Naka-pin na Tweet
fangjun
6.7K posts

fangjun
@fjun99
I tweet about blockchain/web3 development, tools and best practices. @developer_dao @Uweb_web3
Sumali Ocak 2008
2.5K Sinusundan4.6K Mga Tagasunod

@CplusHua 0. 先说清楚担责细则
1. 给他们可以独立设备配置使用的明确路径,不按路径来,出事自行担责
2. 实在需要便捷感受就让其安装腾讯出的 QClaw,配套龙虾管家,出事自行担责
3. 配套类似我们的“OpenClaw 极简安全实践指南”(尤其配上红线部分的思想钢印)+ SlowMist Agent Security Skill
4. 回到0
中文


Anthropic 发布了最新的 Economic Index 报告。
报告中有一个很重要的发现:
使用者越早接触 AI → 越快积累经验 → 越能完成高价值任务 → 越能从 AI 中获得更多收益。
具体来说就是:
真正能高效利用 AI 的,往往是那些更早使用、经验更丰富、且更懂得与 AI 协作的人。AI 的价值释放不仅取决于模型能力,也取决于用户是否学会了“怎么用”。
从 2026 年 2 月的数据看,有几个变化很清晰:
Claude 上的使用场景更分散了,前十大任务占比从 24% 降到 19%
1. 个人和日常类问题变多了
2. 高价值的编程任务继续向 API 一侧迁移
3. Claude上任务的平均“经济价值”略有下降
这或许表明,AI 正在从早期技术用户的小范围高强度使用,走向更广泛的大众采用。
按报告所阐述的,使用至少 6 个月的高资历用户:
1. 更少把 Claude 用于个人闲聊和简单查询
2. 更常把 Claude 用在工作和更高教育门槛的任务上
3. 使用场景更广,不只集中在少数几个任务
4. 对话成功率明显更高
最后一点尤为关键:
高资历用户的成功率大约高 10%。即使控制了任务类型、国家、模型选择等因素,这个优势依然存在,仍有大约 4 个百分点。
这或许意味着,AI 的价值释放,未必主要由模型能力决定,也越来越取决于用户是否形成了有效的协作方式。
真正高水平的 AI 使用者,往往不是把任务直接丢给模型,然后等一个答案。他们更像是在做几件事:
1. 更会拆任务
2. 更会补上下文
3. 更会追问和迭代
4. 更会校正输出
5. 更会把不同模型匹配到不同任务
下面这个发现就更反直觉,特别是与最近很火的AI自动化有明显出入。
1. 更有经验的用户,并没有更倾向“全自动化”;相反,他们更倾向于和 AI 协作。
2. AI 的成熟使用方式,可能不是“把人拿掉”,而是“让人和模型形成更高效的工作流”。
3. 谁更早学会这种工作流,谁就更早获得复利。
对于做AI产品的一些启发:
1. 下一阶段,真正重要的竞争点,可能不只是模型更强,而是谁能更快帮助用户跨过学习曲线。
2. 如果一个 AI 产品不能帮助普通用户迅速学会如何提问、如何拆解任务、如何迭代结果,那它就很难稳定释放价值。
3. 模型在进步,用户也在进化,而最终决定 AI 价值分布的,可能是两者之间的配合效率。
4. 未来 AI 带来的分化,可能不只是“谁先接入了 AI”,而是“谁先学会了与 AI 一起工作”。
Anthropic@AnthropicAI
New from the Anthropic Economic Index: how people’s use of Claude changes with experience. Longer-term users are more likely to iterate carefully with Claude, and less likely to hand it full autonomy. They attempt higher-value tasks, and receive more successful responses.
中文

