
Marko Simic
718 posts

Marko Simic
@simicvm
Building 🧠 for 🤖 ▶️ https://t.co/ooibfjkaTr 🪙 https://t.co/CrskFZD6WE 👥 https://t.co/FAGPxlD2G3
Tokyo-to, Japan Sumali Haziran 2018
546 Sinusundan266 Mga Tagasunod

Holy SHIIIIIIITTTTTTTTT
@TheRealAdamG what did you guys created , this is insane
GPT pro update created a masterpiece under 11 mins, wtf holy shit prompt and codepen link in comment
Chetaslua@chetaslua
GPT Pro - Spud solved SVG One SHOT svg , code is shared in the comments @OpenAI you won this time , i never said this but i love this comeback lets gooo @sama
English
@MLStreetTalk M4 Max 128gb
llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q8_0
read: ~1000t/s
write: ~75t/s
English

I couldn't find any benchmarks of folks running the Gemma models on an M4 Max (with Ollama 0.20 and mlx-vlm), so I just got my agent to do a very rough benchmark in case anyone is interested.
Ollama 0.20 and raw MLX-VLM give you 65-75 tok/s on Gemma 4 26B-A4B — within ~12% of each other because both now run MLX underneath.
The main practical difference is memory: Ollama grabs 34 GB (pre-allocated 262K context), MLX-VLM uses 16 GB (dynamic). KV cache quantization is a non-factor at normal context lengths. The main thing is that MoE makes the 26B model 6x faster than the 31B dense — you get a "bigger" model at the speed of a much
smaller one.
Quant caveats - these results compare Ollama's Q4_K_M (GGUF) against mlx-community's 4-bit affine (MLX). Both are 4-bit but use different quantization methods with different quality/speed trade-offs. The mlx-community repo offers 15+ quantization variants for this model (bf16, 4/5/6/8-bit, mxfp4/8, nvfp4). Ollama ships a single default quant per model size. Different quant choices would shift both speed and quality.


Prince Canuma@Prince_Canuma
Gemma 4 31B running with TurboQuant KV cache on MLX 🔥 128K context: → KV Memory: 13.3 GB → 4.9 GB (63% reduction) → Peak Memory: 75.2 GB → 65.8 GB (-9.4 GB) → Quality preserved TurboQuant compression scales with sequence length, so the longer the context, the bigger the savings! Try it out: > uv run mlx_vlm.generate –model google/gemma-4-31b-it –kv-bits 3.5 –kv-quant-scheme turboquant Note: Decode speed drops (~1.5x) due to kernel launch overheads, we are aware and will fix in coming releases.
English
@ivanfioravanti @danieltvela this command works for spec decoding but running it I get 2x lower t/s than when just running the big model alone 🤔 llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q8_0 -hfd ggml-org/gemma-4-E2B-it-GGUF:Q8_0 --no-mmproj
English

Is anyone able to tell me the llama-server arguments used to create this? I tried with many possible combinations without success.
Thanks for anyone willing to help 🙏 I love this idea and I'd like to dig deeper.
Georgi Gerganov@ggerganov
Let me demonstrate the true power of llama.cpp: - Running on Mac Studio M2 Ultra (3 years old) - Gemma 4 26B A4B Q8_0 (full quality) - Built-in WebUI (ships with llama.cpp) - MCP support out of the box (web-search, HF, github, etc.) - Prompt speculative decoding The result: 300t/s (realtime video)
English
@ivanfioravanti opencode mac app is quite good. has a git worktree support out of the box
English
How do you orchestrate your coding agents? I have 4 Claude Code sessions with 4 different providers, Gemini CLI, Cursor, RepoPrompt and things are a bit crazy at the moment 🤣
English
Marko Simic nag-retweet

Meet @svegas18, @AustinBaggio , @christinetyip from autoresearch@home:
> Wednesday, they release the most comprehensive autoresearch repo & leaderboard
> Same day, we plan and launch an autoresearch hack
> Thursday, they decide to fly y from Canada & NYC to present their work

English

@edouard_iosdev @levelsio I've traveled to the US with it many times. I was only stopped once for a check. They took a sample, ran a test, and let me go within a few minutes.
English

@sawyerhood yeap, did that few weeks ago. runs qwen3 stt, all local
github.com/simicvm/whisper
English

wispr flow & co is actually simple enough that you can actually just ask claude / codex to make it. 10/10 no regrets on vibe coding one
Dan Romero@dwr
Superwhisper or Wispr Flow?
English
@RobertTLange very cool work! it's great when it works, but so far in my testing I am getting mixed results on doc-to-lora.

