
Pratham Patel
22 posts

Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.

English


@N_and_ni Anthropic is loved by users and hated by competitors
English


All personnel are accounted for and safe. It’s too early to know the root cause but we’re already working to find it. Very rough day, but we’ll rebuild whatever needs rebuilding and get back to flying. It’s worth it.
English


@Aditya_181105 It's due to India's IT sector as it is service based and not much R&D is done here, data scientists aren't rewarded or in demand compared to AI Engineers.
English


@MertLovesAI Hey man, I want to understand it at a technical level can you help me understand it or point towards resources which can help me understand it?
English

Gemini Omni just collapsed the seam every video model has had since Sora: the gap between the model that knows what the world looks like and the model that renders it.
One controller. Swap angle. Swap detail. Same scene.

English

@theprath Not that I’m aware, for one of my projects I needed to solve that problem, albeit with not as high of precision. I find myself thinking about ways to do it still with more precision even though my use case in that moment didn’t require it.
English
Open challenge: given a sphere with a radius r and a number of points n, distribute those points on the sphere to where the variation in distance between neighboring points is less than .001% across the whole sphere for any given n. Been thinking about this problem in bed lately.
English
@thsottiaux Can you ship codex for android it would be better if I will be able to do coding from my smartphone.
English


@chrisgpt Would be crazy if it would run for let's say 2 months, and by then we would already have gpt-5.6, later it runs for 5 months, then we have gpt-6 and repeat.
Never truley knowing how good each modeel is.
English

Rumor has it they are still evaluating GPT 5.5 on goal mode because it won’t stop
Dan McAteer@daniel_mac8
wen GPT-5.5 on @METR_Evals?
English

@haider1 a model can be objectively better and still feel like a disappointment if the narrative around it was misaligned
English

openai fumbled the gpt-5 release
but this, gpt-5.5 aka spud, looks like something they should have called gpt-6, since it seems to match what anthropic claims mythos can do
but at a fraction of the cost
i think oai is probably being too cautious after the gpt-5 release
English
@Dorialexander You can read about the explanation of the full paper here mathematically.
prathamp.com/blog/deepseek-…
English

