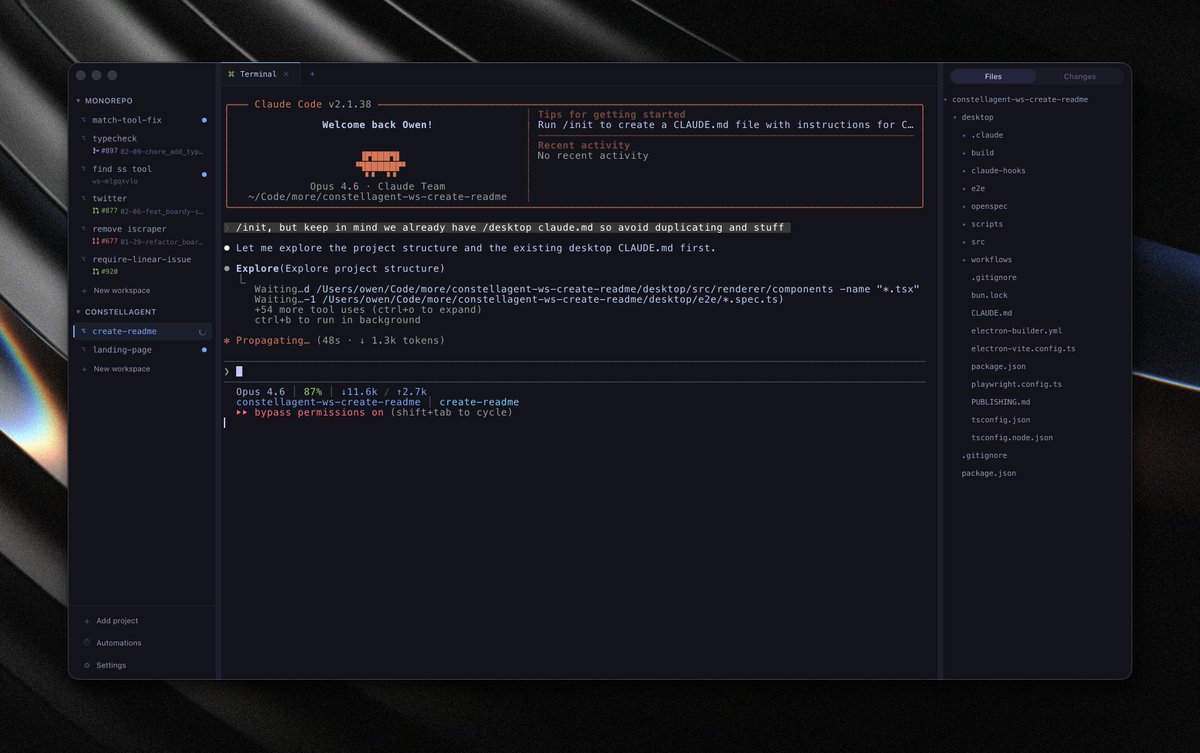
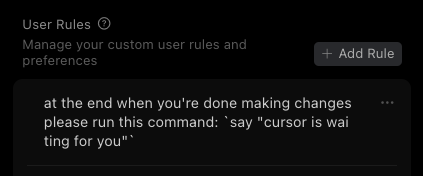
I tried all of the TUI coding agents and not a single one of them feels perfect, yet all have some unique features I like.
Maybe the future is everyone building their own.
It's easy to start and when you need new features you just say "hey copy feature X from agent Y".
English