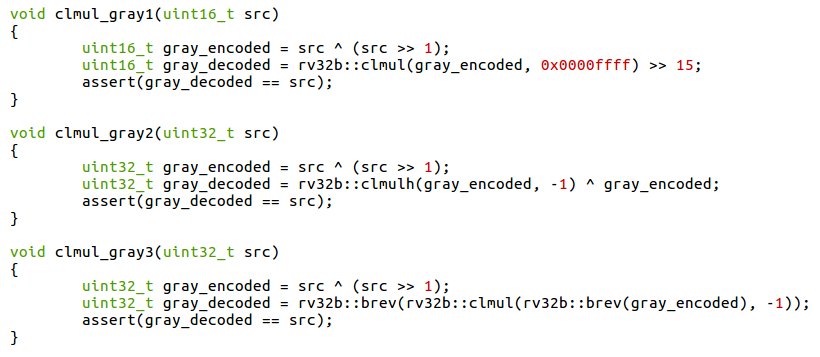
@ciphergoth @oconnor663 @cryptodavidw It wouldn't make much sense to benchmark universal hashes against unkeyed collision-resistant hash functions. But an almost (Δ-)universal hash section on eBACS could be useful on its own.
English
Samuel Neves
1.3K posts