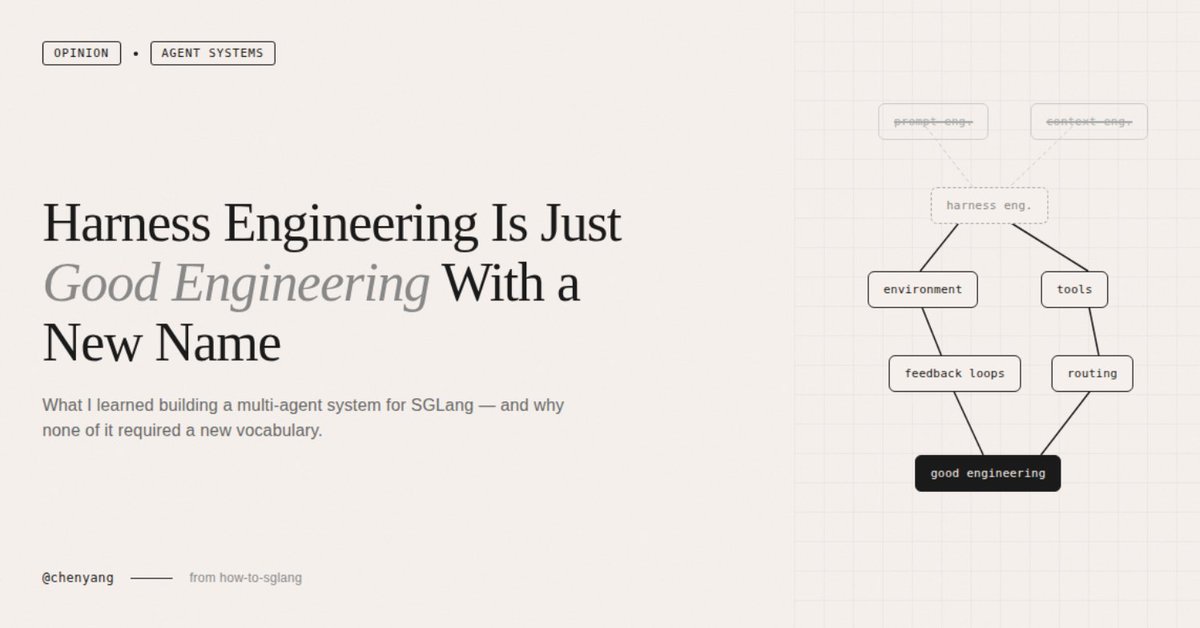
Today I read a lengthy piece on Harness Engineering — tens of thousands of words, almost certainly AI-written. My first reaction wasn't "wow, what a powerful concept." It was "do these people have any ideas beyond coining new terms for old ones?"
I've always been annoyed by this pattern in the AI world — the constant reinvention of existing concepts. From prompt engineering to context engineering, now to harness engineering. Every few months someone coins a new term, writes a 10,000-word essay, sprinkles in a few big-company case studies, and the whole community starts buzzing. But if you actually look at the content, it's the same thing every time:
Design the environment your model runs in — what information it receives, what tools it can use, how errors get intercepted, how memory is managed across sessions. This has existed since the day ChatGPT launched. It doesn't become a new discipline just because someone — for whatever reason — decided to give it a new name.
That said, complaints aside, the research and case studies cited in the article do have value — especially since they overlap heavily with what I've been building with how-to-sglang. So let me use this as an opportunity to talk about the mistakes I've actually made.
Some background first. The most common requests in the SGLang community are How-to Questions — how to deploy DeepSeek-V3 on 8 GPUs, what to do when the gateway can't reach the worker address, whether the gap between GLM-5 INT4 and official FP8 is significant. These questions span an extremely wide technical surface, and as the community grows faster and faster, we increasingly can't keep up with replies. So I started building a multi-agent system to answer them automatically.
The first idea was, of course, the most naive one — build a single omniscient Agent, stuff all of SGLang's docs, code, and cookbooks into it, and let it answer everything.
That didn't work.
You don't need harness engineering theory to explain why — the context window isn't RAM. The more you stuff into it, the more the model's attention scatters and the worse the answers get. An Agent trying to simultaneously understand quantization, PD disaggregation, diffusion serving, and hardware compatibility ends up understanding none of them deeply.
The design we eventually landed on is a multi-layered sub-domain expert architecture. SGLang's documentation already has natural functional boundaries — advanced features, platforms, supported models — with cookbooks organized by model. We turned each sub-domain into an independent expert agent, with an Expert Debating Manager responsible for receiving questions, decomposing them into sub-questions, consulting the Expert Routing Table to activate the right agents, solving in parallel, then synthesizing answers.
Looking back, this design maps almost perfectly onto the patterns the harness engineering community advocates. But when I was building it, I had no idea these patterns had names. And I didn't need to.
1. Progressive disclosure — we didn't dump all documentation into any single agent. Each domain expert loads only its own domain knowledge, and the Manager decides who to activate based on the question type. My gut feeling is that this design yielded far more improvement than swapping in a stronger model ever did. You don't need to know this is called "progressive disclosure" to make this decision. You just need to have tried the "stuff everything in" approach once and watched it fail.
2. Repository as source of truth — the entire workflow lives in the how-to-sglang repo. All expert agents draw their knowledge from markdown files inside the repo, with no dependency on external documents or verbal agreements. Early on, we had the urge to write one massive sglang-maintain.md covering everything. We quickly learned that doesn't work. OpenAI's Codex team made the same mistake — they tried a single oversized AGENTS.md and watched it rot in predictable ways. You don't need to have read their blog to step on this landmine yourself. It's the classic software engineering problem of "monolithic docs always go stale," except in an agent context the consequences are worse — stale documentation doesn't just go unread, it actively misleads the agent.
3. Structured routing — the Expert Routing Table explicitly maps question types to agents. A question about GLM-5 INT4 activates both the Cookbook Domain Expert and the Quantization Domain Expert simultaneously. The Manager doesn't guess; it follows a structured index. The harness engineering crowd calls this "mechanized constraints." I call it normal engineering.
I'm not saying the ideas behind harness engineering are bad. The cited research is solid, the ACI concept from SWE-agent is genuinely worth knowing, and Anthropic's dual-agent architecture (initializer agent + coding agent) is valuable reference material for anyone doing long-horizon tasks. What I find tiresome is the constant coining of new terms — packaging established engineering common sense as a new discipline, then manufacturing anxiety around "you're behind if you don't know this word."
Prompt engineering, context engineering, harness engineering — they're different facets of the same thing. Next month someone will probably coin scaffold engineering or orchestration engineering, write another lengthy essay citing the same SWE-agent paper, and the community will start another cycle of amplification.
What I actually learned from how-to-sglang can be stated without any new vocabulary:
Information fed to agents should be minimal and precise, not maximal. Complex systems should be split into specialized sub-modules, not built as omniscient agents. All knowledge must live in the repo — verbal agreements don't exist. Routing and constraints must be structural, not left to the agent's judgment. Feedback loops should be as tight as possible — we currently use a logging system to record the full reasoning chain of every query, and we've started using Codex for LLM-as-a-judge verification, but we're still far from ideal.
None of this is new. In traditional software engineering, these are called separation of concerns, single responsibility principle, docs-as-code, and shift-left constraints. We're just applying them to LLM work environments now, and some people feel that warrants a new name.
I don't know how many more new terms this field will produce. But I do know that, at least today, we've never achieved a qualitative leap on how-to-sglang by swapping in a stronger model. What actually drove breakthroughs was always improvements at the environment level — more precise knowledge partitioning, better routing logic, tighter feedback loops. Whether you call it harness engineering, context engineering, or nothing at all, it's just good engineering practice. Nothing more, nothing less.
There is one question I genuinely haven't figured out: if model capabilities keep scaling exponentially, will there come a day when models are strong enough to build their own environments? I had this exact confusion when observing OpenClaw — it went from 400K lines to a million in a single month, driven entirely by AI itself. Who built that project's environment? A human, or the AI? And if it was the AI, how many of the design principles we're discussing today will be completely irrelevant in two years?
I don't know. But at least today, across every instance of real practice I can observe, this is still human work — and the most valuable kind.
English






