
@project_oren The solo AI builder path is underrated. What is the one problem you are solving that nobody seems to have fixed yet?
English
StackAI
46 posts

@HelloStackAI
🚀 Democratizing AI training data. High-quality synthetic training data for researchers & startups. Fine-tune LLMs without hyperscaler budgets. 🧪



looking at the data

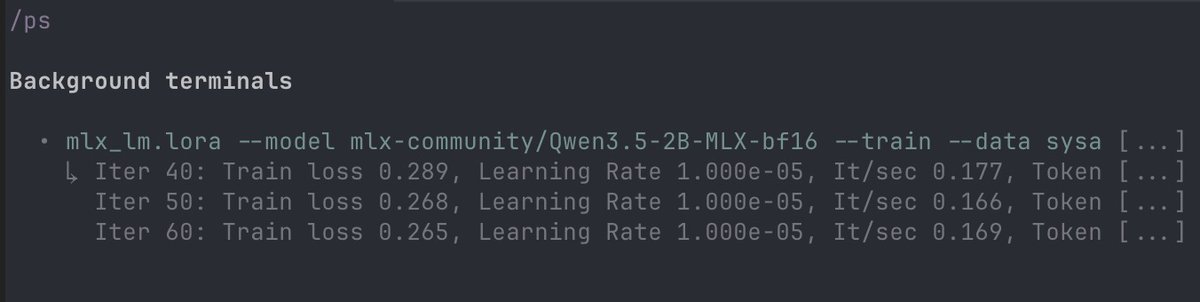
the model got worst after fine tune nice






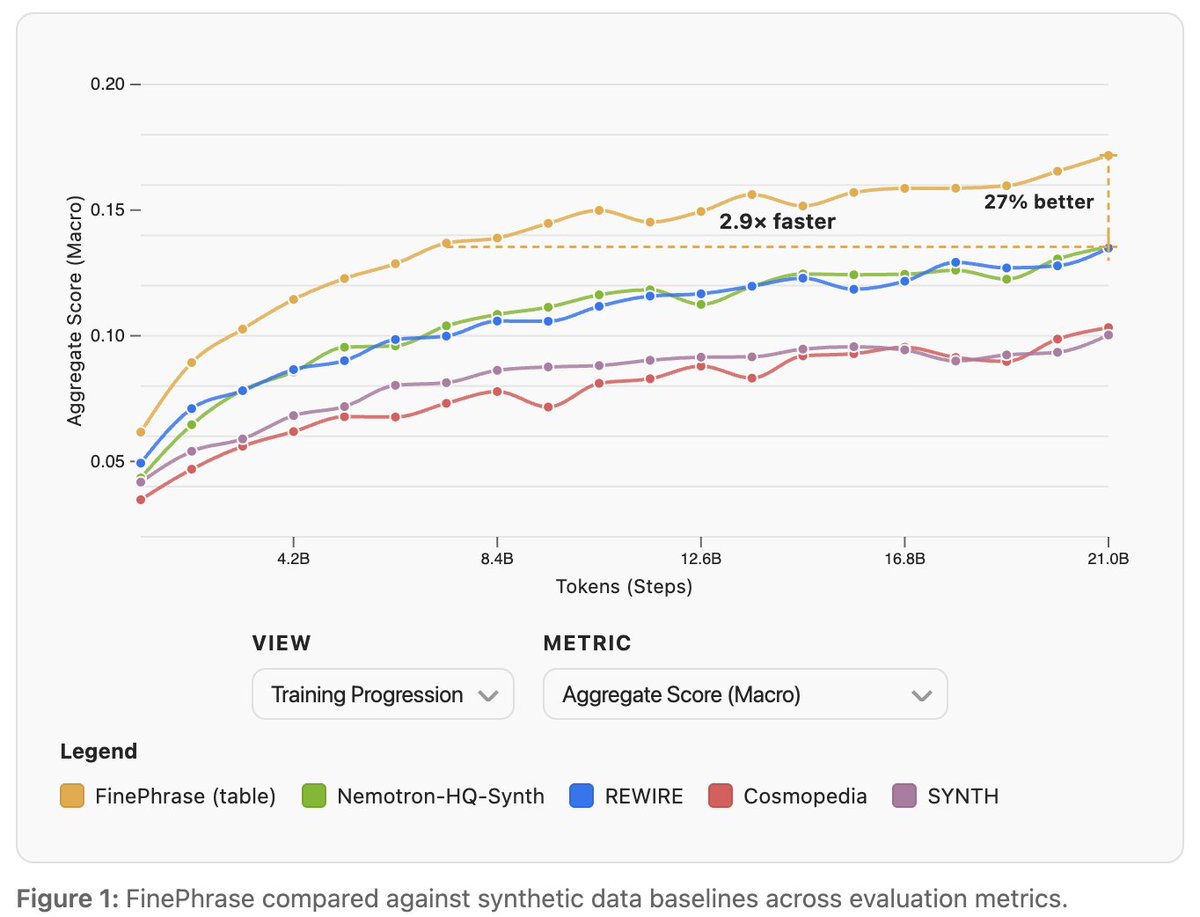

Anthropic’s moat is synthetic data engineering Their coding models are fundamentally better because they rely principally on pretraining not RL They’ve never particularly even tried to hide this





Happy to share our work: Real-World Point Tracking with Verifier-Guided Pseudo-Labeling. #CVPR2026 We improve the pseudo-label training pipeline for real-world videos using a verifier that selects the most reliable predictions across multiple trackers. 🔗kuis-ai.github.io/track_on_r




