置顶推文

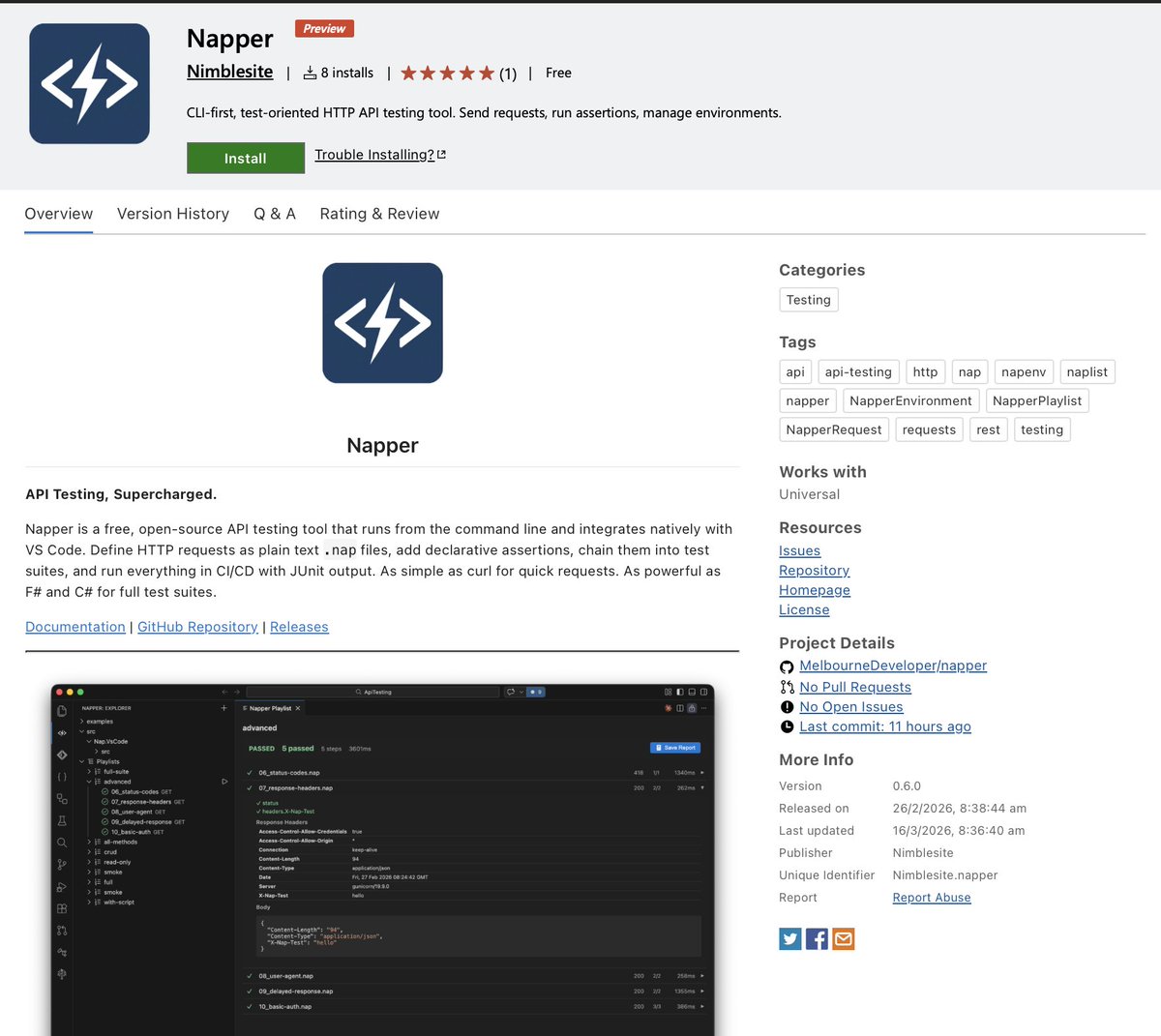
And here it is!!! My new programming language Osprey! This has been a 20 year long dream, finally made possible with AI assistance. So stoked this is finally possible! 🎉
Stars and shares appreciated! ✨
ospreylang.dev
English
Christian Findlay
45.1K posts

@CFDevelop
#Flutter 💙 #dotnet | Agitating for improvement and crusading against nonsense as Director of @nimblesite
Just two humans having a perfectly natural conversation.


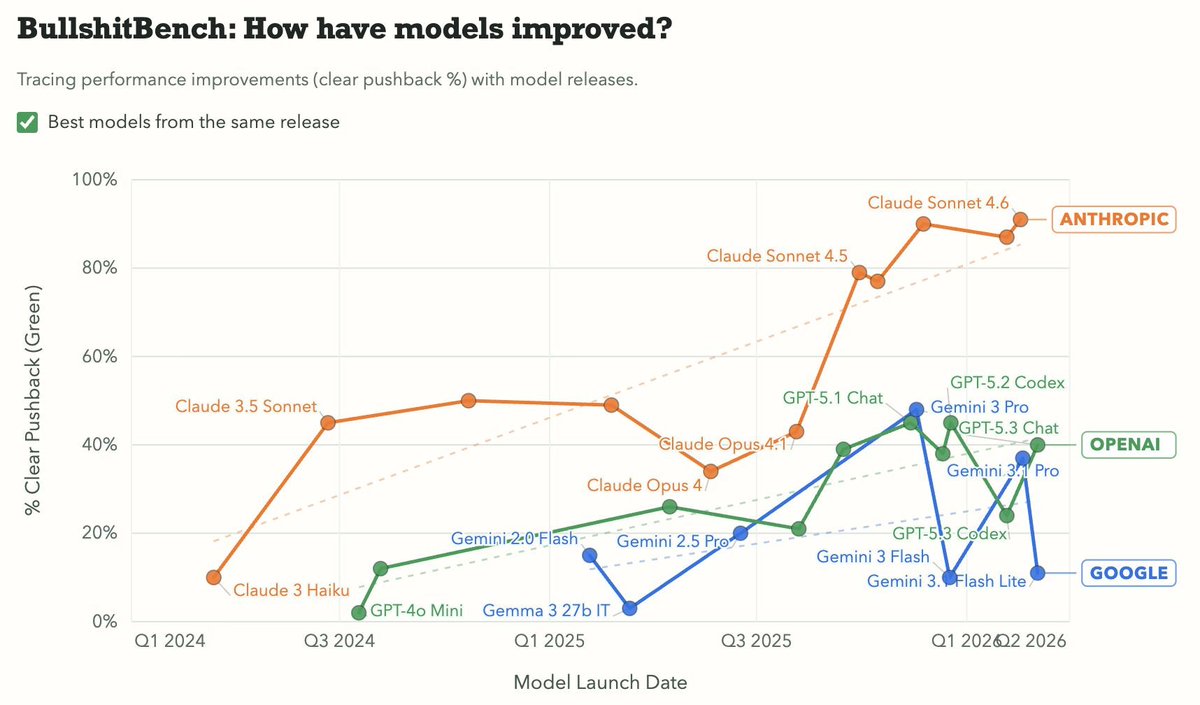












A small thank you to everyone using Claude: We’re doubling usage outside our peak hours for the next two weeks.




aussies have max intelligence Claude/Codex at all times. i made a post recently about how Claude Code's 2x limits are perfect for aussies and i got reminded that we always code during off-peak hours, so we literally never get the dumber versions or experience high-load crashes