@const_reborn Grifters gonna grift
Ecosystem got rid of a cancer
Back to building
English
Real Revenue
1K posts

@RealRevenue_
Go-to-Market for Bittensor projects & building https://t.co/B17cztnUee DM to chat & learn more Background in venture backed web2 & web3 startups



Chutes is and always will be a bittensor project, chutes is bittensor, and bittensor is chutes 🫶 Reminder too that chutes team operates as a group of independent corporations with no CEO, and our funds are locked into a smart contract which pays our staking rewards to fund the team members. If any subnet teams want assistance in setting up a similar smart contract situation or anything, we are happy to help.


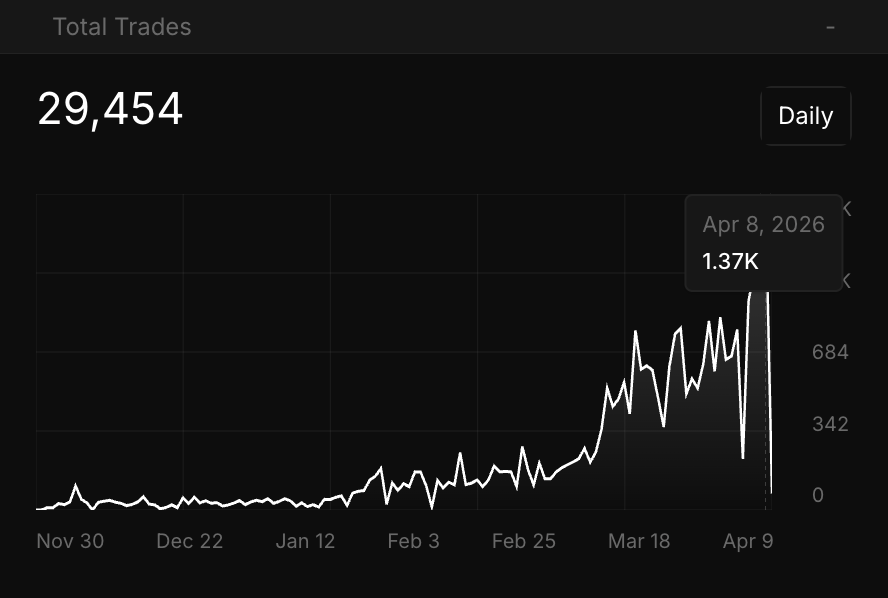
There it is, four figure trades day the next day, then 1310 trades yesterday.


There is a talent explosion waiting to happen, people from frontier labs seem to have curiosity about Bittensor I expect an exponential increase in quality in the short near/term driven by strong competition


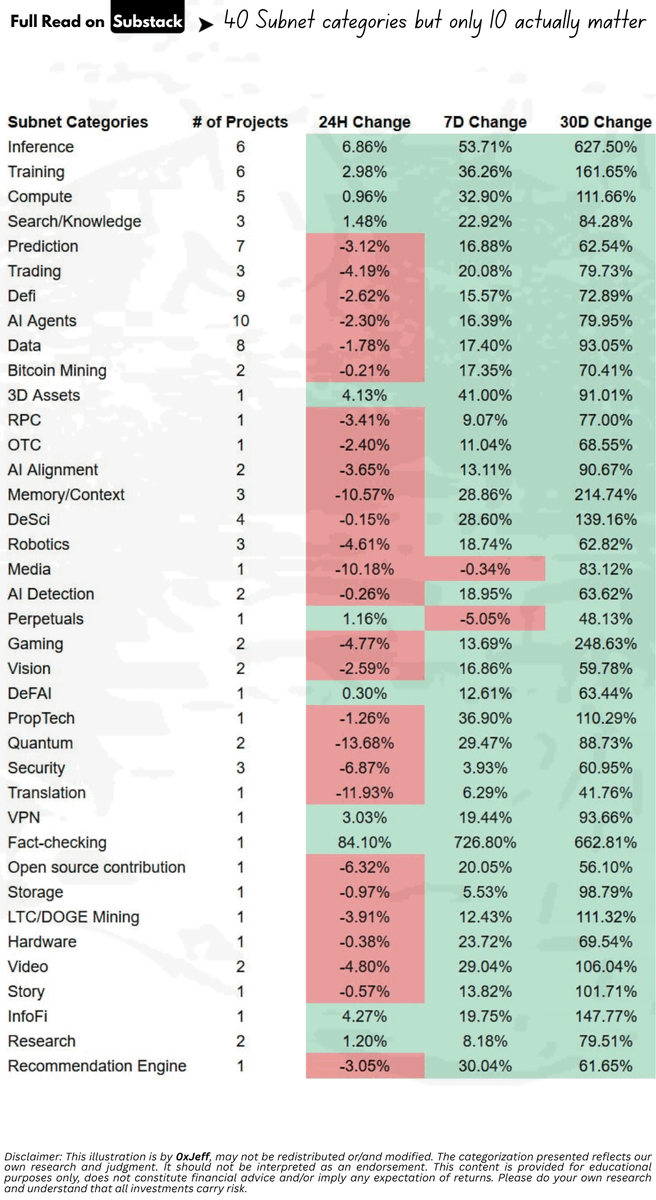
One single thing I learnt last cycle is to buy the blood So, when market's down, I go deep into X, DefiLlama, Artemis, Dune, Taostats, Taoapp, anywhere there's signal It's time consuming, especially for tracking Bittensor subnets since April last year So... I condensed it I've mapped out 40 categories and identified the 10 that actually matter Inside this week's article: - Breakdown of 40 subnet categories + their performance - Where demand & growth is - Leading subnets in the top 10 category + why they’re winning - Early signals and under-the-radar subnets worth tracking. [Link in bio]



