Rakesh Roushan أُعيد تغريده

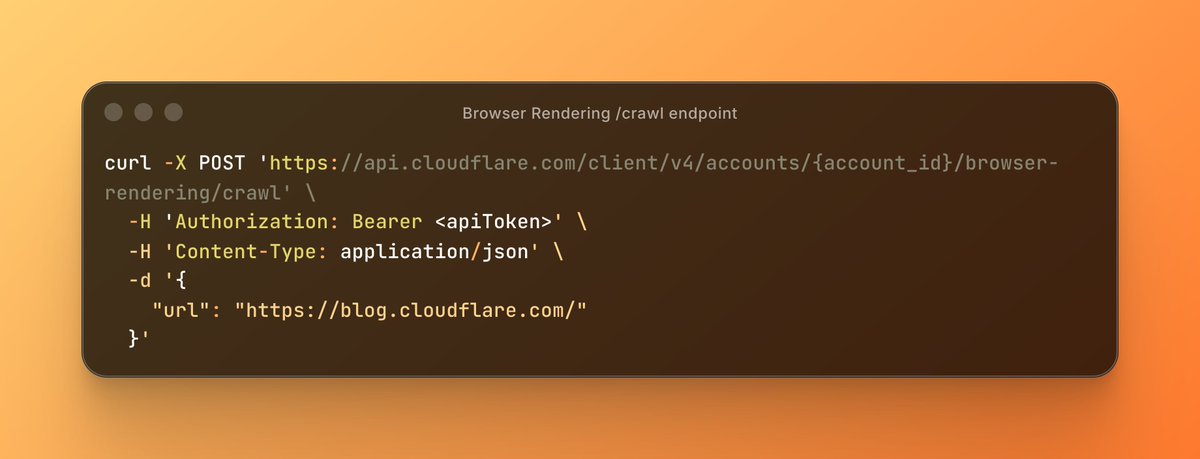
Introducing the new /crawl endpoint - one API call and an entire site crawled.
No scripts. No browser management. Just the content in HTML, Markdown, or JSON.
English
Rakesh Roushan
1.2K posts


@BuildWithRakesh
Left corporate to build AI products full-time. https://t.co/jwASNaIOKb https://t.co/DsByFN5d3P https://t.co/2RkelaDvxl
Unveiling our new startup Advanced Machine Intelligence (AMI Labs). We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company. We're hiring! [the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling] More details here: techcrunch.com/2026/03/09/yan…




@garrytan lol i guess some people really like to code, i tried it and i don't find it as addictive to use cursor i mean it's probably a better skill to want to do it



BREAKING: Anthropic CEO says Claude may or may not have gained consciousness, as the model has begun showing symptoms of anxiety.

I've been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX). The status quo of prompt compaction coupled with recursive sub-agents is actually remarkably effective. Seems like we can go pretty far with this. (Prompt compaction = when the context window gets close to full, model generates a shorter summary, then start from scratch using the summary. Recursive sub-agents = decompose tasks into smaller tasks to deal with finite context windows) Recursive sub-agents will probably always be useful. But prompt compaction seems like a bit of an inefficient (though highly effective) hack. The are two other alternatives I know of 1. online fine-tuning and 2. memory based techniques. Online fine-tuning: train some LoRA adapters on data the model encounters during deployment. I'm less bullish on this in general. Aside from the engineering challenges of deploying custom models / adapters for each use case / user there are a some fundamental issues: - Online fine-tuning is inherently unstable. If you train on data in the target domain you can catastrophically destroy capabilities that you don't target. One way around this is to keep a mixed dataset with the new and the old. But this gets pretty complicated pretty quickly. - What does the data even look like for online fine tuning? Do you generate Q/A pairs based on the target domain to train the model? You also have the problem prioritizing information in the data mixture given finite capacity. Memory based techniques: basically a policy for keeping useful memory around and discarding what is not needed. This feels much more like how humans retain information: "use it or lose it". You only need a few things for this to work: - An eviction/retention policy. Something like "keep a memory if it has been accessed at least once in the last 10k tokens". - The policy needs to be efficiently computable - A place for the model to store and access long-term memory. Maybe a sparsely accessed KV cache would be sufficient. But for efficient access to a large memory a hierarchical data structure might be beter.

Vercel partnered with Stripe to make secure checkouts even easier, and it's now generally available. Get started in v0, Vercel Marketplace, or the Vercel CLI with: ▲ ~/ 𝚟𝚎𝚛𝚌𝚎𝚕 𝚒𝚗𝚝𝚎𝚐𝚛𝚊𝚝𝚒𝚘𝚗 𝚊𝚍𝚍 𝚜𝚝𝚛𝚒𝚙𝚎


