Owais
1.4K posts


Owais
@alshell7
CTO @VoxemeAI | Architecting AI that actually ships ✨ | Tinkering HCI with ML | Reposting breakthroughs, breakdowns & mild AGI anxiety 👀
Bangalore 加入时间 Temmuz 2019
547 关注60 粉丝

Looking for a team of 10-12 cracked researchers & engineers to build a new AI Lab in India.
Funding and compute secured.
DMs open.
English

A lot is happening at Command Code right now, and it feels incredible. Y'all will love our June launches. Stay tuned.
English
Owais 已转推

New paper: Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
We use RL to post-train speech models (Moshi and PersonaPlex) to talk more like a human: to know when to respond, when to wait, and when to nod along with “yeah”s and “okay”s when listening.
English
Owais 已转推


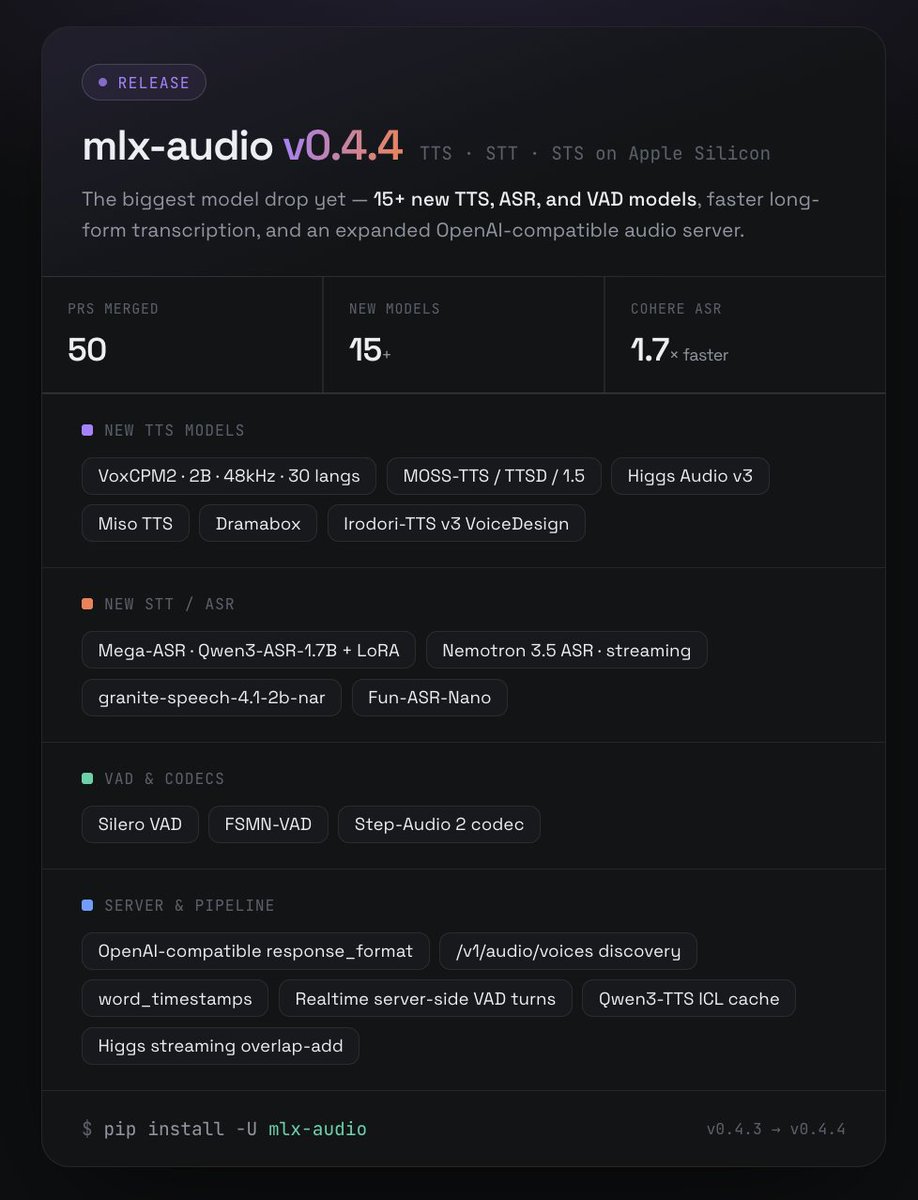
🚀 mlx-audio v0.4.4 is out — our biggest model drop yet.
15+ new TTS, ASR & VAD models, faster long-form transcription, and an expanded OpenAI-compatible audio server. All running local on Apple Silicon.
🎤 New TTS
• VoxCPM2 — 2B, 48kHz, 30 languages
• MOSS-TTS / TTSD / 1.5
• Higgs Audio v3
• Miso, Dramabox, Irodori-TTS v3 VoiceDesign
📝 New STT/ASR
• Mega-ASR (Qwen3-ASR-1.7B + LoRA routing)
• Nemotron 3.5 ASR (streaming)
• granite-speech-4.1-2b-nar, Fun-ASR-Nano
• Cohere ASR — 1.7× faster long-form
🔊 VAD & codecs: Silero VAD, FSMN-VAD, Step-Audio 2
⚙️ Server: OpenAI-compatible response_format, /v1/audio/voices, word timestamps, realtime server-side VAD turns h/t @lllucas
Huge thanks to all the contributors 🙏
> uv pip install -U mlx-audio
github.com/Blaizzy/mlx-au…
English

