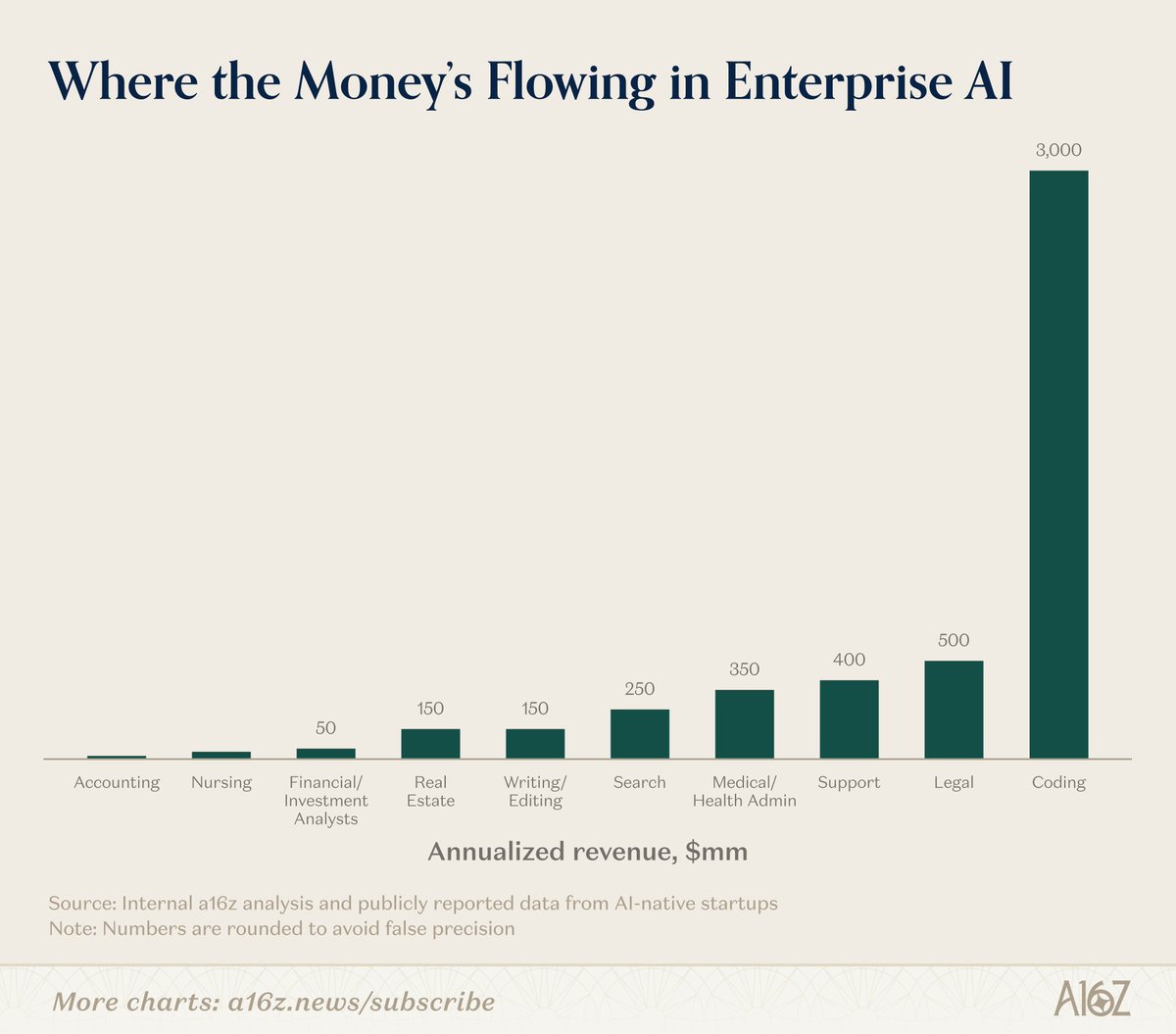
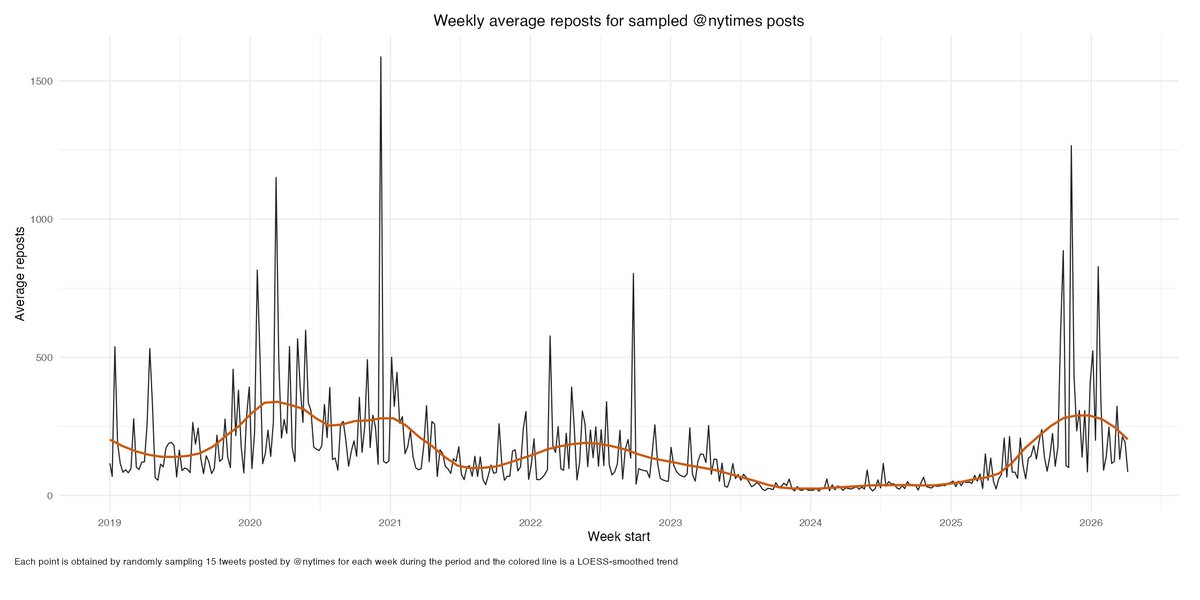
Tenobrus@tenobrus
maybe this is not yet clear, so let me state it plainly: as of right now Anthropic, and really a small number of individuals at Anthropic, has the capacity to directly attack and cause major damage to the United States Government, China, and generally global superpowers. government agencies like the NSA do not have internal models or defense capabilities that outclass frontier models. if they chose to do so, they could likely exfiltrate top secret information from government systems, gain control over critical infrastructure including military infrastructure, sabotage or modify communications between members of government at the highest level, and potentially carry on activities for some time without detection. the thing about having access to a huge number of zerodays your adversaries don't know about is it gives you a massive asymmetric advantage.
they did not exploit this to gain power or destabilize the world order. they publicly released the information that they had these capabilities and worked to mitigate these flaws. you should be grateful american frontier labs have proven themselves remarkably trustworthy and concerned with the public good. but it's critical you understand we are in a new regime. private entities now have power that directly rivals and impacts the government's monopoly on influence and violence. and anthropic is certainly not the only one, there's little chance OpenAI's internal models are far behind.
this trend will accelerate on virtually every dimension, not slow down. my prediction for how it plays out is the relatively imminent seizure and nationalization of labs by the US government, sometime over the next two years. it's very tough for me to see how they accept the existence of this kind of threat. but this adds a whole new class of governance issues, as then we've handed these extremely wide-reaching capabilities from private entities to public ones.