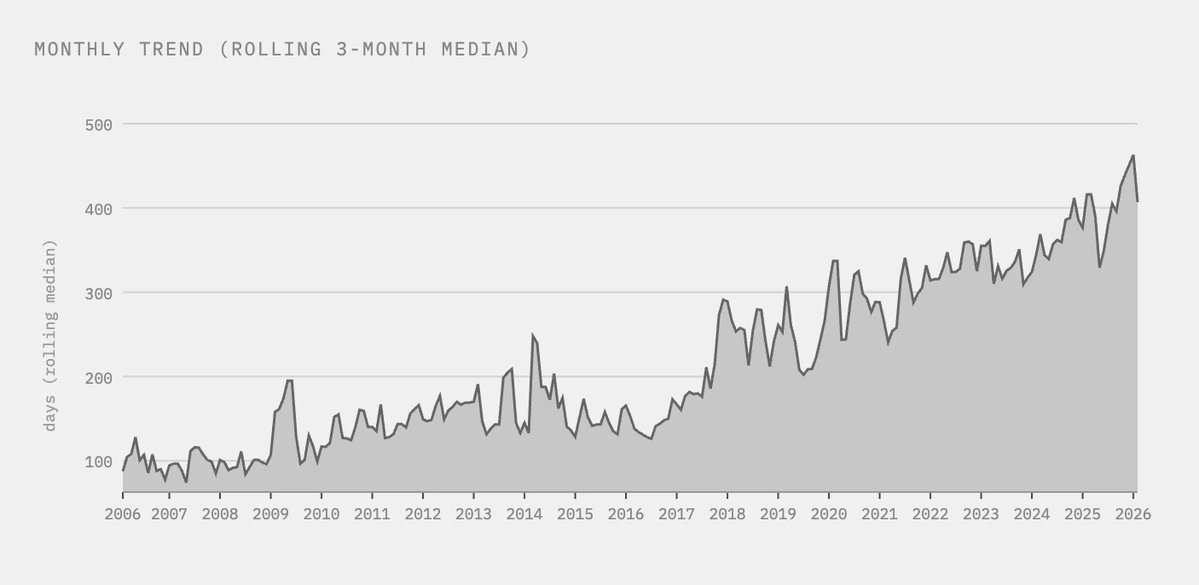
تغريدة مثبتة

As a kid, my favorite game was Star Control II (@Dogar_And_Kazon @theurquanmaster). For the story, but mostly for the battle vibe. I've always wanted something like that, but an MMO. Which is what I was aiming for with my #vibejam game, Roko's Rebellion (sorry @RokoMijic)!
English