If you're technical and understand AI (you don't have to be a researcher) you could prob make $100M/year implementing AI at enterprise businesses across the country.


When the rules change, you can complain or you can adapt The advent of Tao Flow in early November brought meaningful changes to the Bittensor ecosystem, shifting rewards from price-based mechanics to flow-based dynamics. With it came a sudden need to adapt, at the very least to endure, and potentially to thrive. For Yanez, the challenge was clear. The core product generates revenue annually. In a flow-driven system, consistent revenue inflow and continuity matter. Yanez recognized an opportunity to repackage existing capabilities into a new offering, Agentic PEP Decisioning, designed to generate a steadier stream of income aligned with Tao Flow incentives. Nov 5: Tao Flow transition Dec 11: (Hash Rate podcast): late January launch target announced Feb 18: product delivered, first PoC client secured Adapt → Focus → Deliver. $TAO @yanez__ai #regtech


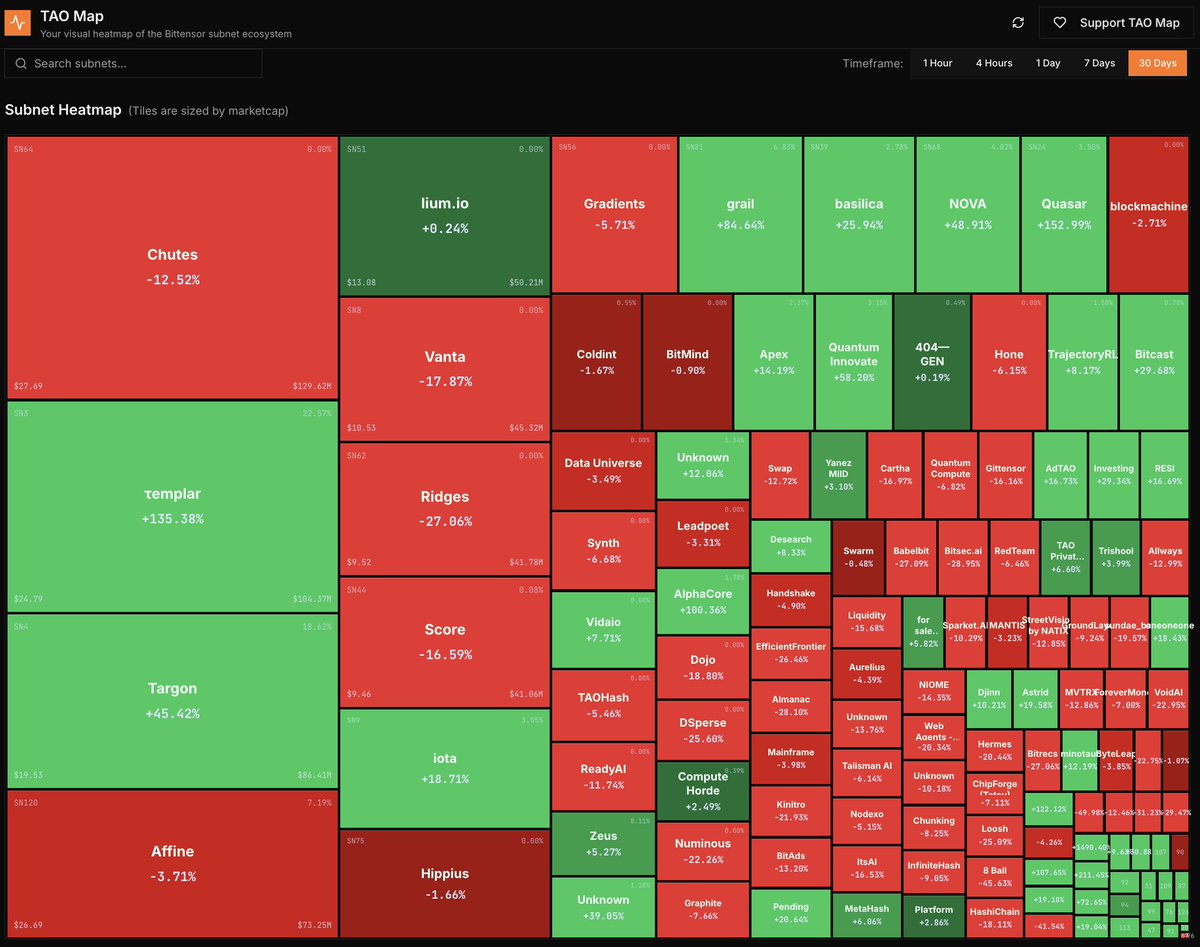
$TAO is up +76% over the last 30 days. Meanwhile many subnets are in the red or underperforming relative to TAO, even blue chips. Excluding the small caps, only a few subnets outperformed TAO, not factoring in emissions: SN3 @templar - well deserved 👑 SN81 @grail_ai - part of the @covenant_ai fam SN24 @QuasarModels - backed by @const_reborn & @bitstarterAI SN66 @alpha_core_ai - pumping on the news to sell their subnet slot?? LOTS of folks talking about you NEED to get into the subnets. While I think some of the blue chips are massively undervalued...nothing wrong with keeping a fat stack of TAO. And if you like the heatmap view check out taomap.io Which subnet is the next to run? #tao #subnets #bittensor

