Angehefteter Tweet

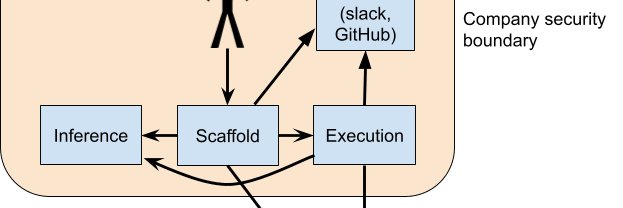
We’ve just released the biggest and most intricate study of AI control to date, in a command line agent setting. IMO the techniques studied are the best available option for preventing misaligned early AGIs from causing sudden disasters, e.g. hacking servers they’re working on.
English















