پن کیا گیا ٹویٹ
Mohamed
1.7K posts


Mohamed
@mohammad2012191
وماذا عليك لو ذهبوا هُم بالدنيا، وأنتَ ذهبت بالقرآن؟ | AI Researcher @ KAUST - Kaggle Competitions Master (Highest Rank: 236th in the World)
شامل ہوئے Ekim 2013
451 فالونگ1.8K فالوورز
Mohamed ری ٹویٹ کیا

23 years old with no advanced mathematics training solves Erdős problem with ChatGPT Pro. "What’s beginning to emerge is that the problem was maybe easier than expected, and it was like there was some kind of mental block.”-Terence Tao scientificamerican.com/article/amateu…
English
@cwolferesearch @cwolferesearch
I tried similar concept in this work. Initially the master agent asks the subagents to collect evidence to answer a query in a MM memory.
Then everytime a round finishes, the master agent removes any irrelevant evidence from the memory.
x.com/i/status/20344…
Mohamed@mohammad2012191
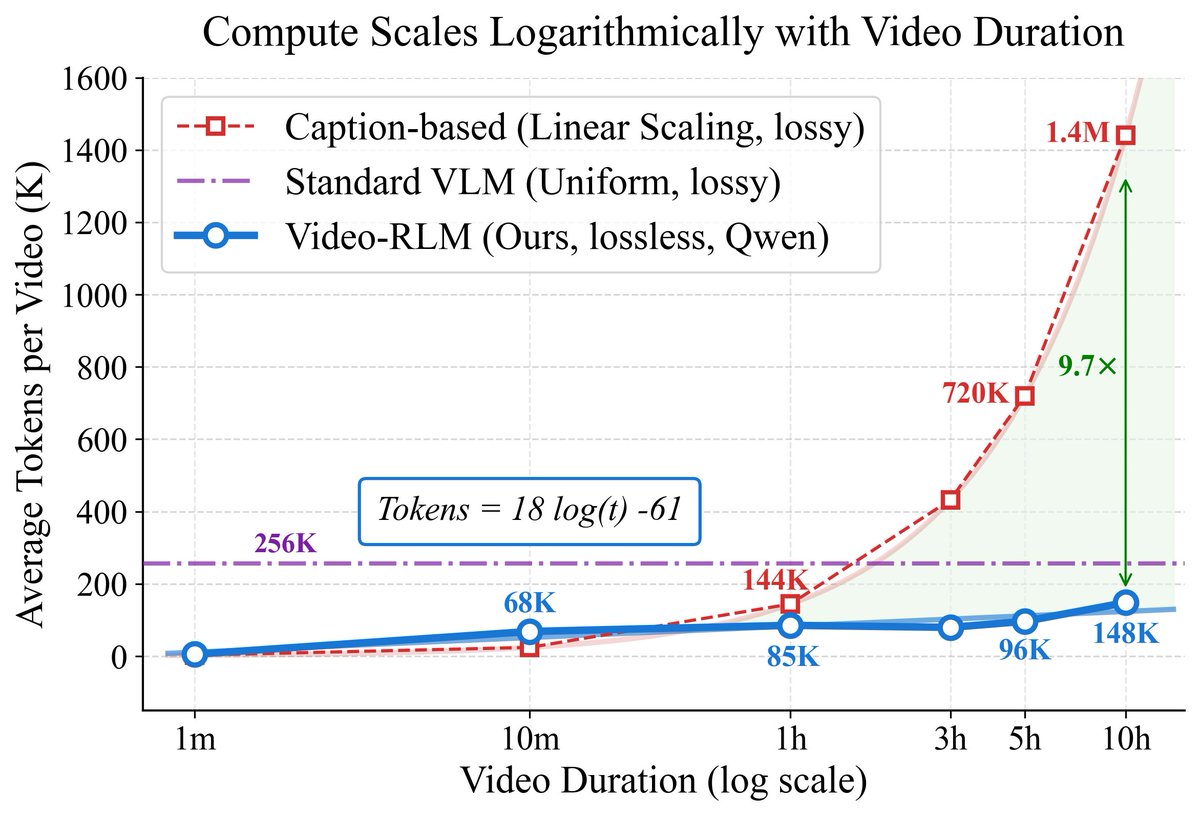
What if understanding a video was more like navigating a map?🤔 And what if that made compute scale logarithmically (not linearly) with video length?! New preprint🎉: 🗺️VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
English

