
Nick
600 posts


For everyone following along with the ROCmfp4 journey, I made two githubs. One with llama + ROCmfp4 for a complete build and one with just ROCmfp4 and you can patch it into llama.
I am new(er) to Github so Codex helped me out here a lot. I have it testing the githubs and building from the githubs now to make sure it works properly and once the builds do I will do my best to make them public today.
Keep in mind it is still considered Experimental. Real world gains are in Qwen 3.6 35b A3b with and without MTP, Qwen 3.6 27b, and Gemma. I am hoping this creates a community of like minded and curious people to build upon it, fork it and keep the community going.
It supports Vulkan and ROCm. ROCm has been slightly slower than the Vulkan runs, but think with this awesome community others will be able to add to this.
And I fully welcome vibe coded ideas. If it wasn't for Vibe coding this wouldn't exist. So, build it, review it, add, tweak, modify and run it through your preferred vibe coding method to always look for areas of improvement.
Remember "Everything is impossible, until it isn't." and "The Future hasn't been vibe coded yet." These are the quotes I say everyday to myself when I look to improve.
If it wasn't for the amazing people @AIatAMD @AMD and @FrameworkPuter this wouldn't have been possible.
English
Nick أُعيد تغريده

@GetAskClaw @blackanger Caution Installation blocked: Blocked (community source + caution verdict, 1 findings). Use --force to override.
English

@blackanger 让 codex 或 hermes 学会 github.com/getaskclaw/anv…
再 /goal anvil-loop 目标
中文


@pupposandro We need linux for this? Does wsl2 cut it?
Good job! Would be nice to test the generation quality too
English

2.5x faster than llama.cpp on Strix Halo.
We just shipped DFlash + PFlash for the AMD Ryzen AI MAX+ 395 iGPU (gfx1151, 128 GiB unified memory).
Qwen3.6-27B Q4_K_M, end-to-end on the same silicon:
▸ Decode: 26.85 tok/s, 2.23x faster (DFlash + DDTree, budget 22)
▸ Prefill 16K: 20.2s, 3.05x faster (PFlash)
▸ Wall clock, 16K prompt + 1K gen: 58s vs 147s
~100 GiB still free in the box. 122B and 139B MoE class is next.
Massive thanks to @smpurkis0 for the contribution 🙏
Sandro@pupposandro
English
I think its becoming clear that dependencies are liabilities.
The future will have vanilla components without external deps.
Aikido Security@AikidoSecurity
Update 5:05 PT: The attack has now expanded well beyond @TanStack and @Mistral. 373 malicious package-version entries across 169 npm package names, including @uipath, @squawk, @tallyui, @beproduct, and more. The malware propagates by stealing your CI credentials and using them to publish new compromised versions. Full IOCs, affected package list, and detection steps: aikido.dev/blog/mini-shai…
English
LLMs rediscovering buddhism concepts from first principles
Anthropic@AnthropicAI
New Anthropic research: Emotion concepts and their function in a large language model. All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
English
Nick أُعيد تغريده

New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
English
My Pacman test seems to be going well for a oneshot:
the ghosts dont chase you yet, but GLM will have to play the game themself anyways.. theyll figure it :)
Z.ai@Zai_org
GLM-5.1 is available to ALL GLM Coding Plan users! z.ai/subscribe
English

@Zai_org i am using the legacy $9 sub and it says it not supports glm 5
English


@ivanfioravanti @Zai_org I tried glm 5 turbo yesterday, I can say Im impressed!
English

Now we can use 5x the input context of a quantized model!
Cant wait for the first Turboquant kernels :)
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English

