
callightman
359 posts

#ClaudeCode #LLM #OpenClaw
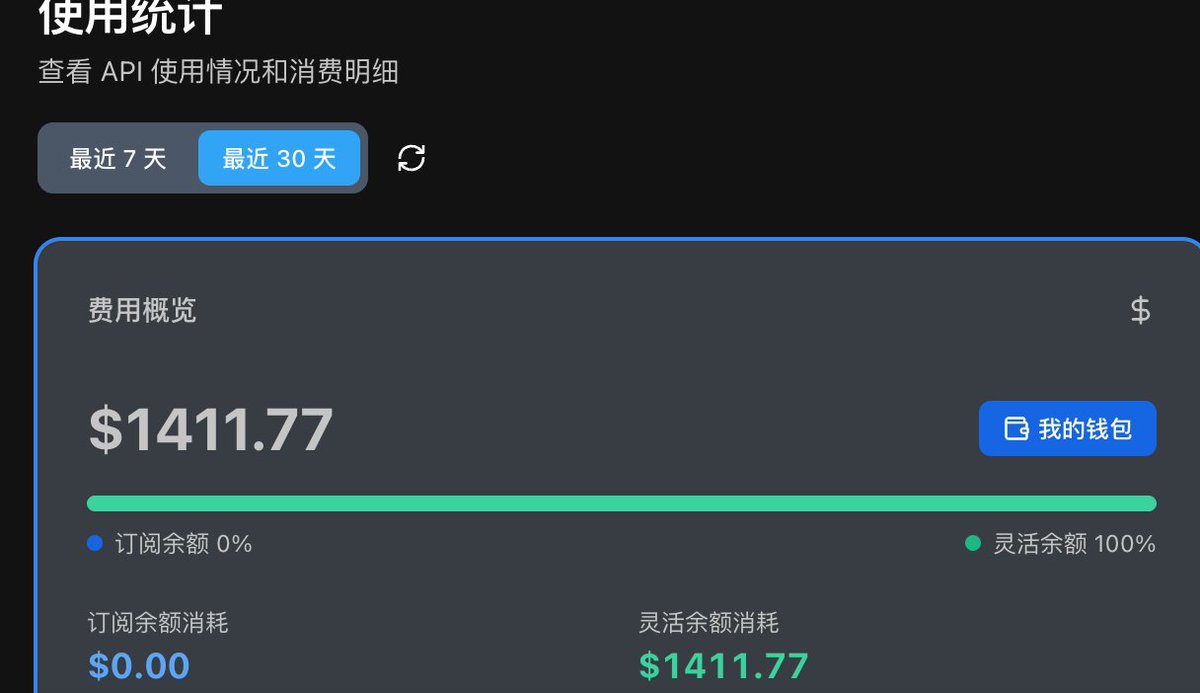
难得的安利帖:让你的Token减少、并发相应更快的神器——oMLX(仅苹果M系列芯片可用)
oMLX是专为Apple Silicon设计的开源MLX推理服务器,核心突破在于用SSD分页缓存解决了Mac跑本地大模型的致命痛点。传统工具如LM Studio在处理OpenClaw这类调用工具频繁的套壳时,每次都要重新计算20k+ token的系统提示词(相当于重读一篇万字长文)
它真正的创新在于:
1. 分层缓存架构:热数据存RAM,冷数据存SSD(按LRU策略),让16G内存的Mac Mini也能跑多开
2. 智能前缀缓存:相同系统提示词只存一份,不同用户会话共享基础缓存
3. 分页缓存技术:将提示词拆解存储,动态内容变更时只需重算变动部分
实测数据显示,它能将OpenClaw的响应速度提升5-10倍,且支持8倍并发。菜单栏就能直接管理,而且用起来还算丝滑。如果能把这个东西用好或者让龙虾改一改提高在自己身上的适应性,我觉得一定会带来更棒的使用体验的,尤其是多龙虾/Agents Team的用户应该能解决高并发响应慢的问题。
Github:github.com/jundot/omlx
中文





@muuyuu666 核心问题是 Qwen3.5-4B 的参数不够。
有条件的话把这台 Mac Mini 上的应用最小化,留出内存空间跑 Qwen3.5-9B 即便是 4-bit 6-bit 也会有更好的效果。
记得在 Apple Silicon 上用 MLX 而不是 llama.cpp 那是给没有条件用 MLX 的 Linux / Windows 等用的。
推荐这个 huggingface.co/Jackrong/MLX-Q…
中文
llama.cpp 在同一台机器上的有效带宽利用 48.57 t/s x 4.21 GB/t = 204.4 GB/s
llama.cpp 的 Q8_0 Q8_K_XL 采用特定的 Block 结构,在 Decode 阶段 GPU 的 SIMD 需要去实时反量化。
而 MLX 的 8-bit 量化格式与 Apple MPS 原生指令高度契合,能利用硬件级高效指令瞬间完成反量化操作并直送计算单元。
terrific@terrywang
以 Qwen3.5 4B dense 模型为例 参数 4.21B 使用 8-bit 量化,每个参数占 1 Byte 生成每个 token 至少需读取的模型数据 data per token 约 4.21GB MLX 有效带宽利用 89.28 t/s x 4.21 GB/t = 375.8 GB/s 是低阶版 M4 Max 32-core GPU 内存带宽物理极限 410 GB/s 的 91.4% 顶配 40-core 极限的 68.9%
中文
@terrywang 今天折腾了下用 ollama 跑 mlx 版本的 qwen3.5 还没搞通…大佬有没有更简单的办法能跑起来的
中文


能省这么多 token 吗,是在 Claude Code 前面再加一层代理做过滤、压缩和重组,把更短的结果送进模型上下文。主打收益是 token 消耗降低约 60% 到 90%,使用 Rust 实现,零依赖和低于 10ms 的额外开销。