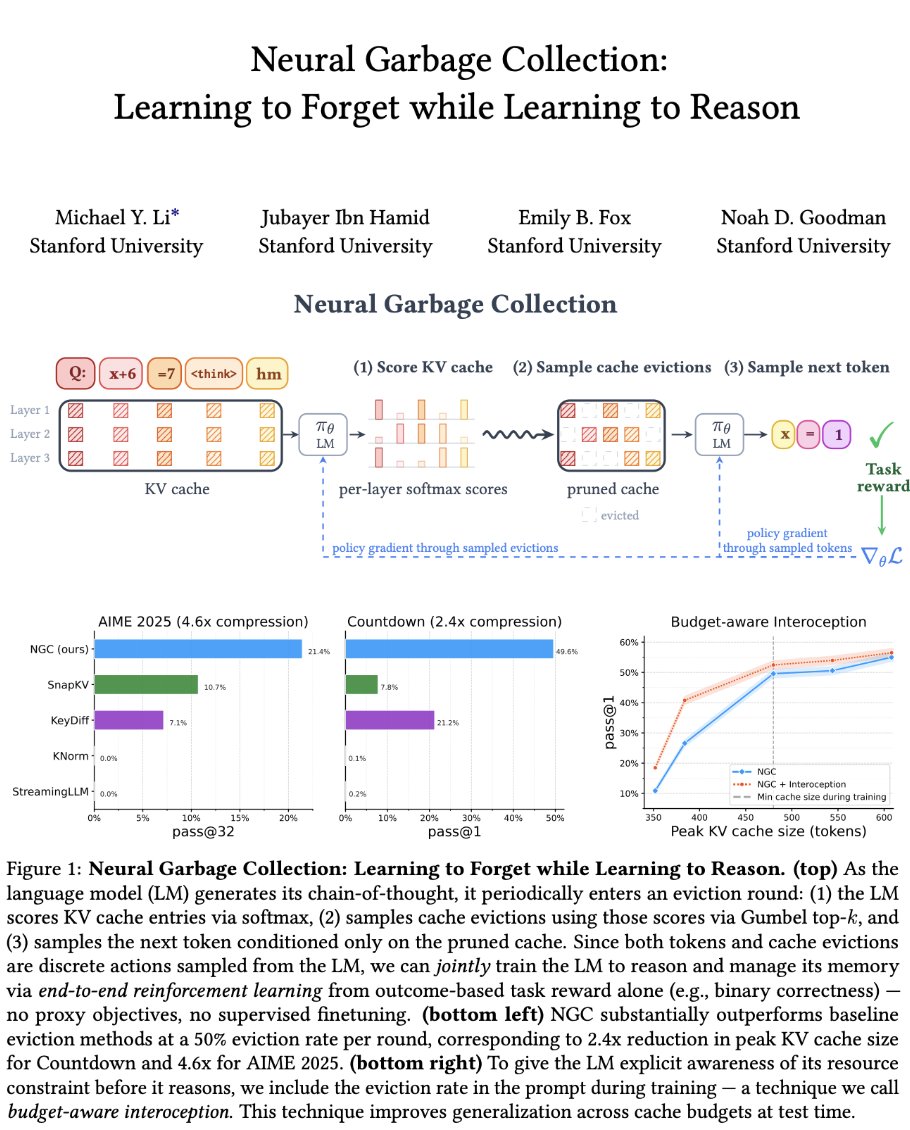
The idea of training LLMs to manage their own KV cache is super interesting to me. The recent neural garbage collection (NGC) paper was a great read on this topic.
Reasoning models / agents obviously need long sequences to handle complex reasoning, long horizon tasks, tool calls, etc. However, the size of the KV increases linearly with the length of your sequence, creating a KV cache bottleneck.
To solve this, there are several heuristics that have been proposed; e.g., only keeping recent tokens, keeping tokens with high attention scores, etc. But these heuristics tend to degrade performance and may or may not work well depending on the domain / task.
Instead of using heuristics, we can try to teach the LLM to manage its own KV cache. Concretely, NGC does this by implementing an eviction cadence. Every δ tokens during the decoding process, NGC scores all of its KV cache blocks and defines an eviction rate ϵ such that only (1 - ϵ) of KV cache blocks are kept. By doing this, we can ensure that the peak cache size is stable.
To score KV cache blocks, NGC does not use any new or specialized models / modules. Instead, it repurposes the LLM's existing attention mechanism. The model takes the most recent query vectors, partitions KV cache into fixed-size blocks, then scores previous keys based on the query vectors.
Instead of performing specialized training for managing the KV cache, NGC simply incorporates KV cache management into the verifiable loss for training with RL / GRPO. The RL objective both has both:
1. A component for normal token predictions.
2. A component for KV cache eviction decisions.
This way, we can train the model end-to-end with RL to correctly evict KV cache blocks (similarly to predicting a token) while still using outcome rewards.
English
@Star_Knight12 Anthropic has a huge pool of users chats with private codebases and many deep techincal stuff. Maybe the real sauce is there, and gemini performance is the current public internet limit.
English

