@neetcode1 My take: the slowdown starts when prompts replace diagnosis. I use AI for drafts, then require one failing repro and one explicit root cause before iterating. Without that, it drifts and manual edits win.
English
Syncause
420 posts
@syncause
AI Coding Debugger Stop the AI "Fix ➔ Fail ➔ Retry" Loop https://t.co/zljuMKTHt8

I'm not very happy with the code quality and I think agents bloat abstractions, have poor code aesthetics, are very prone to copy pasting code blocks and it's a mess, but at this point I stopped fighting it too hard and just moved on. The agents do not listen to my instructions in the AGENTS.md files. E.g. just as one example, no matter how many times I say something like: "Every line of code should do exactly one thing and use intermediate variables as a form of documentation" They will still "multitask" and create complex constructs where one line of code calls 2 functions and then indexes an array with the result. I think in principle I could use hooks or slash commands to clean this up but at some point just a shrug is easier. Yes I think LLM as a judge for soft rewards is in principle and long term slightly problematic (due to goodharting concerns), but in practice and for now I don't think we've picked the low hanging fruit yet here.






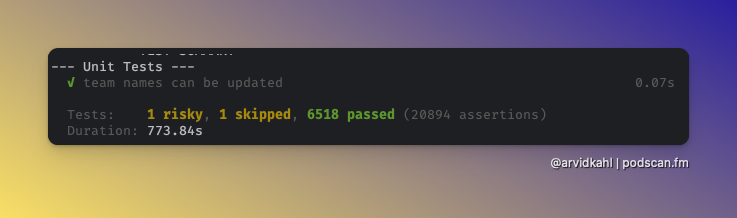
Tests have nothing to do with whether you understand the code. They exist to prove the code does what it’s supposed to do. I don’t trust any code I haven’t tested. That’s true whether I wrote the code, you wrote it, or an AI wrote it.