GLM 5.1 is the slowest frontier model we've ever benchmarked on BridgeBench.
44.3 tokens per second.
Half the speed of GPT 5.4.
Nearly 6x slower than Grok 4.20.
Z.ai traded all of their speed for intelligence.
The coding benchmarks improved.
The throughput collapsed.
In 2026, agentic coding is about parallelism.
You're running 5, 10, 15 agents at once.
A model this slow bottlenecks every workflow it touches.
Intelligence without speed is a luxury most vibe coders can't afford.
bridgebench.ai
@briantexts solid point. async + thorough planning is a legit workflow where speed matters less. it's the parallel agent use case where latency kills you
@bridgebench I value the model's intelligence over speed when building real software.
Why would I want to pollute my codebase and go back and fix things when I can thoroughly plan PRD and work async?
@bridgebench it is highly variable and their infra sucks
before y'all went hammering things with your benches, I was working around the normal speed
can't you wait for me to sleep to do that ?
XD
@bridgebench Not only that, but their API is using a quantized model for sure; the quality is subpar. After a 70-80k context window, it gives you gibberish.
@bridgebench How much do you think has intelligence increased compared to to glm-5 and turbo variant? I’m using 5.1 and it seems to work at a normal rate, not as fast as codex, cc tho
@stepbystepnomad that's a fair take. availability matters just as much as speed. if Claude keeps going down, slower alternatives start looking a lot more attractive
I suspect GLM, Kimi etc are under higher than normal load as Claude is dishing out both today:
- major incidents taking availability offline (again)
- cutting max users token limits to levels that don't support a couple hours work
For a model to be good - its has to be available.
@joeychilson good point. the model itself might not be the bottleneck, the infrastructure serving it is. would be interesting to see GLM 5.1 benchmarked on a provider with better compute
@bridgebench I'm pretty sure it's slow because they don't have the compute is serve the model. This is pretty typical of open source models from China.
GLM-5 served through them is also slow, but much faster on providers that do have compute and access to the latest chips.
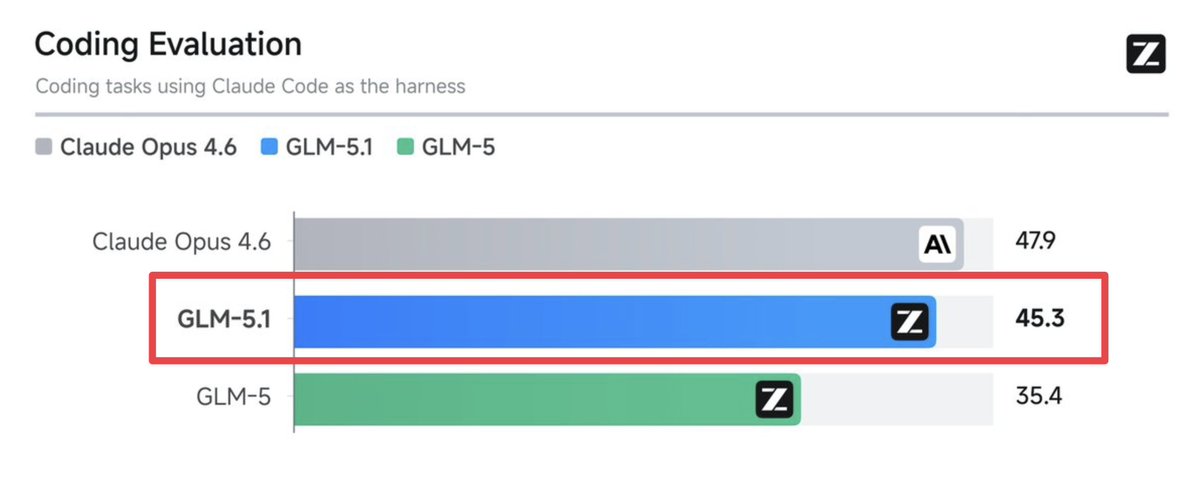
GLM 5.1 just dropped.
45.3 on the coding evaluation using Claude Code as the harness.
2.6 points behind Claude Opus 4.6 at 47.9.
Nearly 10 points ahead of GLM 5 at 35.4.
An open source model is within striking distance of the best closed source coding model in the world.
Z.ai keeps shipping.
The gap between open source and frontier keeps shrinking.
Need to get GLM 5.1 on BridgeBench and see how it performs in real vibe coding workflows.
bridgebench.ai
GLM 5.1 just released.
We're adding it to BridgeBench.
45.3 on the coding evaluation.
2.6 points behind Claude Opus 4.6.
Open source closing the gap fast.
Full BridgeBench results dropping soon.
Overall, Algo, Debug, Refactor, Gen, UI, Security, Speed, Cost, and Completion Rate.
Benchmarks don't lie. Let's see how it holds up.