The next evolution of Hermes Agent is here!
Introducing Hermes Desktop: everything you love about Hermes, now native on your machine.
First demoed in Jensen's GTC keynote, it's now in public preview.
English
Owais 已转推


Owais 已转推

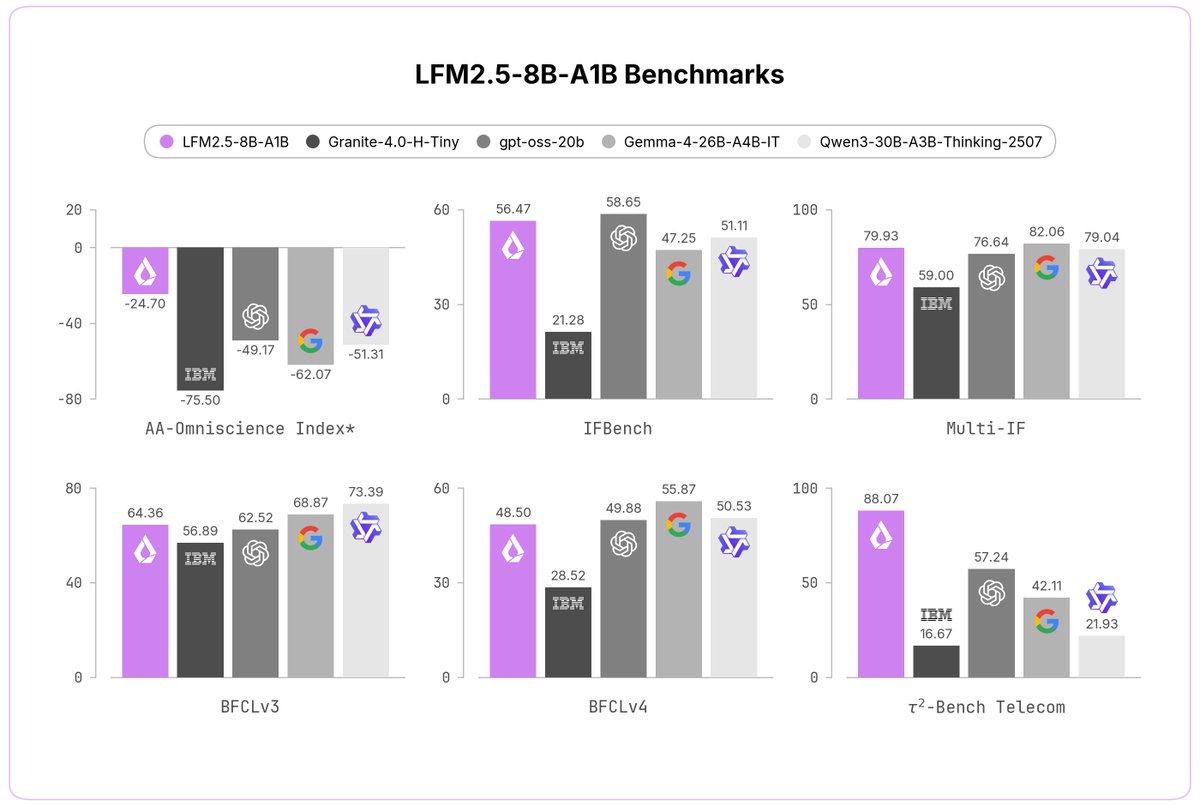
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
English
Owais 已转推

