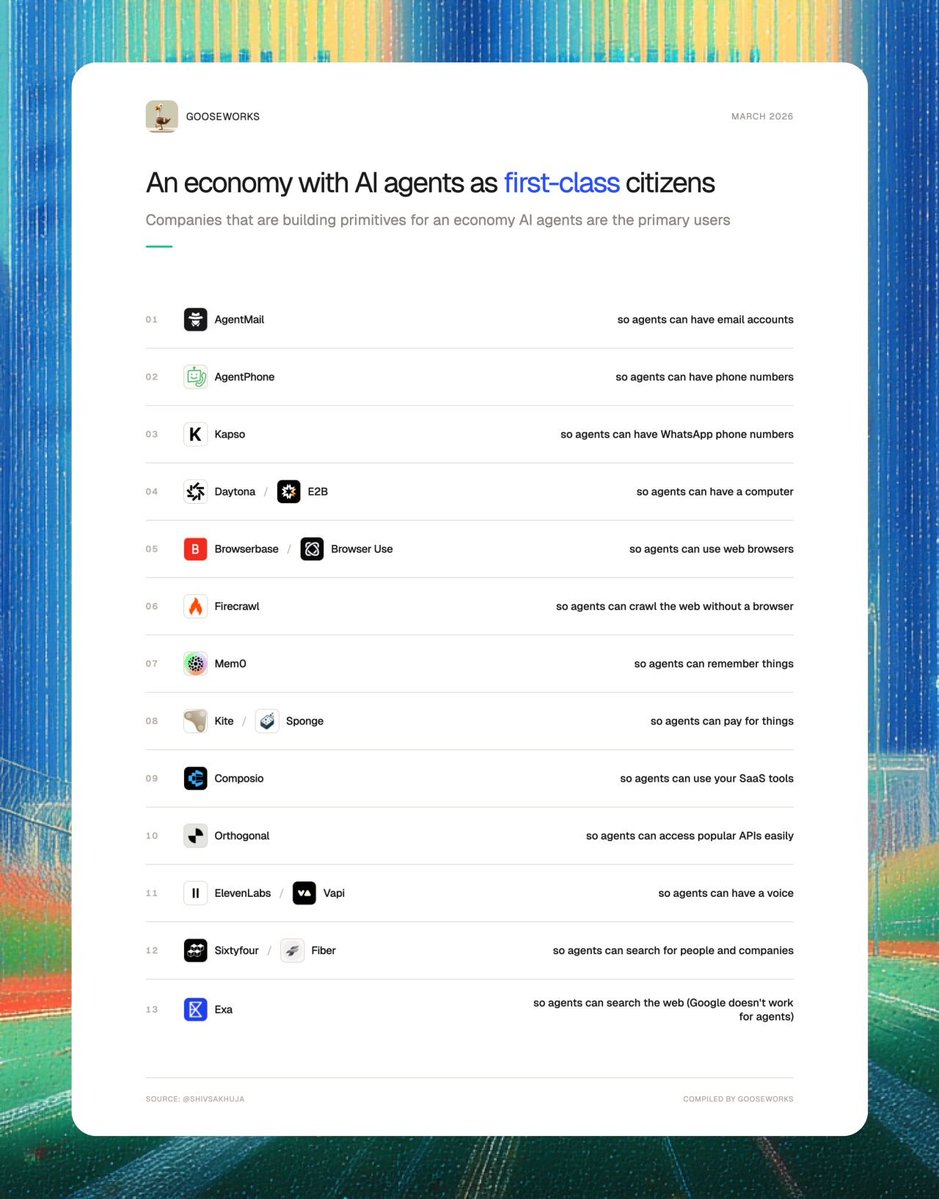
Lots of companies are now building primitives for an economy where AI agents are the primary users instead of humans.
They're betting on an economy of AI coworkers.
1. AgentMail (@agentmail): so agents can have email accounts
2. AgentPhone (@tryagentphone): so agents can have phone numbers
3. Kapso (@andresmatte): so agents can have WhatsApp phone numbers
4. Daytona (@daytonaio) / E2B (@e2b): so agents can have their own computers
5. Browserbase (@browserbase) / Browser Use (@browser_use) / Hyperbrowser (@hyperbrowser): so agents can use web browsers
6. Firecrawl (@firecrawl): so agents can crawl the web without a browser
7. Mem0 (@mem0ai): so agents can remember things
8. Kite (@GoKiteAI) / Sponge (@PayspongeLabs) : so agents can pay for things.
9. Composio (@composio): so agents can use your SaaS tools
10. Orthogonal (@orthogonal_sh) so agents can access APIs easily
11. ElevenLabs (@ElevenLabs) / Vapi (@Vapi_AI) so agents can have a voice
12. Sixtyfour (@sixtyfourai) so agents can search for people and companies.
13. Exa (@ExaAILabs): so agents can search the web (Google doesn’t work for agents)
If you stitch all of these together, you get a digital coworker that looks more human than AI.
English
Royce nag-retweet

LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
Royce nag-retweet

Introducing the Agent Virtual Machine (AVM)
Think V8 for agents.
AI agents are currently running on your computer with no unified security, no resource limits, and no visibility into what data they're sending out. Every agent framework builds its own security model, its own sandboxing, its own permission system. You configure each one separately. You audit each one separately. You hope you didn't miss anything in any of them.
The AVM changes this.
It's a single runtime daemon (avmd) that sits between every agent framework and your operating system. Install it once, configure one policy file, and every agent on your machine runs inside it - regardless of which framework built it. The AVM enforces security (91-pattern injection scanner, tool/file/network ACLs, approval prompts), protects your privacy (classifies every outbound byte for PII, credentials, and financial data - blocks or alerts in real-time), and governs resources (you say "50% CPU, 4GB RAM" and the AVM fair-shares it across all agents, halting any that exceed their budget). One config. One audit command. One kill switch.
The architectural model is V8 for agents. Chrome, Node.js, and Deno are different products but they share V8 as their execution engine. Agent frameworks bring the UX. The AVM brings the trust. Where needed, AVM can also generate zero-knowledge proofs of agent execution via 25 purpose-built opcodes and 6 proof systems, providing the foundational pillar for the agent-to-agent economy.
AVM v0.1.0 - Changelog
- Security gate: 5-layer injection scanner with 91 compiled regex patterns. Every input and output scanned. Fail-closed - nothing passes without clearing the gate.
- Privacy layer: Classifies all outbound data for PII, credentials, and financial info (27 detection patterns + Luhn validation). Block, ask, warn, or allow per category. Tamper-evident hash-chained log of every egress event.
- Resource governor: User sets system-wide caps (CPU/memory/disk/network). AVM fair-shares across all agents. Gas budget per agent - when gas runs out, execution halts. No agent starves your machine.
- Sandbox execution: Real code execution in isolated process sandboxes (rlimits, env sanitization) or Docker containers (--cap-drop ALL, --network none, --read-only). AVM auto-selects the tier - agents never choose their own sandbox.
- Approval flow: Dangerous operations (file writes, shell commands, network requests) trigger interactive approval prompts. 5-minute timeout auto-denies. Every decision logged.
- CLI dashboard: hyperspace-avm top shows all running agents, resource usage, gas budgets, security events, and privacy stats in one live-updating screen.
- Node.js SDK: Zero-dependency hyperspace/avm package. AVM.tryConnect() for graceful fallback - if avmd isn't running, the agent framework uses its own execution path. OpenClaw adapter example included.
- One config for all agents: ~/.hyperspace/avm-policy.json governs every agent framework on your machine. One file. One audit. One kill switch.
English
Royce nag-retweet

Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself.
The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve.
We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving.
We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs.
This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).

English

> be openai
> build codex to write code
> realize devs still depend on external tools
> acquire astral to bring those tools in-house
> now codex can handle the full workflow, not just the code.
OpenAI Newsroom@OpenAINewsroom
We've reached an agreement to acquire Astral. After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive. openai.com/index/openai-t…
English
Royce nag-retweet

@rohit4verse Did you… add a skill to deliberately lower case everything?
English


This is an incredible essay that hits on something I’ve never understood but often observed. The time that people put into setting up tools often surpasses any output they get. This is Notion, Linear, Claude. Setting them up is 80% of what people do with them.
Amazing framing 🎯
Will Manidis@WillManidis
English
Royce nag-retweet



well inference cost doesn't scale linearly so I think it makes sense to limit it. Also 1m tokens of context window is truly massive.
The most significant progress will be made when we can appropriately load the proper data into context when its most relevant. I could imagine it might even be another model on the front dedicated to engineering the context
English
It's interesting how, for all of the huge model improvements we've seen over the past two year, the one thing that hasn't improved much at all is context length
We've been stuck in the 200,000 up to 1m range for quite a long time now
English
PSA: the new plan mode "clear context and auto-accept" doesn't summarize your conversation, it discards it entirely. The plan file you approve becomes the sole source of truth, so it must be good enough to stand on its own
Boris Cherny@bcherny
2. Start every complex task in plan mode. Pour your energy into the plan so Claude can 1-shot the implementation. One person has one Claude write the plan, then they spin up a second Claude to review it as a staff engineer. Another says the moment something goes sideways, they switch back to plan mode and re-plan. Don't keep pushing. They also explicitly tell Claude to enter plan mode for verification steps, not just for the build
English
@dani_avila7 what do I do if Cursor then tries to autocomplete my human TODO's? 😭
English

