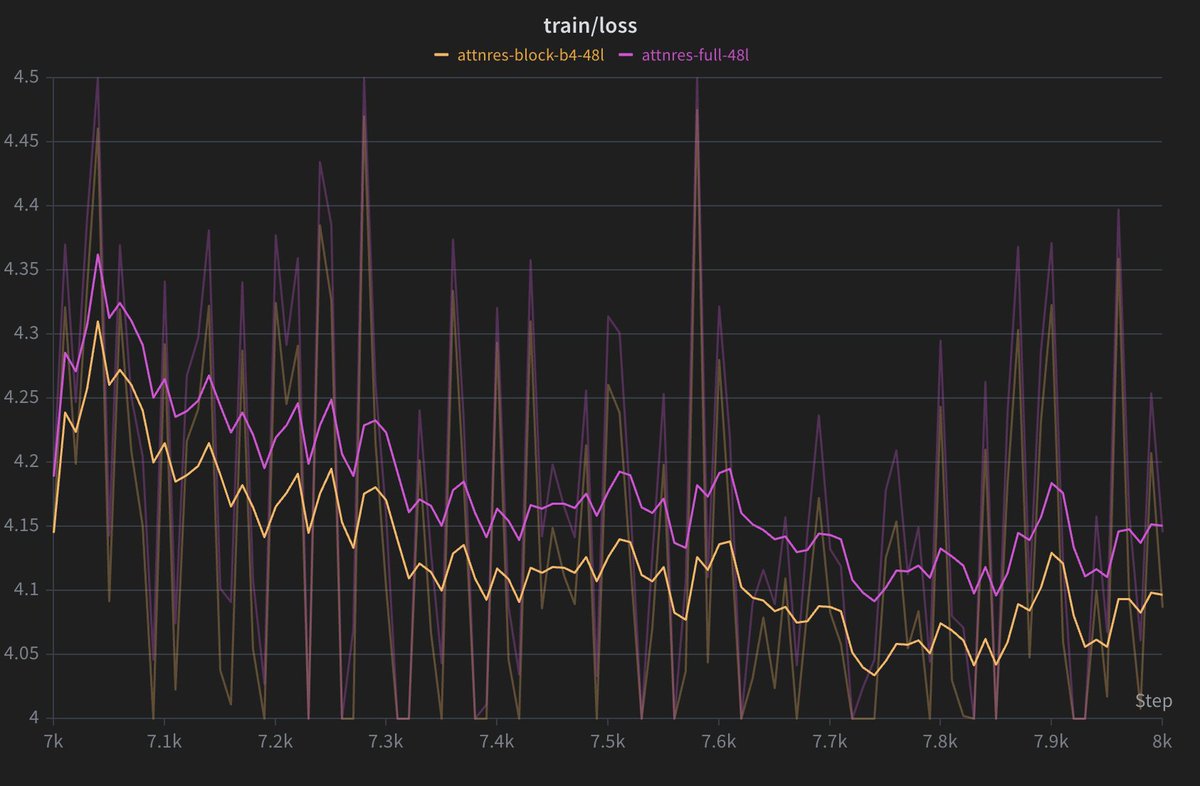
@Yuchenj_UW > I can summon my autoresearch army to win it… if I have time.
the point of autoresearch is that it won't really need much of "your time".
English
tokenbender
13.5K posts

@tokenbender
making gradients flow • eXperiments lab • heart, soul and brilliance