Snorkel AI ری ٹویٹ کیا

ICYMI - How can we build the benchmark factory?
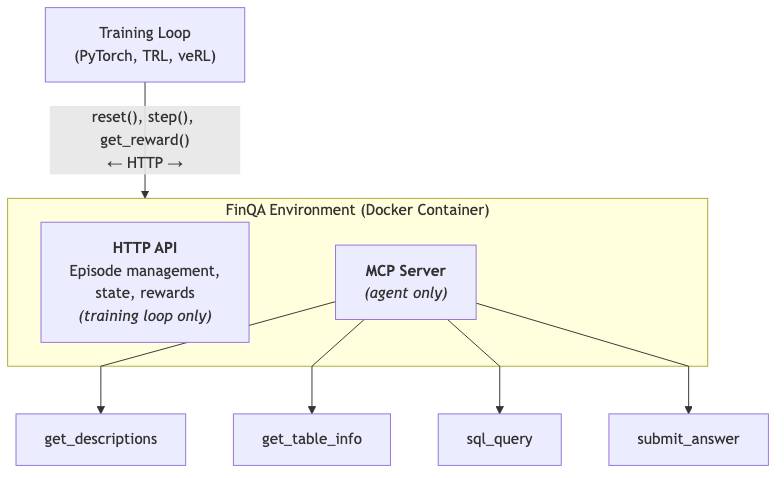
I'm very excited about the infra approach from @harborframework, because @alexgshaw @ryanmart3n & team obsess over researcher/developer UX (e.g. quality guardrails, low friction to RL/scaled rollouts)!
English