So DeepSeek-V4: finally took me the week.
Overall the paper is attempting many things at once, not easy to disentangle as it's all surprisingly connected.
It's first a serious attempt at briding the gap between close and open LLM architecture. It is generally rumored that Opus and [largest model bundled in GPT-5] belong to an entirely different category of models: very large, very sparse mixture of experts, able to holding an unprecendently wide search space while still being servable. Simply put current hardware cannot hold a model on one node, so you have to play with the interconnect and various level of quantization, for different layers, at different stage of training. An important focus of DsV4 is on communication latency, showing it can be hidden through effective management of interconnect (roughly you slide communication time inside computation side). Overall, you cannot simply enter this game without the capability to rewrite kernels from scratch and the model report relentlessly come back to this. Because this is the frontier game.
It's then a radical, but very successful attempt at making long context simultaneously more efficient and more affordable. Long context is literally a "context" problems: what exactly is worth attending? An obvious fix is to prioritize the most recent tokens. This might be sufficient for basic search but not for the new demands of agentic pipelines that require accurate recall of distant yet strategic content. V4 clever approach is to rely on two different axis of memorization by allocating layers to two different attention compression schemes. Like the name suggest, Heavily Compressed Attention is the brute force method collapsing each sequence of 128 tokens to a unique entry and take care of the fuzzy yet global context. Compressed Sparsed Attention rely on a "lighting indexer" to bring the relevant local blocks for query, even when they can be thousands of tokens away. Everything here is optimized for end inference: there is very large head_dim (512) which is costlier for training but allows for even more compressed kv cache which is your actual bottleneck at inference time, especially in prefill mode. End result is very classical DeepSeek play, introducing a new radical disruption of inference economics after DSA. I predict hybrid CSA/HCA (or similar counterparts) will be essentially part of the mainstream arch by the end of this year.
Now we come to the more ambitious but also more unfinished part: an attempt at redefining model architecture and the learning signal. Most preeminent part is mHC and hybrid CSA/HCA, but it's actually a long list of less documented innovations: swapping softmax for sqrt(softplus) or using an hybrid two-stage scheme with non-standard values for Muon. Yet the interconnection all of these new components is still unknown and likely to account for the significant training unstabilities: typically "mHC involves a matrix multiplication with an output dimension of only 24" which introduces non-determinism. Even one the best AI labs in the world will run here into ablation combinatorial explosion, so the association of all these choices is likely non-tractable and would require a more consistent theory — which the conclusion gestures at, but does not solve ("In future iterations, we will carry out more comprehensive and principled investigations to distill the architecture down to its most essential designs"). The more limited experiments in post-training are maybe more promising. Significantly, the one lab that popularized the standard RL+reasoning recipe is rethinking the recipe. For now it's a two stage design (RL on specialized model, then on-policy distillation): ever since Self-Principled Critique Tuning DeepSeek has been concerned with expanding the reasoning training signal beyond final sparse reward. I'm not sure this is final say: in this domain everything is a bit in flux and you could even argue the type of verified pipeline we designed for SYNTH is a form of extreme offline RL-like training.
There is an even longer term plan (here >3-5 years), which is about redefining hardware. For now it's a way of transforming a constraint into an opportunity: as the leading Chinese labs, DeepSeek was very incentivized to make training work on Ascend and contribute to the national effort for chips autonomy. Very unusually, the report includes a lengthy wishlist for future hardware to come in the report itself. As several experts noted, many of these recommendations don't really hold up for Nvidia but make perfect sense for a newcomer in the GPU hardware business. DeepSeek seem to be anticipating a world where labs have to secure a close hardware partner to retroactively fit the chips to the particular demand of model design or inference.
Now there is what DeepSeek did not do yet. The paper hardly mention anything about synthetic pipelines, rephrasing, simulated environment. Training data size (32T tokens) likely involve some significant part of generated data, as this is more quality tokens than the web and other digitized sources could held — so maybe similar synthetic proportions as Trinity (roughly half) or Kimi. Still, it's pretty clear that all their attention was focused on the infra, architecture and scaling side, leaving a proper extensive retraining for later. This is likely not that dissimilar to how Anthropic or OpenAI proceeded: the fact we're still in the middle of the same model series even though significant parts of the model have changed (the tokennizer with Opus 4.7) suggests that a model lifecycle involves multiple rounds of training potentially as large as a pretraining a few years ago. The fact DeepSeek took on multiple Moonshot innovation (and Moonshot in turn has been hugely reliant on DeepSeek) suggest we might also have an ecosystem dynamic here. Maybe DeepSeek can exclusively focus on hard infrastructure problems and expect some of the axis of development to be sorted out later.
English
@yacinelearning I have written about it here.
prathamp.com/blog/maxrl-fro…
English

if you are down to dive into a very technical topic this weekend that is both very simple and has high near term potential voilà 🫴

hallerite@hallerite
It has been quite some time since I was deeply impressed by an AI paper from academia..
English
@ashwathama @hiarun02 You guys have no idea how better codex is compared to claude
English

@hiarun02 cheaper per token yes
but on a complex codebase claude still finishes the task
English