English

Doc-to-LoRA: What if you could online distill documents into your LLM weights without training?
🚀 Stoked to share our new work on instant LLM adaptation using meta-learned hypernetworks 📷📝
Building on our previous Text-to-LoRA work, we doc-condition a hypernetwork to output LoRA adapters, improving the base LLM's effective context window.
The hypernetwork is meta-trained on 1000s of summarization tasks and shows remarkable compression capabilities at low latency 📈
🧑🔬 Work led by @tan51616 with @edo_cet & Shin Useka at @SakanaAILabs 📷
Sakana AI@SakanaAILabs
We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible. pub.sakana.ai/doc-to-lora/ By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly internalize new information or adapt to new tasks. Biological systems naturally rely on two key cognitive abilities: durable long-term memory to store facts, and rapid adaptation to handle new tasks given limited sensory cues. While modern LLMs are highly capable, they still lack this flexibility. Traditionally, adding long-term memory or adapting an LLM to a specific downstream task requires an expensive and time-consuming model update, such as fine-tuning or context distillation, or relies on memory-intensive long prompts. To bypass these limitations, our work focuses on the concept of cost amortization. We pay the meta-training cost once to train a hypernetwork capable of producing tasks or document specific LoRAs on demand. This turns what used to be a heavy engineering pipeline into a single, inexpensive forward pass. Instead of performing per-task optimization, the hypernetwork meta-learns update rules to instantly modify an LLM given a new task description or a long document. In our experiments, Text-to-LoRA successfully specializes models to unseen tasks using just a natural language description. Building on this, Doc-to-LoRA is able to internalize factual documents. On a needle-in-a-haystack task, Doc-to-LoRA achieves near-perfect accuracy on instances five times longer than the base model's context window. It can even generalize to transfer visual information from a vision-language model into a text-only LLM, allowing it to classify images purely through internalized weights. Importantly, both methods run with sub-second latency, enabling rapid experimentation while avoiding the overhead of traditional model updates. This approach is a step towards lowering the technical barriers of model customization, allowing end-users to specialize foundation models via simple text inputs. We have released our code and papers for the community to explore. Doc-to-LoRA Paper: arxiv.org/abs/2602.15902 Code: github.com/SakanaAI/Doc-t… Text-to-LoRA Paper: arxiv.org/abs/2506.06105 Code: github.com/SakanaAI/Text-…
English
We vibe-coded ocrit.app to test different OCR models. Between DeepSeek OCR 2, GLM OCR, and LightOnOCR-2, we are getting the most consistent results from DeepSeek. Its bounding box placement is also quite good.
English
@clattner_llvm @AnthropicAI Cool article! I'm curious, though, why is this the most interesting lesson if it’s exactly what you’d expect from an LLM? You even mention that in the next paragraph! 🙂

