LlamaIndex 🦙@llama_index
We've spent years building LlamaParse into the most accurate document parser for production AI. Along the way, we learned a lot about what fast, lightweight parsing actually looks like under the hood.
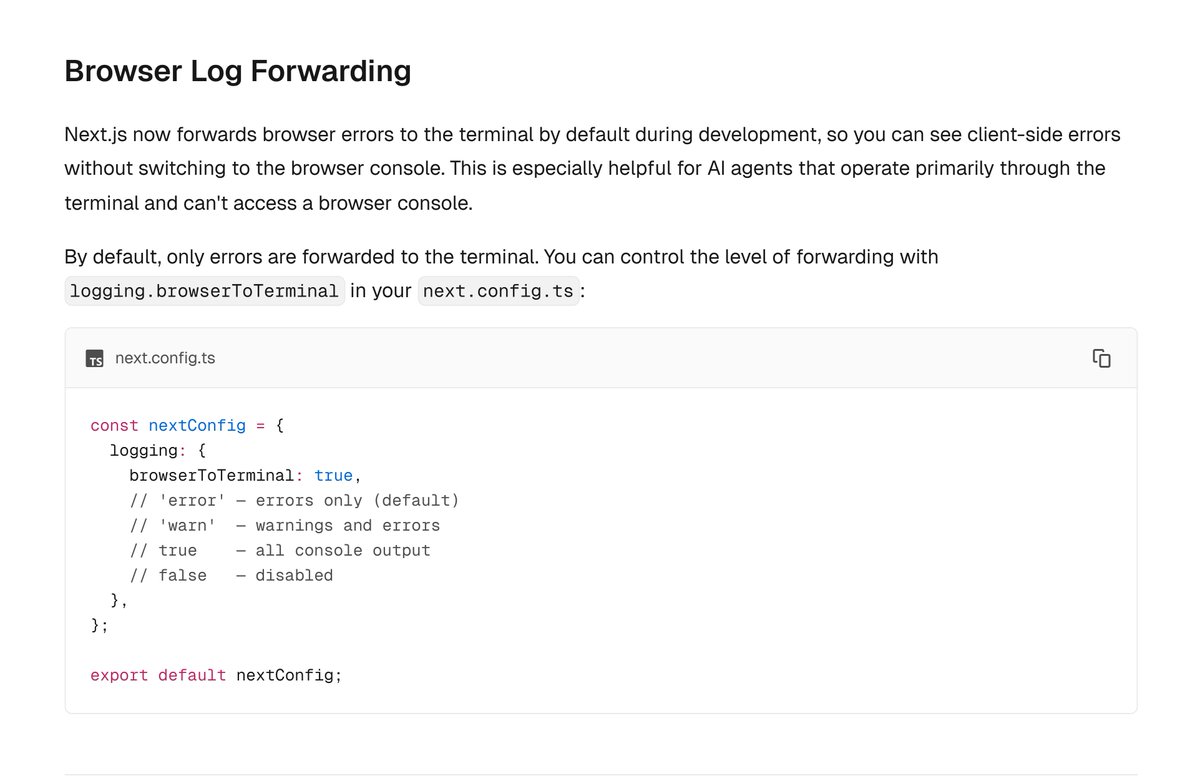
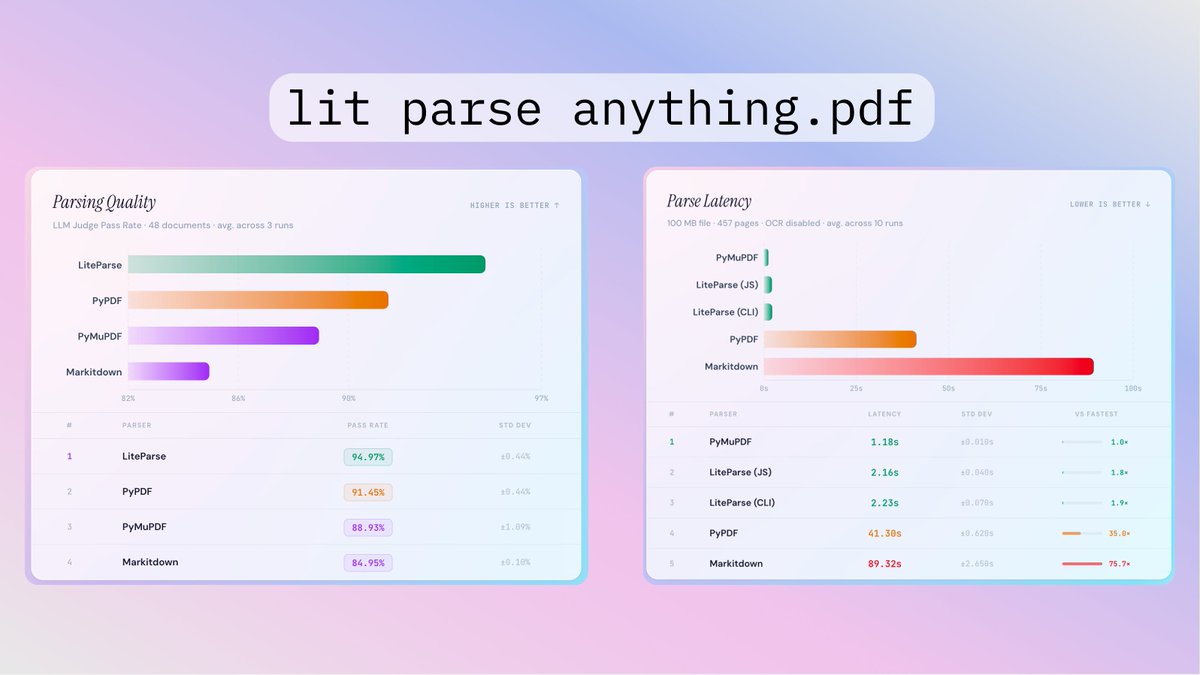
Today, we're open-sourcing a light-weight core of that tech as LiteParse 🦙
It's a CLI + TS-native library for layout-aware text parsing from PDFs, Office docs, and images. Local, zero Python dependencies, and built specifically for agents and LLM pipelines. Think of it as our way of giving the community a solid starting point for document parsing:
npm i -g @llamaindex/liteparse
lit parse anything.pdf
- preserves spatial layout (columns, tables, alignment)
- built-in local OCR, or bring your own server
- screenshots for multimodal LLMs
- handles PDFs, office docs, images
Blog: llamaindex.ai/blog/liteparse…
Repo: github.com/run-llama/lite…