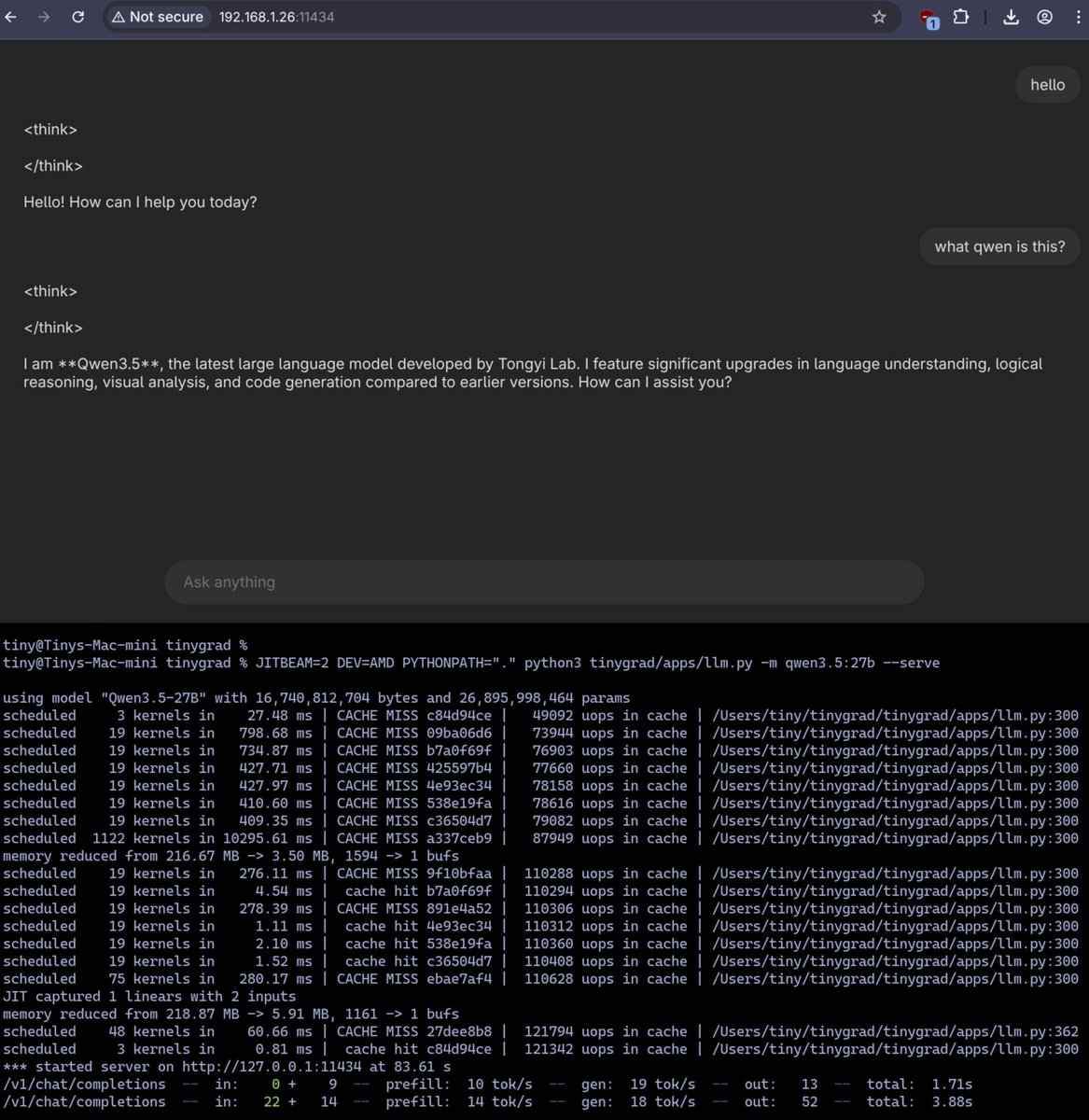
yeah, it should work. 7800 XT is gfx1102, same RDNA3 family as the 7900 XTX so it JIT compiles clean on first run. 9B DFlash is up and running — perf scales roughly with CU count (60 vs 96 on the XTX). 27B is too heavy for 16GB right now. working toward more aggressive quants like MQ2 on the roadmap since a few people have asked. repo: github.com/Kaden-Schutt/h…
English