Gregor Simm@gncsimm
MLFFs 🤝 Polymers — SimPoly works!
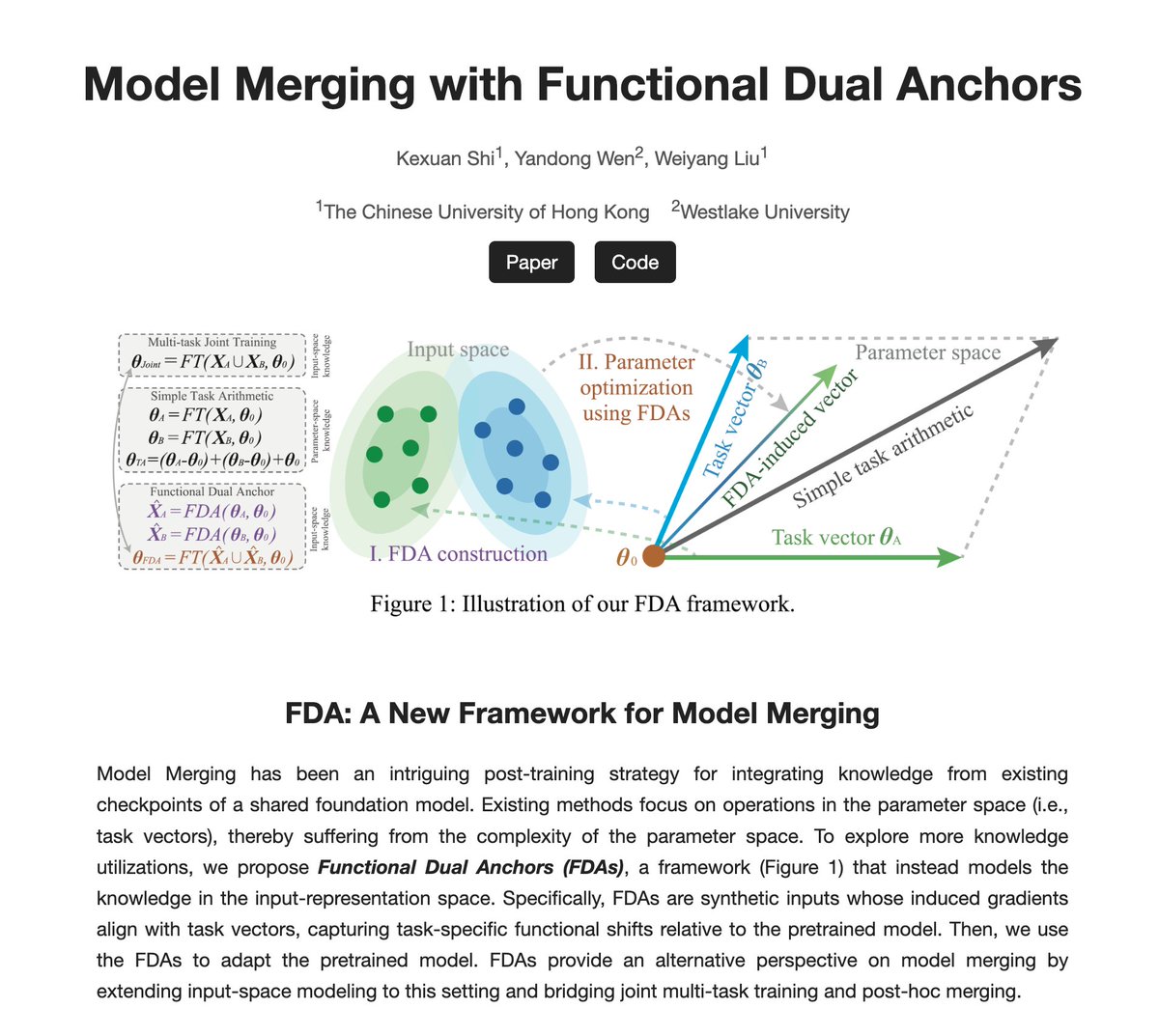
Our team at @MSFTResearch AI for Science is proud to present SimPoly (SIM-puh-lee) — a deep learning solution for polymer simulation.
Polymeric materials are foundational to modern life—found in everything from the clothes we wear and the food we consume to high-performance materials in aerospace, electronics, and medicine. Today, we introduce a new way to simulate them.
