Tweet ghim

New blog: Testing the Datadog Explain Plan Visualizer with Oracle execution plans
tanelpoder.com/posts/testing-…

English
Tanel Poder 🇺🇦
16.9K posts

@TanelPoder
Creator of https://t.co/w1Pz4s2EhV and a long time computer performance nerd. Performance & Troubleshooting Training: https://t.co/lRKHSCFE6M













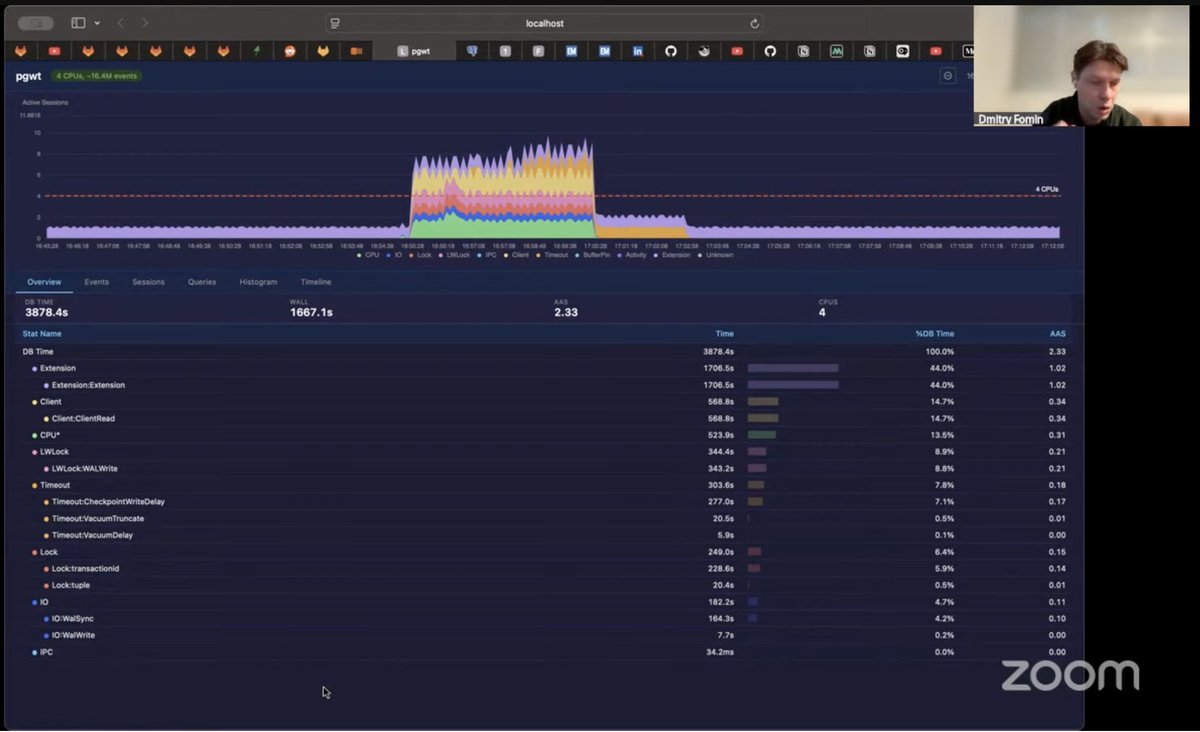
Postgres hacking session today youtube.com/watch?v=3Gtuc2… – LIVE now, join we have a great guest, Dmitry Fomin, who will show us some really cool new tool with wait event analysis (aka ASH) for heavily loaded systems