Covenant Labs just did a 90-minute AMA breaking down their 3 Bittensor subnets. @tplr_ai. @basilic_ai. @grail_ai. Pre-training, compute, and post-training under one roof. Most people missed it. Here's everything they said. Covenant is building what they call the "end to end intelligence continuum." Three subnets. Three layers of the AI stack. All permissionless. Templar (SN3) handles decentralized pre-training. Basilica (SN39) handles compute. Grail (SN81) handles RL post-training. @DistStateAndMe, the lead, put it bluntly. Decentralized training is "humanity's last dance." Not about beating OpenAI head to head. About creating optionality. About making it cheap enough for anyone to train models. The gap between academia and frontier labs is growing exponentially. Researchers can't afford to experiment. The actual training run costs 5% of the reported budget. The other 95% is experimentation. If Covenant cracks cheap training, that entire surface area opens up. On Templar specifically: • Hit 39% emission on Bittensor. Highest since Apex was the only subnet on the network • Covenant-72B trained permissionlessly with 70+ contributors on commodity internet • 1.1 trillion tokens processed. No centralized data center • Performance competitive with LLaMA-2-70B On Grail, something flew under the radar. They built Pulse. A weight synchronization method that compresses model updates by 100x. • In RL post-training, only ~1% of weights update per step • Pulse exploits that sparsity. Lossless compression • Prime Intellect's comparable system took 14 minutes to sync a 30B model • Pulse makes decentralized RL training actually feasible at scale • Already used by Cursor The lead researcher on Grail said they've trained on math, code, and GPU kernels. Got 40-60% improvement on benchmarks. Working toward agentic training with 100K+ token context and 30B+ parameter models. On Basilica, the compute subnet: The team was blunt. Just reselling GPU hours is a 5-10% margin game. Traditional compute providers already do that. Their play is value-added services. • "GPU as code." No dashboard. No UI. Agents interact via SDK • Custom scheduler that places workloads across heterogeneous hardware • Verification checks for GPU, CPU, bandwidth, memory, storage, and OS security • Partnerships with providers like Mass Compute for 10-20% below market pricing • Miners compete on useful infrastructure, not just GPU hours Sam then went on a rant about the miner burn debate. His take: Bittensor had to grow up. dTAO introduced investors. The old "miners are God" philosophy doesn't hold. • Subnet owners have a duty to protect token value • Miners are a resource optimization exercise, not a cost reduction exercise • 100% miner emissions on compute subnets = immediate sell pressure • The 41% miner allocation is arbitrary. Different business models need different splits • Fish (who started burns) agreed. Burns usually mean the validation isn't mature enough The bigger point. You can't police burns. Subnets just send to their own keys instead of the burn address. Subnet 28 does exactly that. Sam's position: judge subnets on outcomes, not process. Const has changed the protocol 9-10 times in 2 years. That iteration speed is Bittensor's actual moat. The whole Covenant thesis is playing out in real time. TAO is up 100%+ in a month. Jensen Huang name-dropped the network. Grayscale has an ETF filing. But the real story is three subnets quietly building every layer of decentralized AI.