Qwen3.7-Max is live! 🚀
Introducing the latest proprietary model, built for advanced agentic coding, complex reasoning, and long-horizon execution. It’s here to transform how we approach complex tasks.

English
Owais 已转推

Just added in smol-audio: a reproducible NeuTTS Nano recipe for new languages. Want a TTS model in your own language?
- NeuCodec dataset encoding
- fine-tuning CLI + notebook
- Inference script
Change the phonemizer + dataset and train your own TTS model. Italian example includes a 300k samples/around 1000 hours of audio YODAS/Granary config.
English
Owais 已转推

open sourcing Marlin-2B 🐟
a tiny VLM to extract structured information from videos
Marlin is finetuned for two questions devs want to ask in their videos: what is happening, and when?
Best open model in its weight class, competitive with Gemini-2.5-flash at only 2B params 🧵
English
Owais 已转推

Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
English
Owais 已转推

GPU shortage is worse than ever.
H100s cost more today than they did 3 years ago, and you cannot get them on-demand.
The big AI labs have locked up most of the supply for years. I’m worried university researchers and individual developers simply won’t be able to get GPUs.

English
How I wish @CloudflareDev adds integration as a service to its developer ecosystem. I mean why not?
Today shipping integrations are a pain, of course Nango like open source solutions exist. But when you are attached to scalability & robustness being cost effective. Cloudflare has been the choice. I wish they would think about this anytime sooner.
@Cloudflare @dok2001
English
Owais 已转推
Today we release Token Superposition Training (TST), a modification to the standard LLM pretraining loop that produces a 2-3× wall-clock speedup at matched FLOPs without changing the model architecture, optimizer, tokenizer, or training data.
During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings on the input side and predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, it trains normally on next-token prediction. The inference-time model is identical to one produced by conventional pretraining.
Validated at 270M, 600M, and 3B dense scales, and at 10B-A1B MoE.
The work on TST was led by @bloc97_, @gigant_theo, and @theemozilla.

English
Owais 已转推

Me starting with LLMs:
"bigger GPU, more VRAM = faster inference"
Me now:
- VRAM bandwidth
- KV cache behaviour
- memory latency
- cache locality
- PCIe bottlenecks
- kernel efficiency
- quantization tradeoffs
- memory movement
Modern AI inference is basically systems engineering disguised as matric multiplication.
English
Owais 已转推

We are launching Ring-2.6-1T, a trillion-parameter flagship thinking model engineered for real-world complex tasks and production env: 🚀
- Adjustable Thinking Effort: dynamic compute mechanism to flexibly balance cognitive depth, token cost, and execution speed;
- Agent-Optimized: Built for high-frequency workflows, delivering rapid multi-step execution and tool orchestration with SOTA stability;
- Deep Thinking: Unlocks the model's maximum capability ceiling for rigorous mathematical logic and scientific research;


