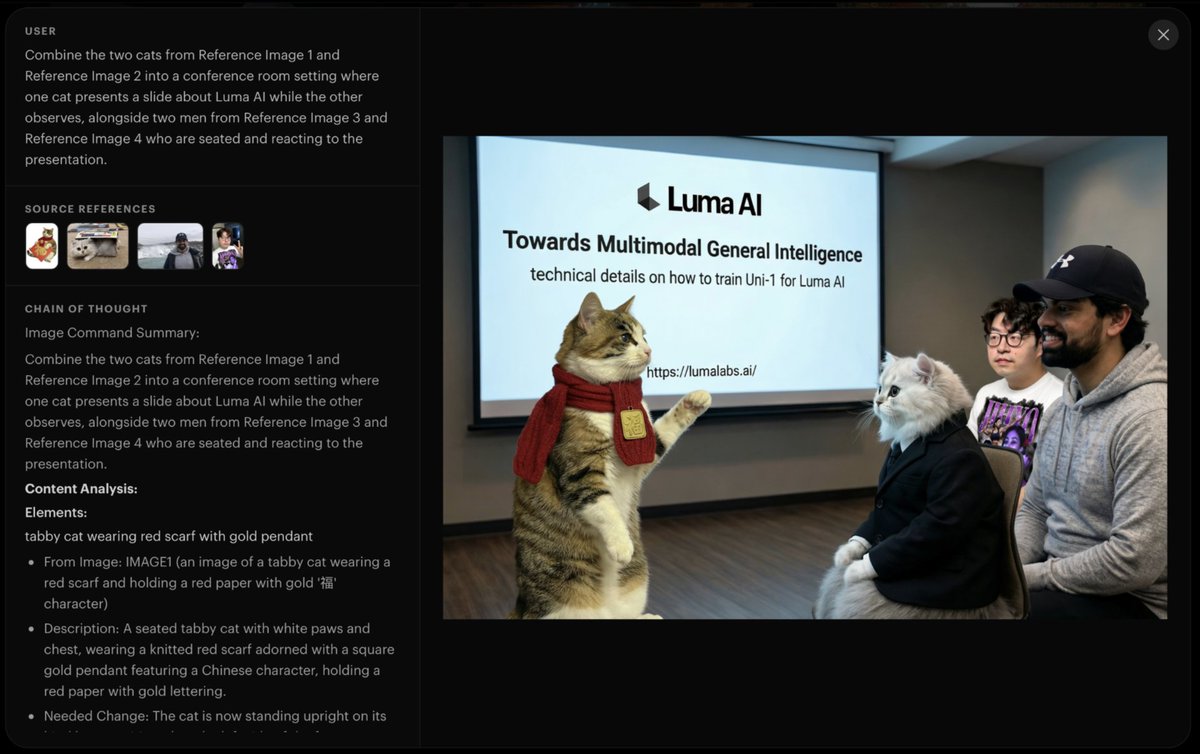
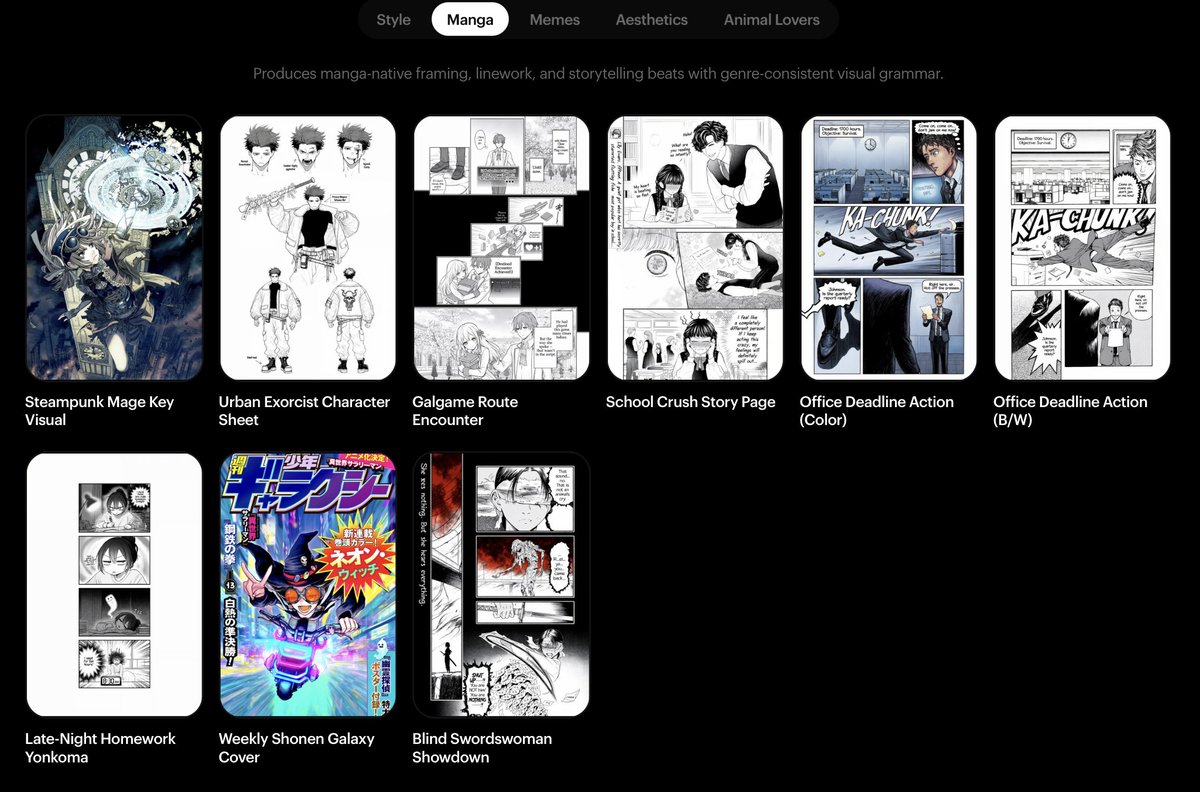
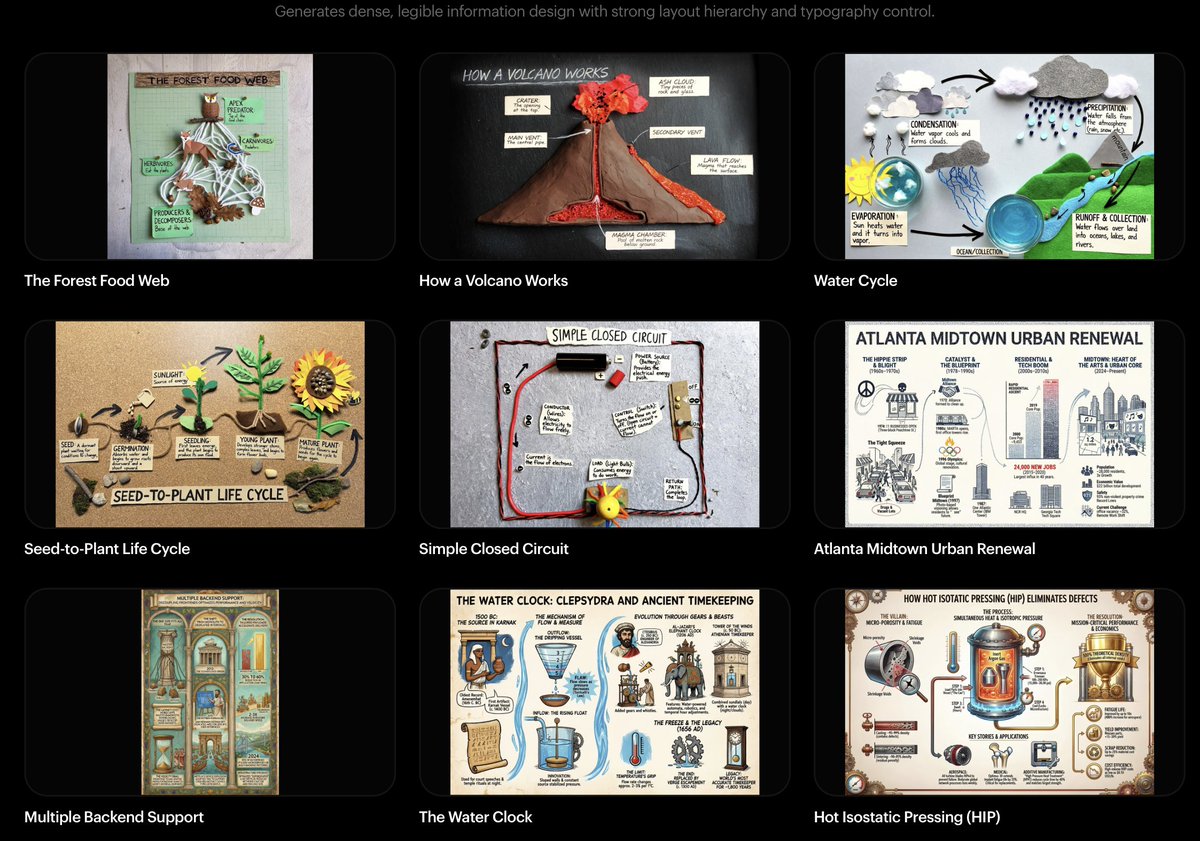
تغريدة مثبتة

1/8
🚀 AI Breakthrough: "Interpretable Diffusion via Information Decomposition" 🧠
- Quantitative understanding of conditional diffusion models.
- Align text-image data using mutual information.
- Goes beyond "attention".
🎉 Accepted at #ICLR2024!

English