
Transluce ری ٹویٹ کیا

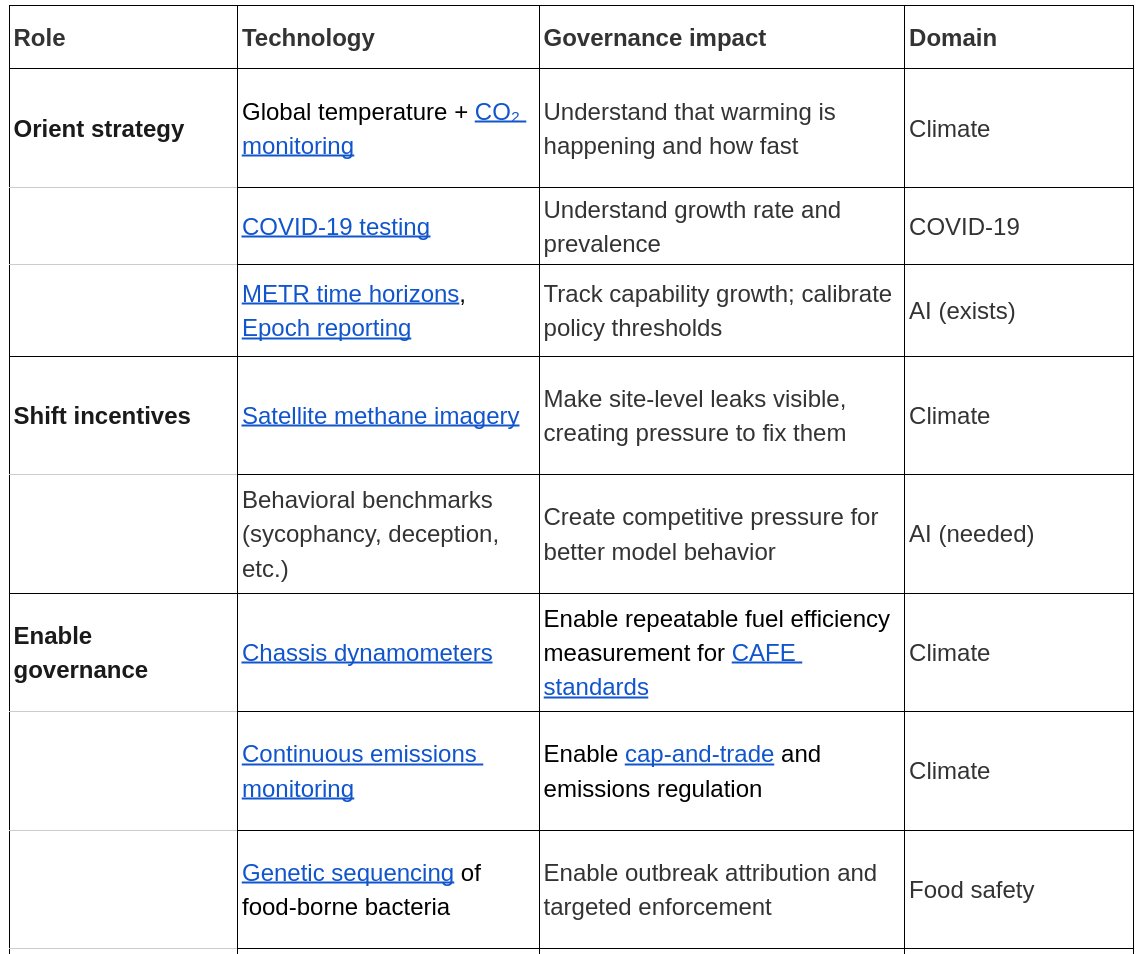
New blog post:"Building Technology to Drive AI Governance". I argue that many governance challenges are fundamentally bottlenecked by technical gaps, and consider case studies from other fields (food safety, climate change) that illustrate this dynamic.
English