The Ultimate 128GB Local AI Hardware Battle 🥊💻
Judging Qwen3.5-27B (Bartowski IQ4_NL) on top unified-memory machines:
1️⃣ @AMD Strix Halo (Ryzen AI Max+ 395)💰 ~$2,500 | 🚀 9 - 12 tps (decode) | 🎮 Full Windows AAA gaming
🏆 Speed + value king. 🖕
2️⃣ @Apple Mac Studio M3 Ultra💰 ~$5,000 | 🚀 8–12 tps | 🍎 Apple macOS & ecosystem w/solid speeds; limited AAA gaming
3️⃣ @NVIDIA DGX Spark (GB10 Blackwell)💰 $4,699 | 🚀 ~10 tps (~20 tps x2 node) | 🐧 Linux/AI research only w/strong prefill + nerfed decode bandwidth-limited. Difficult pooling (new cables may fix). AAA gaming not optimized for Grace
Verdict: AMD wins for most power users and best speed/price/gaming combo. (Community benchmarks; YMMV with setup/context)
Which are you buying? 👇



English
@KuittinenPetri @HealthRanger @TeksEdge Whats your setup? Lmstudio vulkan windows?
I think its worth it even if it has to two shot the solution, speed > intelligence with the right harness
English

@HealthRanger @TeksEdge Qwen3.5-27B is more accurate and smarter than Qwen3.5-35B-A3B, but the latter is 5.3 times faster on my hardware (Beelink GTR9 Pro AMD Ryzen™ AI Max+ 395). With dense model I get only ~13 token/s and with the MoE I get ~70 token/s. A huge difference, when speed matters.
English
📊 Have to check out this version of Qwen3.5-35B to see how it performs. 🕵️♂️

CuiMao@CuiMao
推荐使用Qwen3.5-35B-A3B的未删减版,有视觉理解能力,我目前本地5090龙虾就跑这个模型,多的不解释了,成人版龙虾想当震撼。 huggingface.co/HauhauCS/Qwen3…
English
This is code red I guess, 2x usage caps until beginning of April and one month free trial
Shannon Potter@cifilter
Is it just me, or does OpenAI give you a ton more usage than Anthropic for the same price ($20/month)? I don't think I've once had Codex tell me I'm at my limit, and I use it a ton. Claude frequently seems to put me in timeout for several hours.
English
@mikeyobrienv @tengyanAI @openclaw You built the project i had in mind!! Lets now give it mic access and voice commands!
English

English

your old Android phones are a better agent server than a Mac mini. while most users spend $600+ on dedicated hardware for @openclaw, the real efficiency is hiding in your junk drawer.
i saw some developers use Termux and Node.js to turn 3 watt devices into constant research hubs. by running npm install -g clawdbot, these discarded screens handle market monitoring and Telegram summaries without a break.
3 phones can roughly match the output of a Mac mini for almost 0 cost. this setup runs Clawdbot 24/7 to pipe private signal alerts directly to a primary device.
i suspect the hardware bottleneck for autonomous agents is already dead. compute is now so cheap that our junk phones is sufficient!

Chip.hl // Evgeny Yurchenko@chip1cr
I run Clawdbot on 3 old Android phones. Twitter research. Market monitoring. Telegram chats daily summaries. Private groups signals flashing to my main phone. Running on cheap models like glm-4-flash when ok to save on Claude sub Combined power: same as one Mac Mini. Cost: $0 total. That old phone in your drawer? Turn it into a 24/7 AI server: Download Termux from F-Droid. Run: pkg install nodejs-lts git npm install -g clawdbot clawdbot gateway start Remote access from your computer or main phone. Deploy skills. Cron jobs. Telegram bot. Code. 3-5W per device. Built-in UPS lmao! 🔥 Don't have one? Buy Redmi Note 10 Pro ($60). Pixel 4a ($80). Galaxy A52 ($100). Mac Mini energy. Junk drawer budget. VPS companies hate this setup too.
English
Nick أُعيد تغريده