English

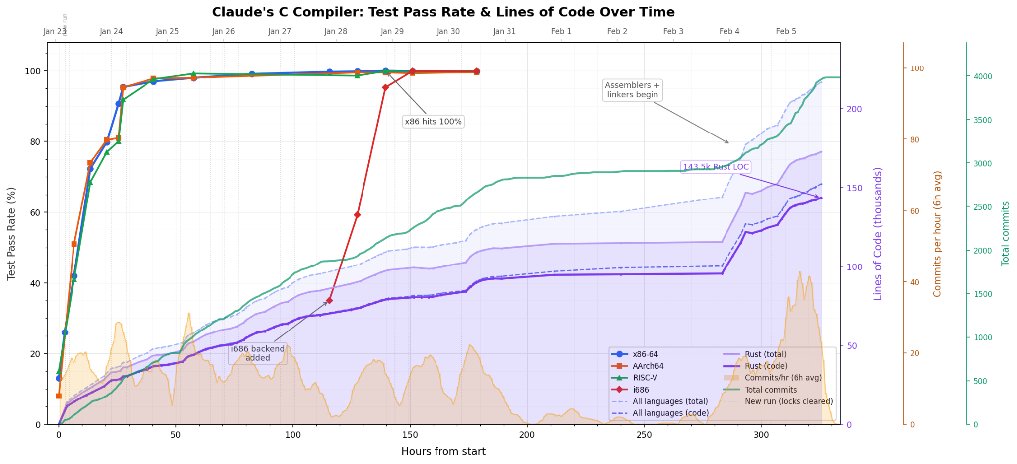
The Claude C Compiler is the first AI-generated compiler that builds complex C code, built by @AnthropicAI. Reactions ranged from dismissal as "AI nonsense" to "SW is over": both takes miss the point.
As a compiler🐉 expert and experienced SW leader, I see a lot to learn: 👇
English
English
fully local Wispr alternative app running Qwen3 ASR 0.6B via mlx-audio-swift. practically instantaneous result in any active input field. @Prince_Canuma
English
@EuroJohannes @Prince_Canuma I like pageless layout and it looks better in gray
English

@simicvm @Prince_Canuma very cool but why is your google docs gray?
English
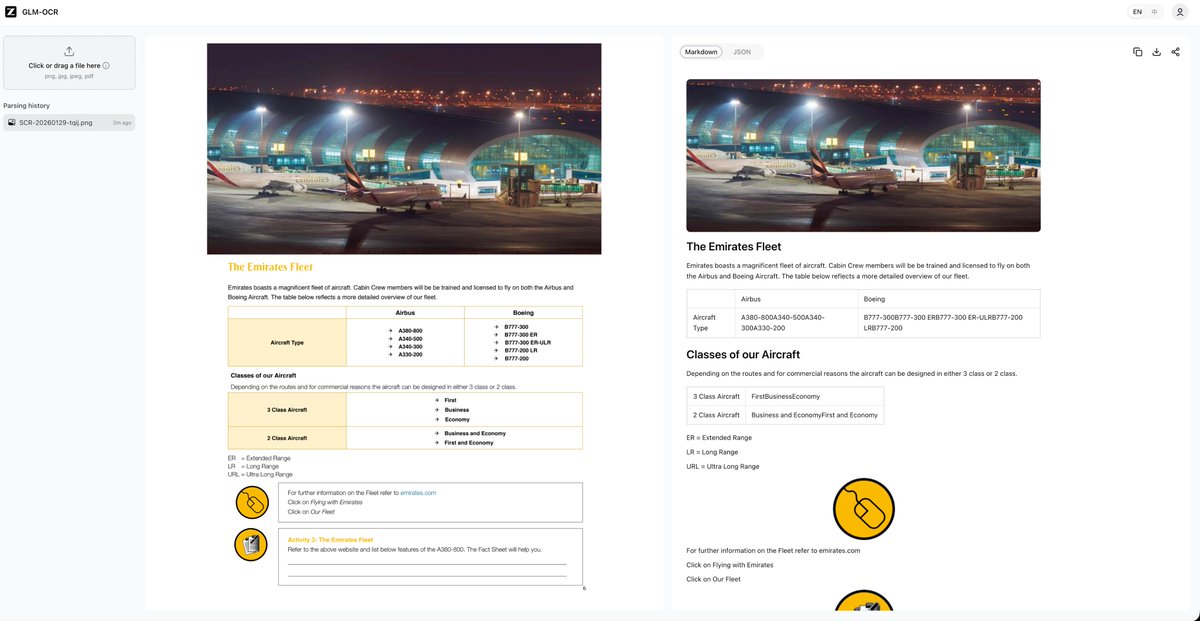
@Prince_Canuma running the same image on their demo app provides a good output. although it takes quite long to get the result, but that might be due to some free demo constraints.
English

@simicvm Yap, it's fast!
Could you share examples so I can double check?
English
@Prince_Canuma for example, I was not able to make it recognize all the text in this image, regardless of the mode I used. meanwhile, DS does it with ease.

English
@Prince_Canuma did some tests with it. running on mbp m4 max 128. definitely faster than DeepSeek OCR2. however, it's significantly worse than DS on complex documents.
English