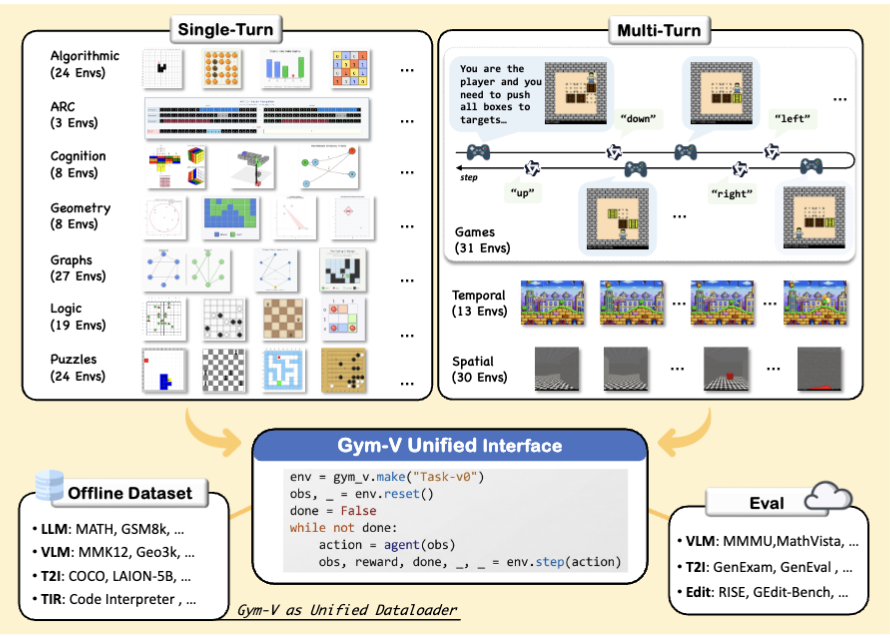
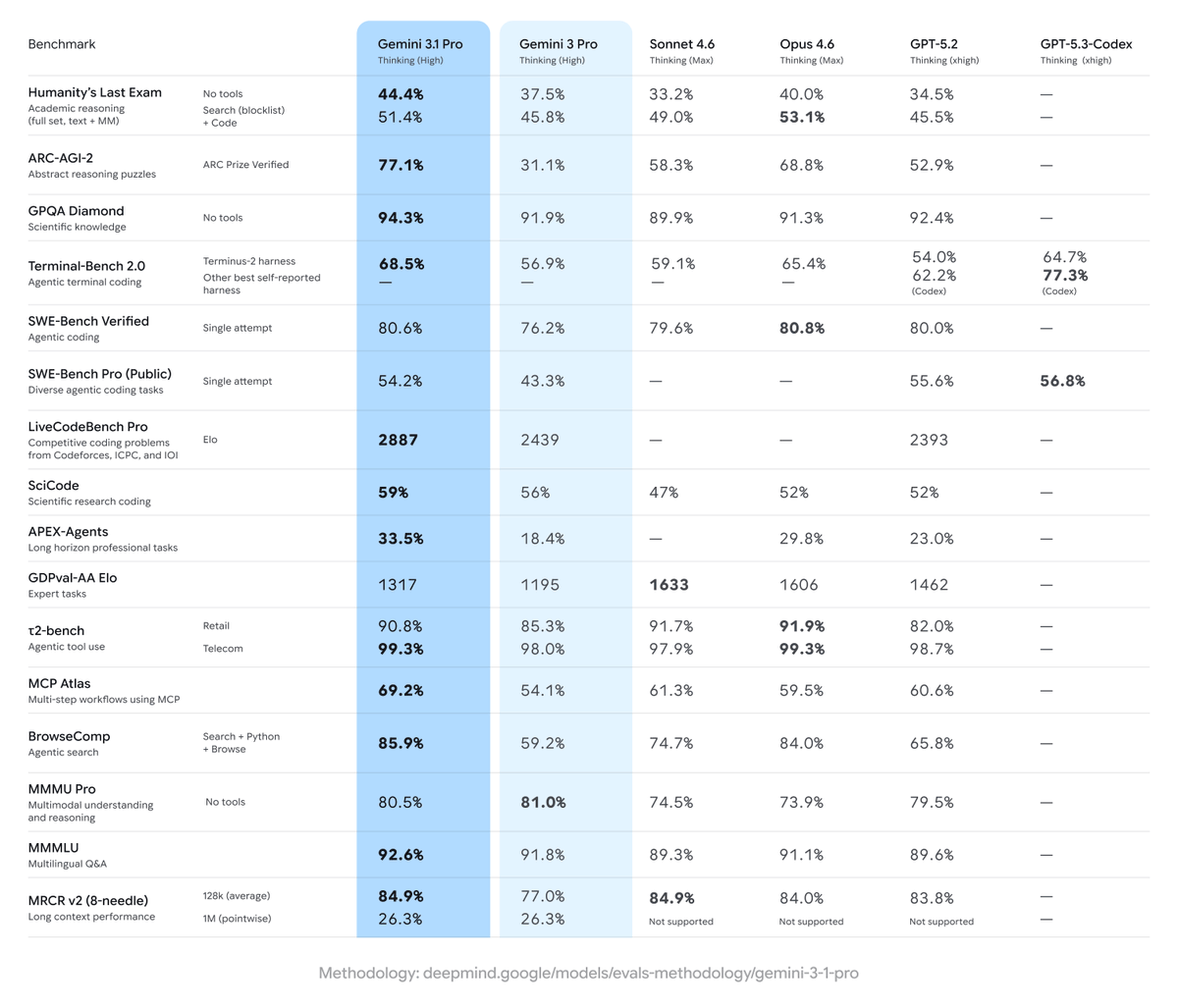
پن کیا گیا ٹویٹ

🪂Understanding R1-Zero-Like Training: A Critical Perspective
* DeepSeek-V3-Base already exhibits "Aha moment" before RL-tuning??
* The ever-increasing output length in RL-tuning might be due to a BIAS in GRPO??
* Getting GRPO Done Right, we achieve a 7B AIME sota!
🧵
📜Full details: github.com/sail-sg/unders…
🛠️Code: github.com/sail-sg/unders…

English