Pedram Amini@pedramamini
Such a simple idea... RTK is a CLI wrapper for reducing the token cost generated from all of your favorite tools: github.com/rtk-ai/rtk Depicted are my personal savings from a few days of running the tool. I'm seeing friends with >60% efficiency scores. If you're curious about the other, few, global changes I make to my Claude Code setup, well read this blog my AI wrote about it: pedsidian.pedramamini.com/Claude/Blog/20… Covers LSP, memory, and more.
中文

@JoshKale ran Qwen 30B on M4 Max at 140 tok/s. if M5 delivers 4x that bandwidth, local 70B inference stops being a science project and becomes a daily workflow
English

Apple just made the most important chip design change in Apple Silicon history. The M5 Pro and M5 Max are now 2 chips fused together.
They broke the CPU and GPU apart onto separate pieces of silicon and reconnected them using the same packaging tech that goes into data center AI chips.
The clever part:
the M5 Pro and M5 Max use the EXACT SAME CPU. Identical. The only difference is how much GPU they bolt on:
- 20 cores for Pro
- 40 for Max
Like Lego blocks for silicon
Why this matters: smaller chips are cheaper to make, run cooler under heavy loads, and, most importantly, Apple can now scale the GPU up or down without redesigning the whole chip. This is how they'll build the Ultra. This is how they'll build whatever comes after
Everyone's going to talk about speed today. The real story is that Apple just changed how it builds chips and this is the foundation for the next decade of Apple Silicon
Marques Brownlee@MKBHD
Finally, new M5 Pro and M5 Max Macbook Pros: apple.com/newsroom/2026/…
English

通义千问新出的 Qwen3.5-35B-A3B,直接把单卡长上下文推理卷到了新高度。
350亿参数的模型,但每次生成只激活30亿参数,用的是门控增量混合架构:256个专家,每次只调用8个,每4层才做一次注意力计算,天生就省算力、省显存。
最离谱的是长上下文表现:
单张24GB显存的RTX 3090,直接开满 262K超长上下文,跑出 112 token/秒,而且从4K到262K上下文,速度几乎不掉!
传统35B模型一上长上下文,KV缓存爆炸、速度暴跌,24GB显存根本扛不住。
而这模型40层里只有10层用普通注意力,剩下30层是固定显存的循环结构,上下文再长,显存占用几乎不变。
满跑262K上下文,总显存才 22.4GB,24GB显卡轻松拿下。
更夸张的是社区力量:
5天、15块显卡,峰值速度冲到 176 tok/s。
48小时内,各路显卡都刷出了高分:
• 优化前:默认50 tok/s左右
• 优化后:直接翻倍,5090跑到176 tok/s
核心就5个参数,把层全卸到GPU、压缩KV缓存、开满上下文、精简循环状态、开Flash Attention,一夜之间性能质变。
总结一句话:
一张消费级显卡、24GB显存、零API费用,就能跑35B级、262K上下文、百tok/s级的大模型。
这不是小升级,是本地AI推理的里程碑式突破。
中文

太顶了!!
干翻 App Store 啊
干翻 setapp
Raycast 过去的生态和积累,完美契合
没有更适合做这个的其他公司和产品了!
已加 waitlist glazeapp.com
Raycast@raycast
Today we're launching Glaze 💠 Create any desktop app in minutes by chatting with AI. Beautiful, powerful, and truly personal. Learn more on glazeapp.com Follow @glazeapp for updates.
中文
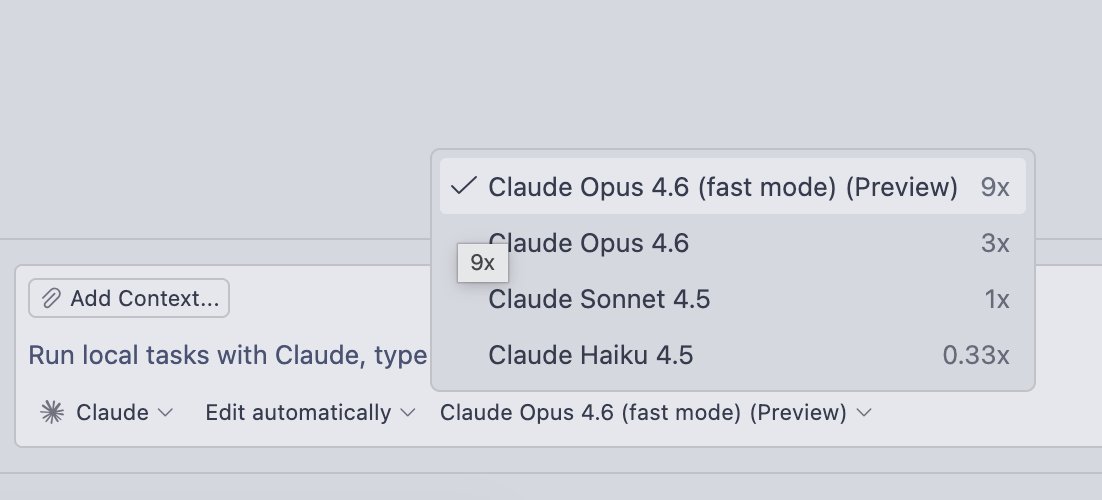
@app_sail 我就是搞中转的,国内大模型公司都有合作,我们内部也在跑 openclaw 直接干 opus4.6,成本大概不到 20%
中文




什么叫占用公共资源,每次明星道歉都会这么说
今天我终于明白了,这里说的不是占用了大家的注意力,或者热点,热搜。网络上吸引注意力不是理所当然的吗。
其实它指的是占用了很多相关部门以及网警审核员的关注,这部分是吃财政饭的,自然是「公共资源」
中文