置顶推文

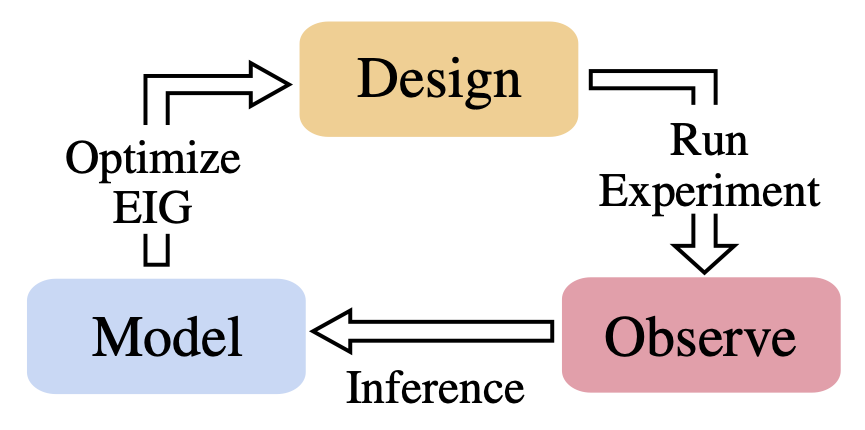
We've got really good at utilizing data. But methods for acquiring that data are often still rudimentary. Our new review paper shows how Bayesian experimental design has recently transformed to now provide a powerful mechanism to acquire data intelligently arxiv.org/abs/2302.14545
English