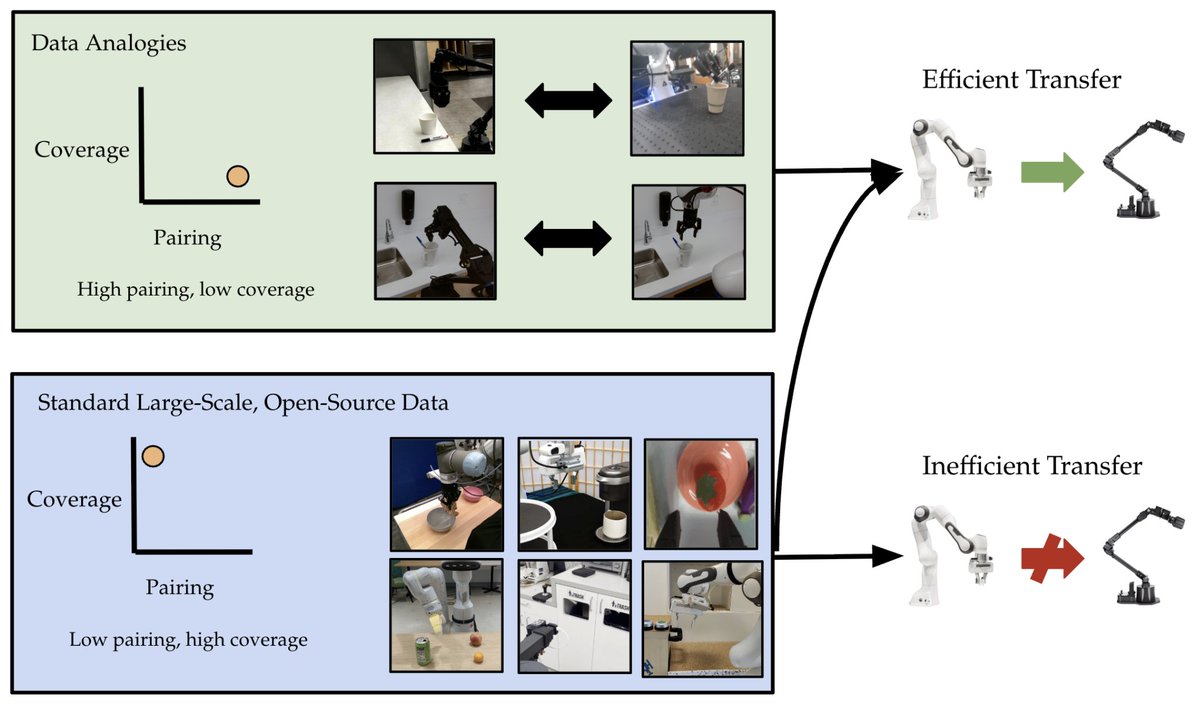
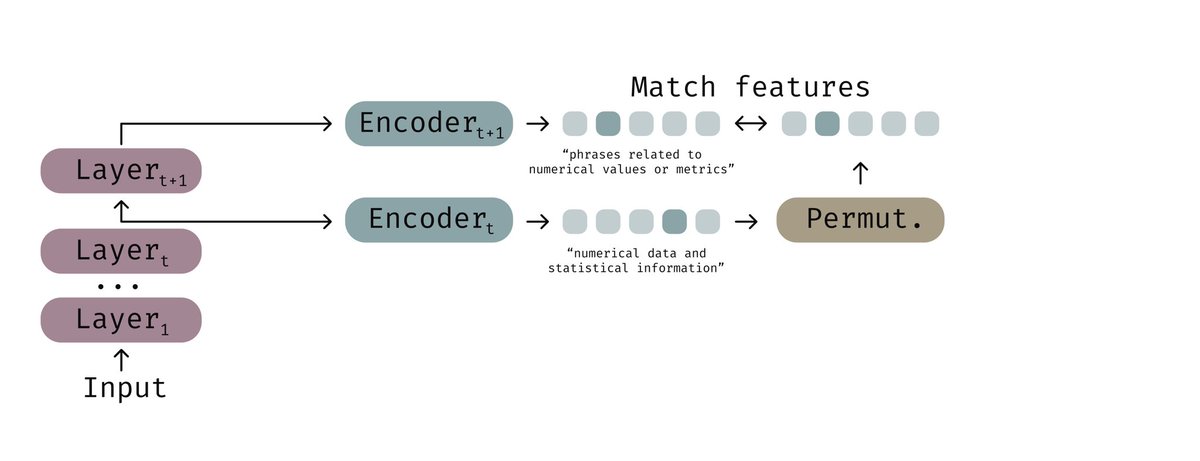
Angehefteter Tweet

Hi! 👋We’re Abaka AI, a global data partner in the AI industry!
We share daily insights from our experience working with 1,000+ top-tier AI labs and research institutions worldwide.
Whether it’s multimodal, evaluation, pre/post-training, or synthetic solutions, we cover the core components of a high-performing ML pipeline across domains.
In short,
Professional, top-tier data services with quick turnaround
Eg.,
Our contributed benchmarks are trusted by leaders like Gemini 3 and DeepSeek
Therefore,
Daily insights on data, eval, multimodal, annotation, etc.
Follow us for first-hand industry expertise! Peace!✌️
English