@dosco Thanks! Yeah sort of.
Actually i iterated a lot on what functions might be suitable (some failures: horizontal shift, jump..).
Backtrack is useful when we have multiple depths, as the subagent can expand a cell then realize there is no useful info there, so it goes back.
English

@mohammad2012191 using a grid of temporal ranges with hierarchy is brilliant. it's RLM but not lambda right and BACKTRACK() is interesting whats your intuition on its use. thanks for sharing amazing work.
English
the y-combinator rlm paper is very interesting. i don't quite fully get why it works better. original rlm was “let the llm improvise python in a loop and pray it stops”. λ-rlm does one task detect call, then pure math + typed combinators do all the splitting/filtering/recursion. llm only shows up at the leaves.
English
@hbouammar Thanks!
It feels now that RLMs explore text sequentially (which is also how standard agents were exploring long videos). But was thinking, what if there is such a heirarchal hidden structure but for text🤔 i guess i will find an answer soon
English

Maybe long-context reasoning should stop relying on models writing their own recursive control code.
We open-sourced λ-RLM: a typed λ-calculus runtime for recursive reasoning with pre-verified combinators.
🙃29/36 wins vs standard RLM.
🙃Up to +21.9 avg accuracy.
🙃Up to 4.1× lower latency.
GitHub: github.com/lambda-calculu…
Paper: arxiv.org/abs/2603.20105
#AI #MachineLearning #ICLR2025

English
@max_paperclips @max_paperclips
What would happen if the long context was actually a long video :)
x.com/i/status/20344…
Mohamed@mohammad2012191
What if understanding a video was more like navigating a map?🤔 And what if that made compute scale logarithmically (not linearly) with video length?! New preprint🎉: 🗺️VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
English

Very interesting variation on RLM here:
github.com/lambda-calculu…
A lot more of the work is handled by deterministic recursive decomposition rather than the learned policy of the LLM, so I'm interested in playing around with it, comparing it to regular RLM
English

Nobody pay any attention to RLMs. They're garbage and definitely don't work well at all. No amazing emergent properties at all. Not even a little bit.
English
Mohamed ری ٹویٹ کیا

Have you tried GLM-5.1? Was using it this morning thinking that my coding harness was set to Opus-4.7.
All throughout the session I’m like “oh man Opus-4.7 is so good”
Then I send a screenshot, my harness says “this model doesn’t support images”..
Only then I realized it’s all along been on GLM-5.1.
rohit@krishnanrohit
Dario seems to think China and open source will hit Mythos capabilities in 6-12 months
English
Mohamed ری ٹویٹ کیا

I've started referring to how I use Claude Code as Claude Code Descent.
You start with a problem description and a sketch of an experiment that would validate your hypothesis, hopefully something close to the right shape, maybe not quite there, and certainly without the code itself. What you're providing is a directed seed rather than a full initialization: a starting point already pointed towards the right region of idea-space.
The desirable outcome is that from there Claude Code converges to the optimal version, eventually. The speed of convergence, and the quality of the final "solution", both depend on how directed that seed is and how good a verifier you are at each step (and how good the model in CC is). During CCD you approximately verify the direction of descent, while Claude Code computes the gradient for you, and updates the codebase/artifacts.
Kinda useful framing.
English
@realsigridjin They wouldn't sacrifice these things unless the new tokenizer gave a huge jump in...say, vision benchmarks? Oh
English
Mohamed ری ٹویٹ کیا

Our new Stanford class "CME 296: Diffusion & Large Vision Models" is now available on YouTube!
English
Mohamed ری ٹویٹ کیا