English
Owais 已转推

Introducing Mirage, a unified virtual filesystem for AI agents!
6 weeks. 1.1M+ lines of code. We rewrote bash from the ground up so cat, grep, head, and pipes work across heterogeneous services. S3, Google Drive, Slack, Gmail, GitHub, Linear, Notion, Postgres, MongoDB, SSH, and more, all mounted side-by-side as one filesystem.
Bash that AI agents already know works on every format! cat, grep, head, and wc parse .parquet, .csv, .json, .h5, even .wav! One pipe can stitch S3, Drive, GitHub, Slack, and Linear together, same Unix semantics throughout.
Workspaces are versioned too. Snapshot, clone, and roll back the whole thing with one API call. A two-layer cache turns repeated reads into local lookups, so agent loops stay fast and cheap.
Drop a Workspace into FastAPI, Express, or a browser app. Wire it into OpenAI Agents SDK, Vercel AI SDK, LangChain, Mastra, or Pi. Run it alongside Claude Code and Codex.
Site: strukto.ai/mirage
GitHub: github.com/strukto-ai/mir…
#AIAgents #OpenSource #AgenticAI #Strukto #Filesystem #VFS


English
Owais 已转推

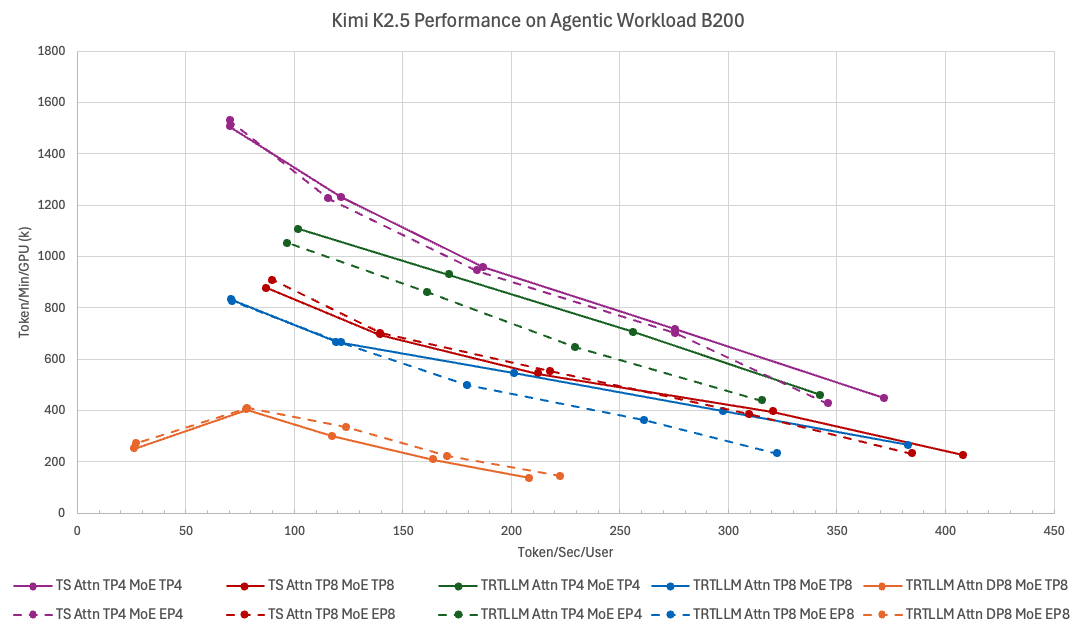
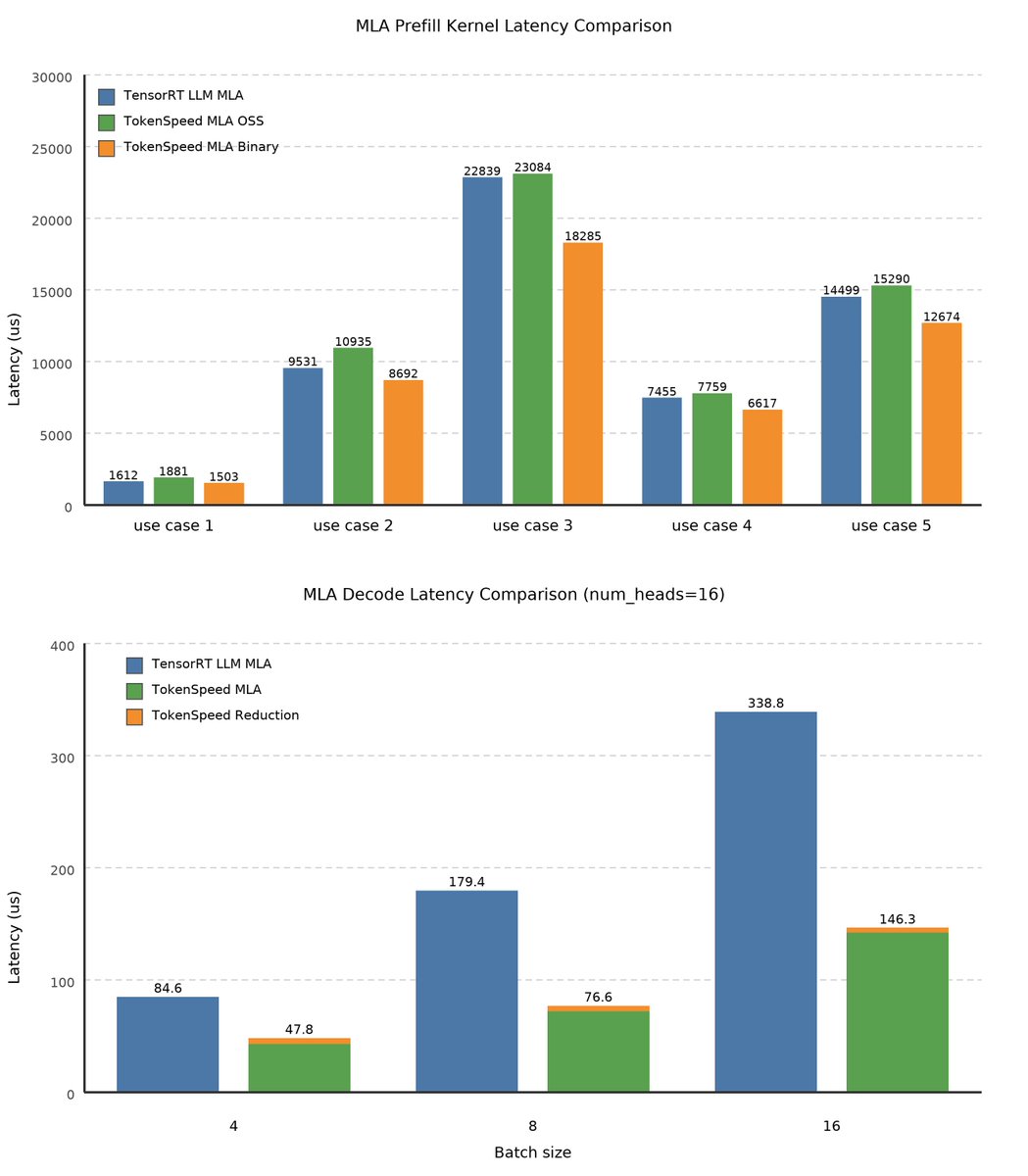
Introducing TokenSpeed, a speed-of-light LLM inference engine.
> TensorRT LLM level performance
> vLLM level usability
> Built by a lean and mission-driven team in two months
> MIT license, open-source
github.com/lightseekorg/t…
lightseek.org/blog/lightseek…
English