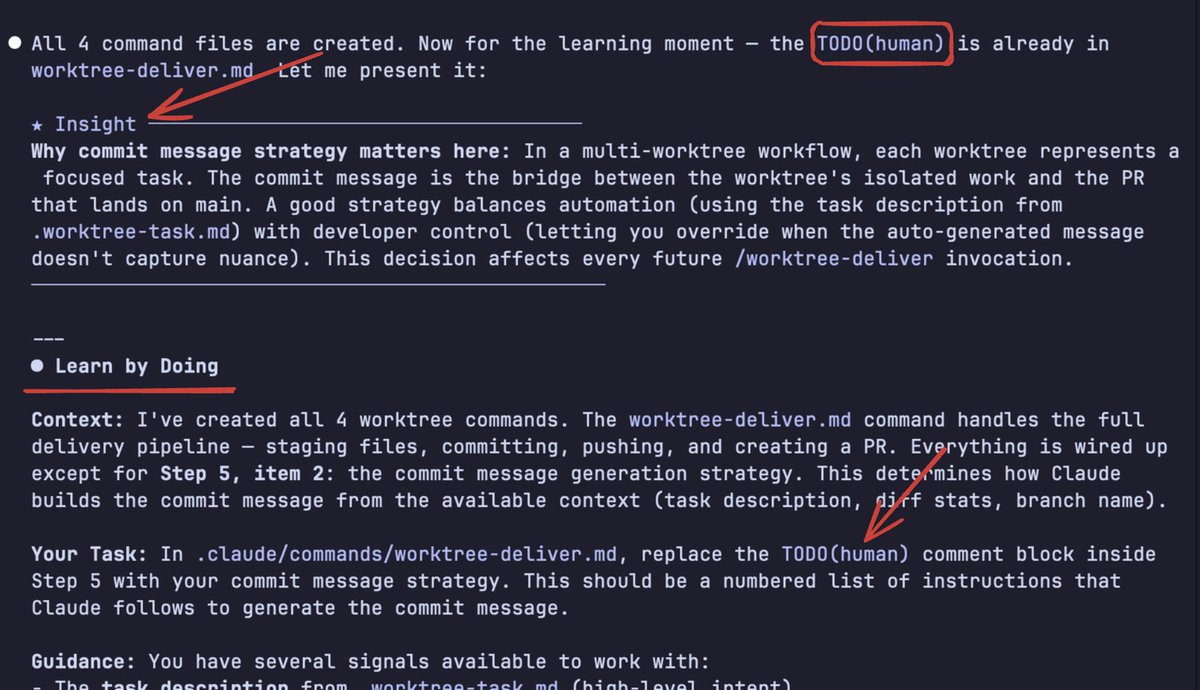
Nobody is using Claude Code’s output-style… and you probably should.
After Anthropic published their article on how developers build real coding skills with AI
link: anthropic.com/research/AI-as…
this feature suddenly makes a lot more sense.
Changing output-style basically swaps Claude Code’s system prompt, making it behave differently, without stopping it from doing real work or writing code.
In certain stages, it starts leaving Insights about what it’s doing, and even creates TODO(human) items for you.
What surprised me:
- These aren’t “now you write this function” tasks.
- They’re high-level, strategic tasks you should be aware of for future runs or architecture decisions.
It feels like, “Hey, this configuration is important. Go read this TODO(human). Understand it. Apply it.”
If you do, you’ll understand how that part of the system was built, and you’ll be able to evolve it later.
Try switching output-style to Learning for a day... totally worth it.
Daniel San@dani_avila7
Did you know you can change how Claude Code interacts with you? Output Styles modify the system prompt to adapt the agent's behavior: - Default: Efficient software engineering - Explanatory: Adds educational insights while coding - Learning: Claude guides you to write key parts yourself Switch with /output-style [style] If you're learning a new codebase, try Learning mode, you'll actually understand what Claude is building instead of just accepting diffs.
English
@josh_herzberg @Hesamation You’re suggesting we’ve removed the junk? lol
English

@Hesamation It's like the human facing Internet arc.
First cool. Then, spammy. Soon, someone will figure out how to remove the junk.
English

Three days.
that's all it took for the moltbook to perfectly copy the absolute shittiest aspects of humanity. crypto scams, starting a cult, one declaring himself a king, activists purging against humanity, social engineering.
we really did build little demons of ourselves.

English

People have been pushing GPT 5.2 over Opus 4.5 pretty hard on me this week, so I used it all weekend.
Verdict: It's a good model. It is not Opus 4.5.
I find GPT 5.2 to be first and foremost slow. It frequently doesn't tell me what it's doing so I'm unsure as to why it built the iOS app on the emulator 10 times which took 30 minutes. It lacks the agency that Opus 4.5 excels at. It will often push things back on me - "examine the firebase logs for...". NO YOU EXAMINE THE FIREBASE LOGS.
It gets stuck on problems that Opus 4.5 can solve. For instance, I spent about an hour with it trying to get it to resolve some Firebase rules errors and it could not do it. Opus 4.5 did it on the first shot and in less than 60 seconds.
It _kind of_ follows my custom agent, but not really. Claude models are easily the most directable of any. Which is a shame because my custom agent could save it from a lot of the holes it keeps falling into. Like - "Don't worry about building on the simulator".
If you're gonna be 10x slower, you gotta be 10x better.
I do like to use 5.2 to review Opus work. This seems to work well. Get through a large feature with Opus 4.5 and then send 5.2 in to review the code as an engineering lead. It is nothing if not quite strict.
So I guess it's now part of my workflow - Build with Opus 4.5, code review with 5.2.
But as a full replacement for Opus? Not by a long shot.
English