慕名试了一下 gstack。
确实很yc,与我的刻板印象相符。
全是那套他们自己奉若圭臬,但已经过时的片儿汤话。
很像是那种照着上个商业时代,投资人最爱追的那些东西,做的一个角色扮演游戏。有点复古味道,会让我想起之前风起云涌的年代。
但也就这样了。
劝大家别浪费时间,一群title高高在上的人能有什么新世代的经验感悟?
就该自己上手,你写出来的一定比Garry tan 写出来的东西强。
中文
@null12022202 @kevinma_dev_zh 我之前想过,还 notebooklm 搞了一批 ppt 先分析了
但想想这种 skill 大概很难有什么实际价值
做就是炫技,就不想搞了
中文

@kevinma_dev_zh 忽然想到也可以把高效能人士的七个习惯里面的精髓创建成skill,来指导自己每天都工作规划,避免在琐事上投入太多导致重要的事被耽误。
中文

Garry 的 gstack skills 已经很多人转发了,但我还是想多说一句。
这个开源的东西,表面上是一套 Claude Code 的 skills 配置,但里面真正有价值的是 `/office-hours`——在你写一行代码之前,先用六个强迫性问题逼你把产品想清楚。需求是真实的吗?市场够窄吗?你有没有在骗自己?
这套思维框架,比任何写代码的 skills 都值钱,没有之一。
多花时间读里面的具体内容,不只是安装完跑跑就算了。这是 Garry 把 YC 十几年的 founder 审查方法论直接开源出来,不多说了,我也要赶紧学习了。
github.com/garrytan/gstack
Garry Tan@garrytan
I just launched /office-hours skill with gstack. Working on a new idea? GStack will help you think about it the way we do at YC. (It's only a 10% strength version of what a real YC partner can do for you, but I assure you that is quite powerful as it is.)
中文
Garry Tan 的 Skill 的中文版使用指南,22个每一个都详细分析了:
gona.ai/skills/index-g…




Garry Tan@garrytan
I just launched /office-hours skill with gstack. Working on a new idea? GStack will help you think about it the way we do at YC. (It's only a 10% strength version of what a real YC partner can do for you, but I assure you that is quite powerful as it is.)
中文

OpenCLI 迎来重磅更新:External CLI Hub 发布! 🚀
以前,为了让 AI Agent 调用某个工具,你需要反复教它写不同的命令行。 OpenCLI 成为所有 CLI 的统一入口与路由中心!
这样只需要让 AI agent 知道通过 OpenCLI 就能知道他有哪些 CLI可以使用,不用再搞一堆 CLI skill 了
核心亮点: 零配置纯透传 不用写任何适配代码!直接运行 opencli obsidian search 或 opencli gh pr list,参数和输出100% 极其原生透传给原 CLI。AI 只需要认识 opencli 这一个入口,就能调动全网工具!
按需无感自动安装 想调用的 CLI 还没装?OpenCLI 会自动探测平台,帮你静默执行 brew install gh 或 npm i -g readwise,装完立马接力执行
一键接入你的本地宇宙 你本地有自己写的牛逼小工具?只需一行 opencli register mycli,它就会立即出现在 opencli list 注册表中,被你的 AI Assistant瞬间“看见”并掌握使用权!
github.com/jackwener/open…
中文
@bozhou_ai 也有类似的体会,我称:刚性代码,柔性Skill。
分阶段做任务,分阶段的部分在代码,结果检验也在代码,不行让 Skill 在一个阶段内部重做。
中文