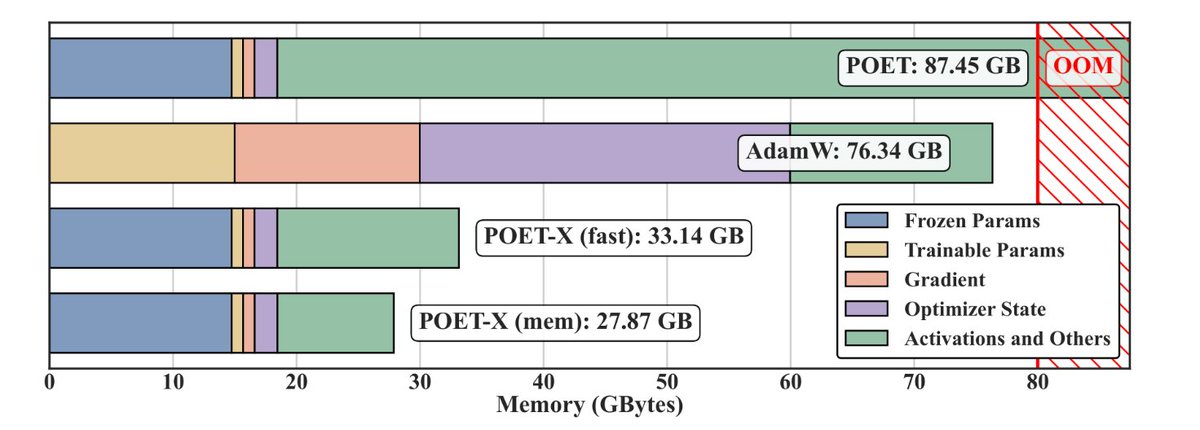
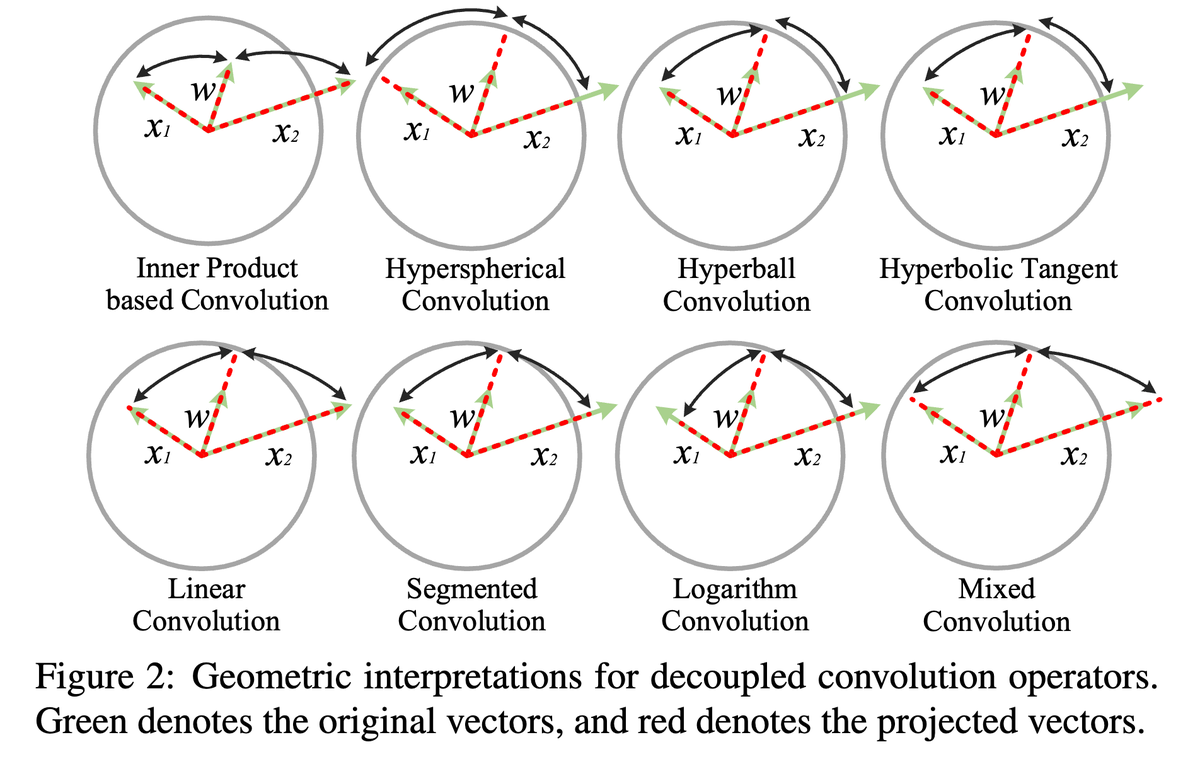
We built a machine learning force field (MLFF) to predict macroscopic properties across a broad range of polymers—trained only on quantum-chemical data, with no experimental fitting. Specifically, we accurately compute polymer densities via large-scale MD simulations, achieving higher accuracy than classical force fields. We also capture second-order phase transitions, enabling prediction of glass transition temperatures. These two properties are fundamental to processing and application design. Finally, we created a benchmark based on experimental data for 130 polymers plus an accompanying quantum-chemical dataset—laying the foundation for a fully in silico design pipeline for next-generation polymeric materials.
The incredible team: Jean Helie, @temporaer, Yicheng Chen, Guillem Simeon, @a_kzna, @ErnestoCheco, @erunzzz, Gabriele Tocci, @chc273, @yatao_li, @SherryLixueC, @zunwang_msr, Bichlien H. Nguyen, Jake A. Smith, and Lixin Sun.
📄 Preprint: arxiv.org/abs/2510.13696
⚙️ Data and code release: in progress⏳
#MLFFs #Polymers #AIforScience #DeepLearning #SimPoly #ScientificML #Microsoft #MicrosoftResearch #MicrosoftQuantum