پن کیا گیا ٹویٹ

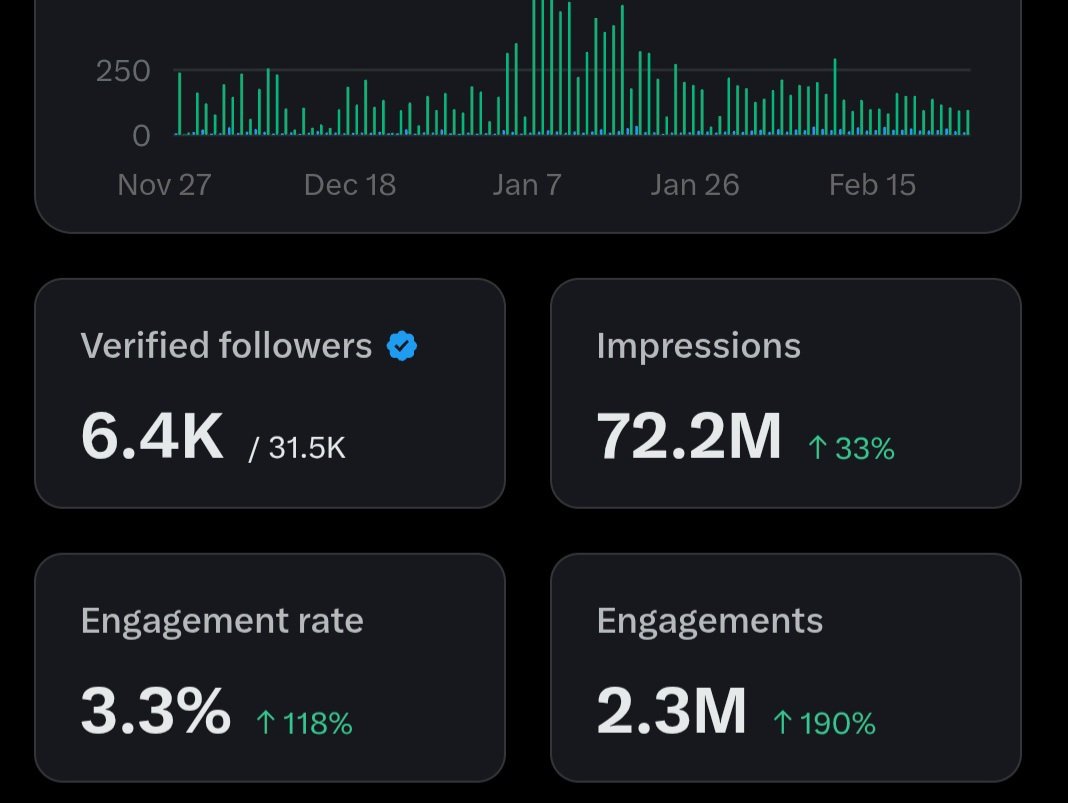
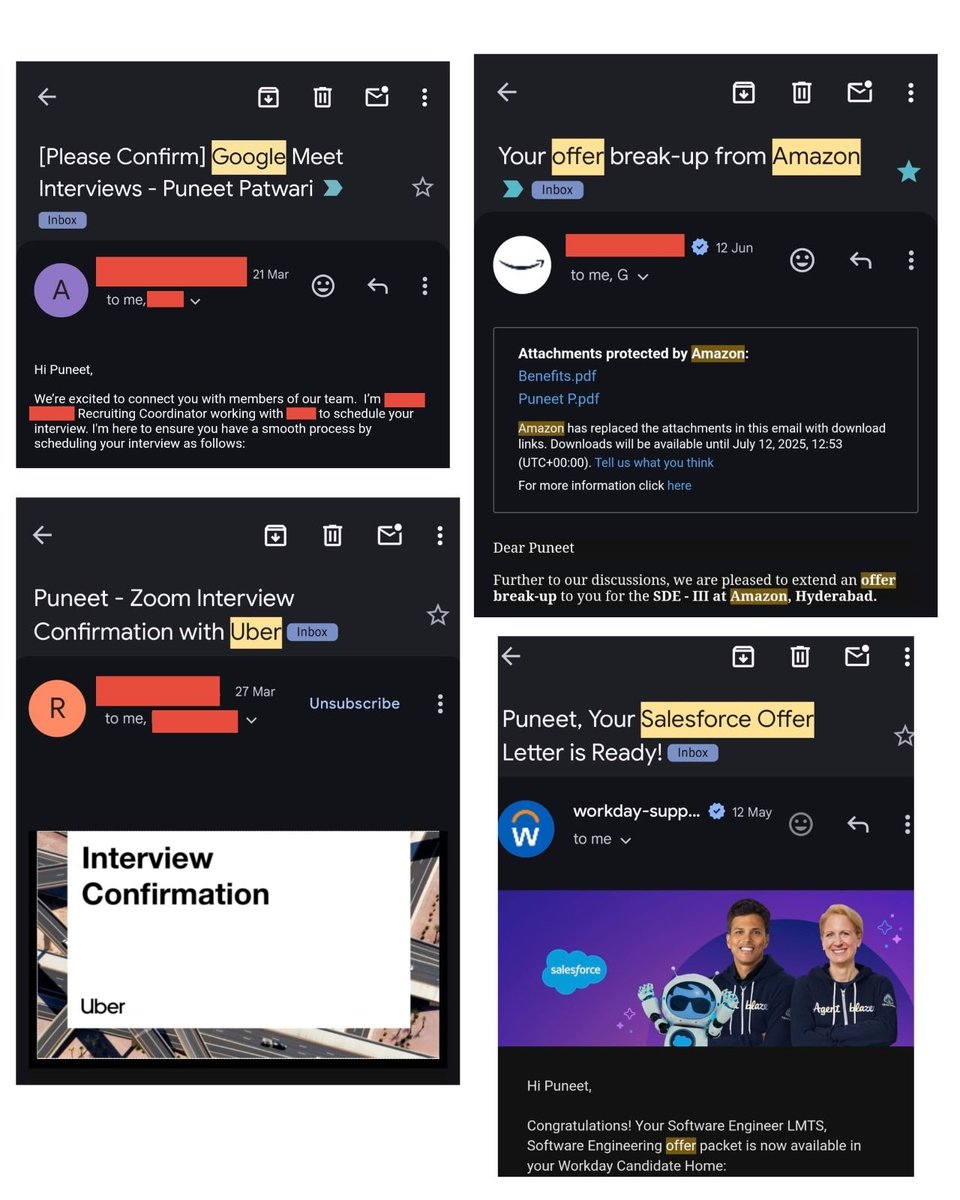
I interviewed at Google, Uber, Walmart, Amazon and several top startups (a total of 60+ interviews) during my job search from March to June 2025 before joining Atlassian as a Principal Engineer.
Here’s what each experience taught me. If you’re prepping for a switch, I hope this gives you clarity on what to expect (and how to survive the roller coaster):
English