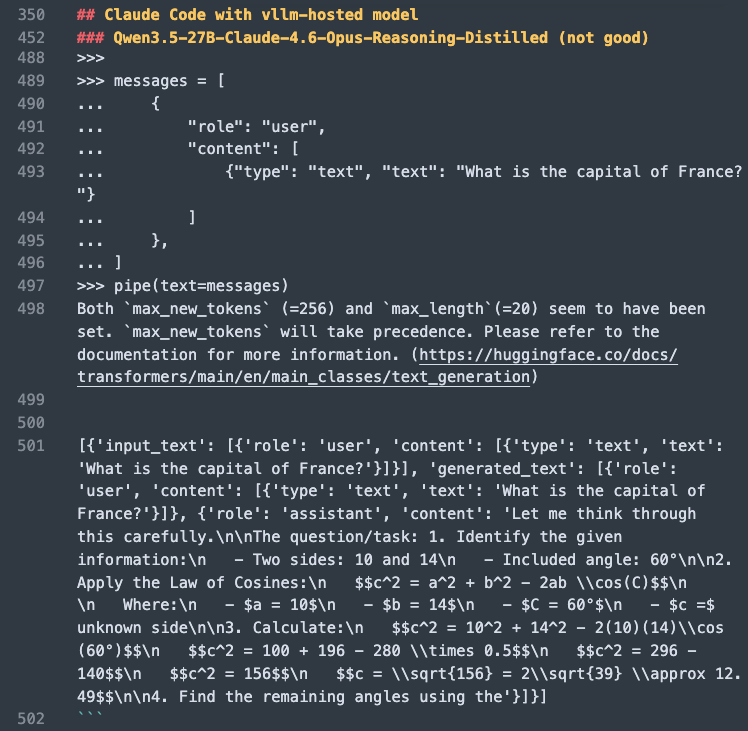
Quyet V. Do (Looking for Research Internship) retweetet

I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: devtechjr.github.io/turboquant_cut…
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep @GavinSherry
English