Modern Transformer architecture explained
I compiled a list of videos on the Transformer architecture into a short "YouTube course".
Hopefully, this would be helpful for beginners in the community. 🧵

English
@gaur_manu I had this exact problem today while working on a paper. This was literally the only missing part :) gonna build something incredible on top of it.
Thanks for sharing!!
English

Pretrained ViTs like DINOv2 or CLIP are great, but they produce fixed, generic representations that encode the most salient visual concepts (e.g., "cat").
In human vision, prior priming with language changes how people parse an image. We believe visual encoders should do the same
🚨 Introducing Steerable Visual Representations, a new family of visual features you can steer with text towards specific visual concepts.

English
Mohamed ری ٹویٹ کیا

HuggingFace released a nice blog post about the current state of VLMs
Here's a summary, covering recent trends, specialized capabilities, agents, video LMs, new alignment techniques, and HF's fav VLMs [1/8]
Recent trends:

English
Mohamed ری ٹویٹ کیا

it's mostly simple, u just have to be naturally inclined towards doing it without being forced. there are a few things i've found consistently useful (nothing too elaborate, elaborate processes are what i like to call "pseudowork"):
> consuming as much info as possible is what i consider the most critical and unavoidable part of the creative process. before ur brain can be expected to "connect the dots in creative ways", u need to supply it with enough dots for there to be sufficient probability of finding insightful connections among them. consuming lots of info also makes analogical thinking much easier, especially if u do it with enough breadth. u have no idea just how siloed research areas can be from other ones that hold tons of potential for cross-fertilization, but people almost never read widely enough to notice. (tl;dr diversify ur data and then hyperscale it)
> walking away from ideas is usually very helpful. u often go so deep down rabbit holes that ur brain starts missing out on the bigger picture, or on analogies that may be quite obvious in hindsight. most creative ideas are wasted on trying to make a thing worm that should instead just be abandoned and reformulated. what usually works is to take a step back and let new ideas simmer for a while in the back of ur mind. ur brain will automatically take care of fitting the new info in a way that is coherent with the rest of ur knowledge, and that's when things randomly start to "click". taking long walks or any passive activity where ur higher cognitive functions are minimally engaged tends to free up resources for ur brain to wander around and creatively play around with unresolved problems that it identifies as "important" to u based on degree of exposure and emotional attachment.
> the harder u try, the worse u end up doing. trying hard is the opposite of what u want here. u have to just relax, keep consuming relevant info, and the ideas will surely come on their own when u're not already preoccupied with tons of hyperspecific problems already. u can't bang ur head against a screen all night to generate good ideas, it doesn't work that way.
> avoid typical pitfalls such as "creativity-inducing" drugs (e.g. magic mushrooms) as those often put u under the illusion of having profound ideas in style but not in substance.
> write. write as much as u can. write with ur own hands. handwriting is good and typing is close but vibe writing is not what u want. it's not about the output, u can burn all the notes once they're out on paper, not the point. it's the process of putting ideas to clear and intuitive words that forces u to flesh out the details u might've glossed over in ur head, and to iron out weakspots u didn't notice. conversations with smart people that don't have "a horse in the race" are also really good. u should let ideas fight for their survival.
English
Mohamed ری ٹویٹ کیا

best tl;dr of the attention residuals paper: rotating attention 90 degrees
alphaXiv@askalphaxiv
“Attention Residuals” is now available on AlphaXiv! In standard transformer, every layer just inherits an equal sum of all earlier layers, so as models get deeper, useful computations get diluted instead of being selectively reused. The research team at @Kimi_Moonshot proposes Attention Residuals which fixes this by letting each layer attend over previous layers with learned weights, so depth works more like retrieval than accumulation. This makes training more stable, improving scaling and downstream performance with almost no extra overhead, specifically, 1.25x compute advantage against the standard transformer baseline.
English
Mohamed ری ٹویٹ کیا

Hypothesis: for every task that is unverifiable, there is a set of related tasks which are verifiable with the property that hillclimbing on them generalizes to the original task
Brendan Dolan-Gavitt@moyix
There are verifiable rewards everywhere for those with eyes to see
English
@oliverbeavers Thanks! Its reasoning trace is actually really satisfying to see, probably u wanna give it a try :)
English

@mohammad2012191 Whoa this is awesome. Super cool application of RLMs
English