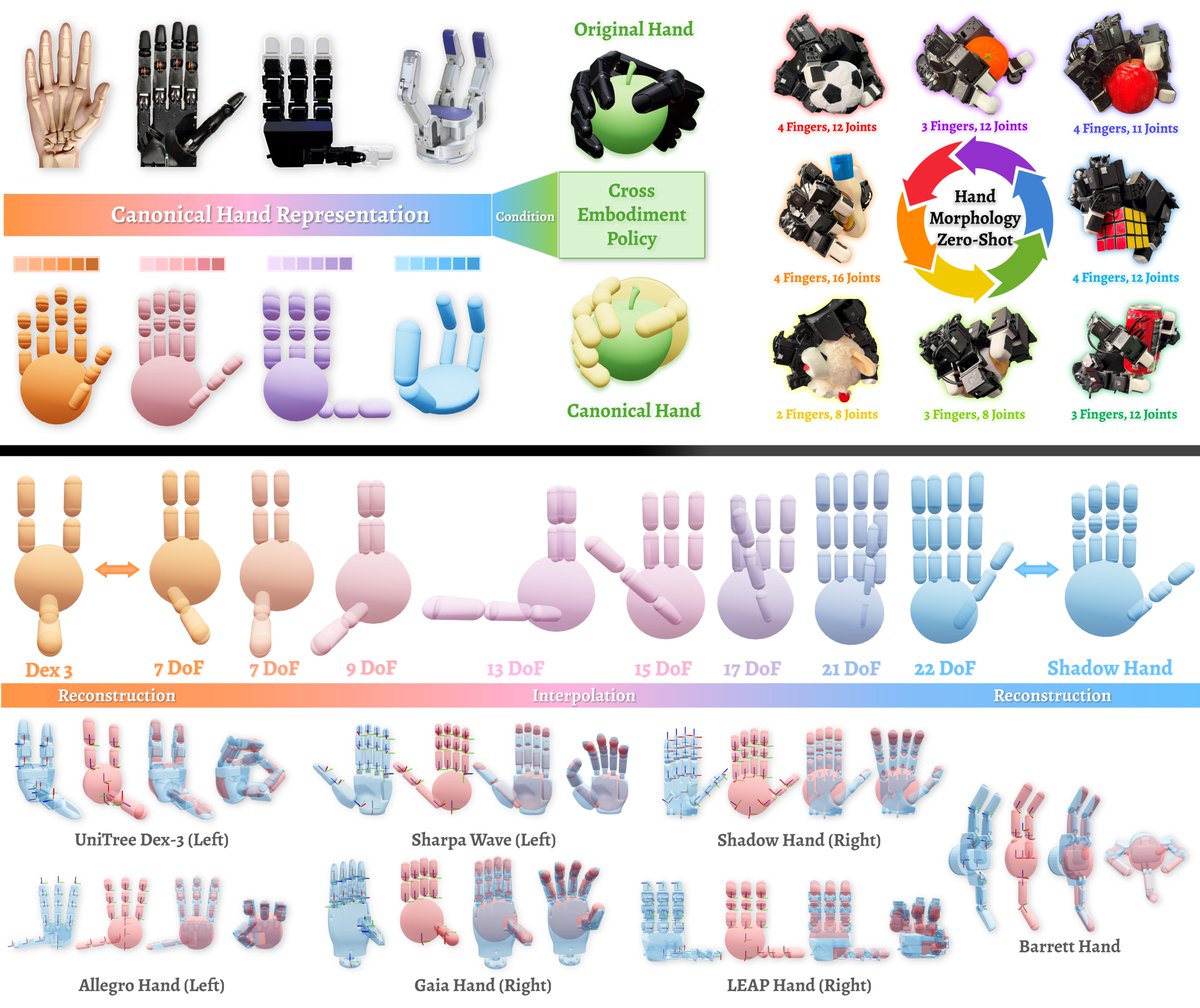
Mingyu Ding ری ٹویٹ کیا

🚀 AutoResearchClaw v0.4.0 is here — almost 10K⭐ in just over 2 weeks!
Now supporting both fully autonomous AND human-AI co-pilot modes — you choose your level of involvement.
What's new:
🤝 6 intervention modes — full-auto, gate-only, checkpoint, step-by-step, co-pilot, and custom. Same powerful 23-stage pipeline, your level of control.
🧪 Idea Workshop — brainstorm and refine hypotheses with AI before committing to a direction
📊 Baseline Navigator — review and customize experiment designs before execution
✍️ Paper Co-Writer — draft papers section-by-section, collaboratively
🧠 SmartPause — the system learns when to pause and ask for your input based on confidence levels
💰 Cost Guardrails — budget alerts at 50/80/100% so you never get surprised
🔀 Pipeline Branching — explore multiple hypotheses in parallel, compare, and merge the best
Want full automation? It still does that. Want to stay in the loop? Now you can, at exactly the granularity you want.
Try it 👉: github.com/aiming-lab/Aut…
Kudos to the team @JiaqiLiu835914, @richardxp888, @lillianwei423, @StephenQS0710, @Xinyu2ML, @HaoqinT, @jiahengzhang96, @yuyinzhou_cs, @ZhengBerkeley, @cihangxie, @dingmyu, etc.

English