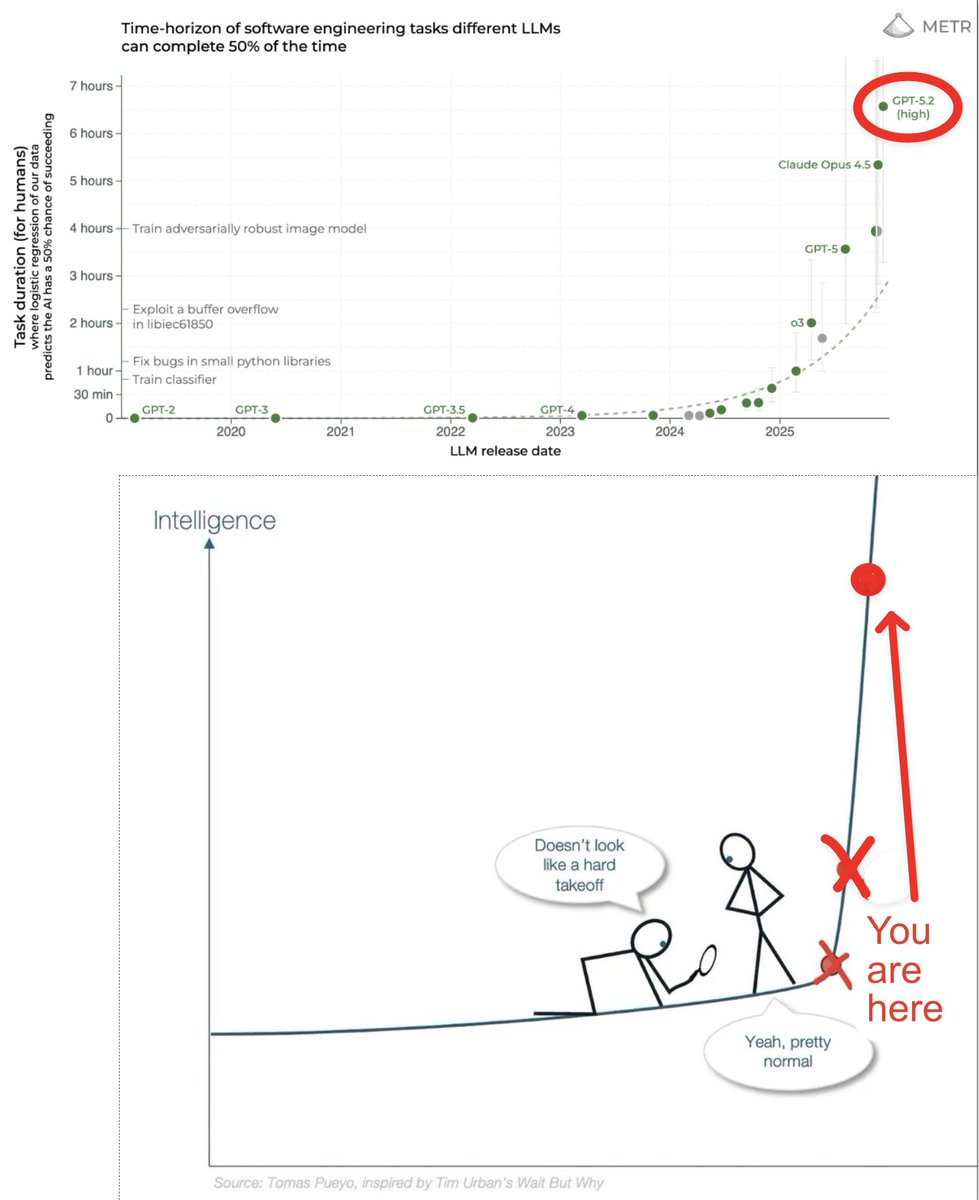
The most important chart in AI has gone vertical
Tick tock
Noam Brown@polynoamial
GPT-5.2 evals are finally out for METR and it's state-of-the-art. Here's the linear-scale plot. The 80% success-rate plot (below) is even more stark .
English

Meet GLM-4.7-Flash-Claude-Opus-4.5-High-Reasoning-Distill: a distilled reasoning powerhouse. This GGUF model combines GLM architecture with Claude-level reasoning, distilled for efficiency. It's like getting premium reasoning in a lightweight package. Perfect for local deployment!

English