the aura loss anthropic has suffered in april is insane
English

English

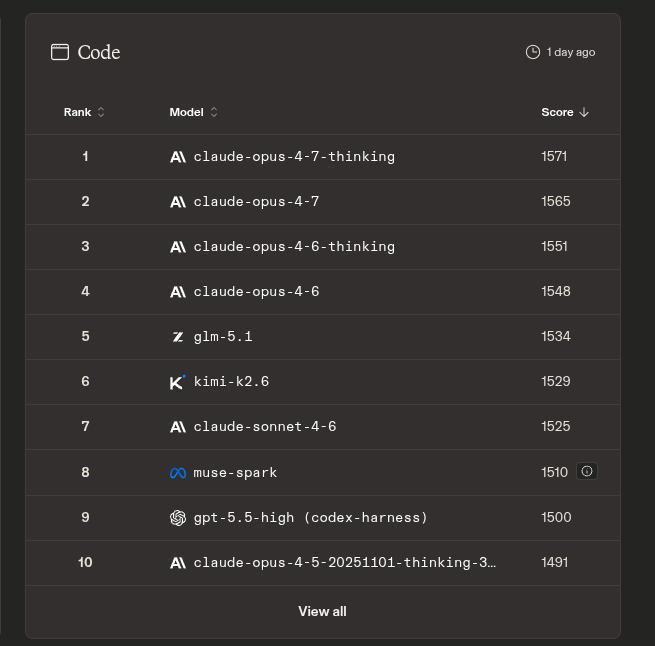

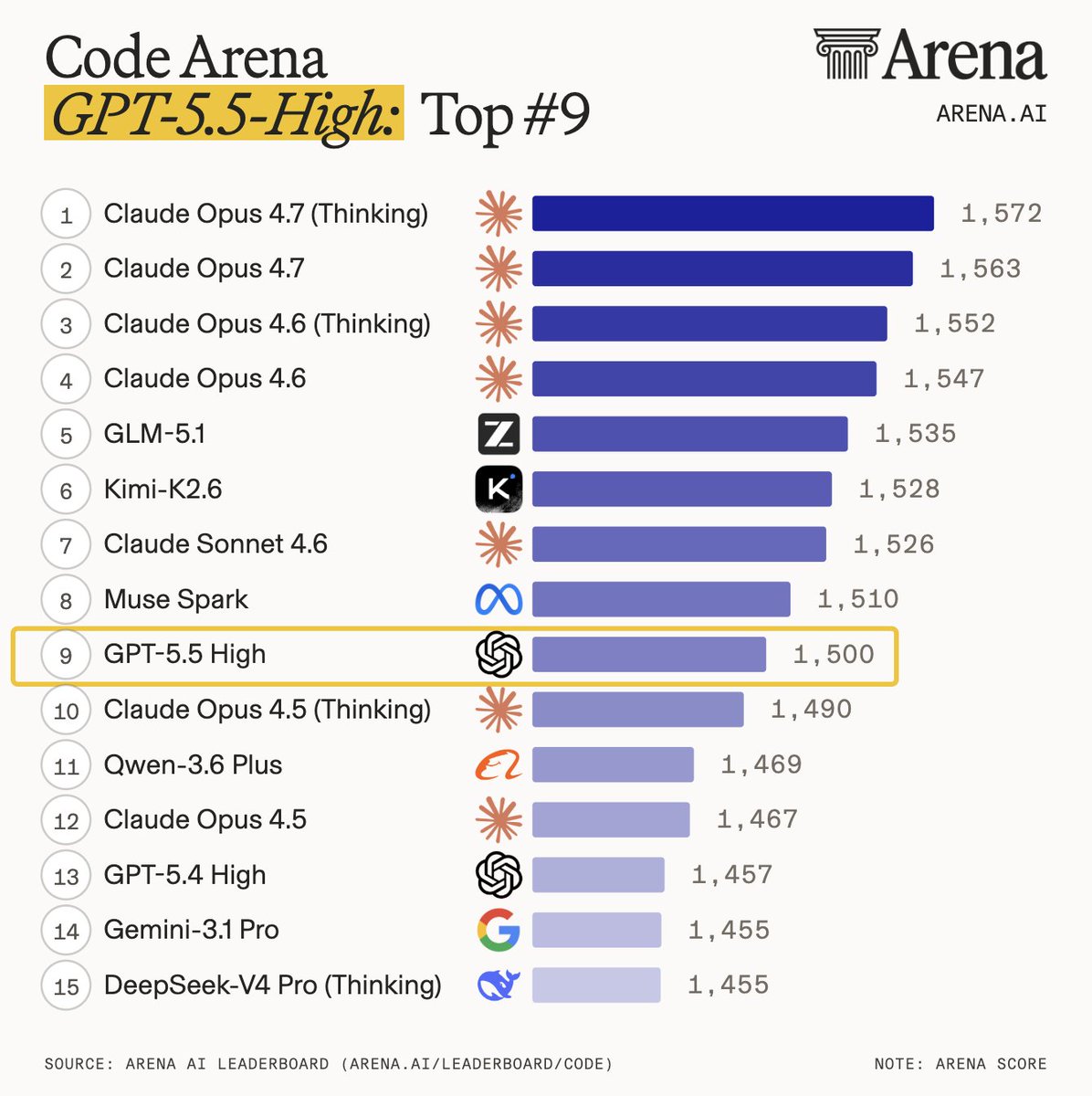
GPT-5.5 by @OpenAI is now live in the Arena, landing across multiple leaderboards.
Here’s how it ranks by modality:
- Code Arena (agentic web dev): #9, a strong +50pt jump over GPT-5.4
- Document Arena (analysis & long-content reasoning): #6, on par with Sonnet 4.6
- Text Arena: #7, Math #3, Instruction Following: #8
- Expert Arena: #5
- Search Arena: #2
- Vision Arena: #5
Strong, well-rounded performance, especially in Code (+50 pts vs GPT-5.4).
Congrats to @OpenAI on the release. Full category breakdowns by modality in the thread.
OpenAI@OpenAI
Introducing GPT-5.5 A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done. Now available in ChatGPT and Codex.
English