
Pete Walsh
31 posts

Pete Walsh
@epwalsh
Research Engineer @allen_ai | Python | Rust | Neovim
Beigetreten Nisan 2024
164 Folgt131 Follower

@soldni @finbarrtimbers This is it. But if you want to use dataclasses AND be able to ser/deserialize to/from json/yaml, I wrote a little library for that: github.com/epwalsh/datacl…
Eventually we're going to replace omegaconf with that in olmo-core.
English


@saurabh_shah2 @finbarrtimbers We use FSDP2 now (what torchtitan uses) because it’s just DTensor under the hood, which plays nicely with other axes of parallelism. I don’t think there’s much difference in performance between the old FSDP and the new.
English
@finbarrtimbers I’m not sure if they still do but pretrain used FSDP when I worked w them, maybe poke Pete and ask
English
Pete Walsh retweetet

Introducing olmOCR, our open-source tool to extract clean plain text from PDFs!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
English
Pete Walsh retweetet

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train
🚜 compute infra
👇🧵

English
@Tanishq97836660 Hey Tanishq, really interesting work. I'm curious if your low-precision training setup involves keeping the main copy of the weights in full precision (like with how torchao's Float8Linear works)?
English

[3/7] We then turn our attention to training in low precision. We study both quantization-aware training (weights only) and low-precision training (everything in low precision). We decompose the model into weights, activations, and KV cache, finding scaling laws for loss when any of these are quantized to any precision, and develop a compositional and interpretable functional form to predict the effect on loss of quantizing any combination of the three during pretraining.
English
[1/7] New paper alert! Heard about the BitNet hype or that Llama-3 is harder to quantize? Our new work studies both! We formulate scaling laws for precision, across both pre and post-training arxiv.org/pdf/2411.04330. TLDR;
- Models become harder to post-train quantize as they are overtrained on lots of data, so that eventually more pretraining data can be actively harmful if quantizing post-training!
- The effects of putting weights, activations, or attention in varying precisions during pretraining are consistent and predictable, and fitting a scaling law suggests that pretraining at high (BF16) and next-generation (FP4) precisions may both be suboptimal design choices!
Joint work with @ZackAnkner @bfspector @blake__bordelon @Muennighoff @mansiege @CPehlevan @HazyResearch @AdtRaghunathan.

English
Pete Walsh retweetet

Releasing OLMoE - the first good Mixture-of-Experts LLM that's 100% open-source
- 1B active, 7B total params for 5T tokens
- Best small LLM & matches more costly ones like Gemma, Llama
- Open Model/Data/Code/Logs + lots of analysis & experiments
📜arxiv.org/abs/2409.02060
🧵1/9

English
Pete Walsh retweetet

Congrats to our team for winning two paper awards at #ACL2024!
OLMo won the Best Theme Paper award, and Dolma won a Best Resource Paper award!
All the credit goes to the whole team for the massive group effort 🎉🎉




English
English

Also, thanks to Rodney Kinney, @AnanyaHarsh, Pete Walsh, and @davidjwadden for contributing to Rusty-DAWG as part of the @allen_ai hackathon!
English
📜New preprint w/ @nlpnoah and @yanaiela that evaluates the novelty of LM-generated text using our n-gram search tool Rusty-DAWG 🐶
Code: github.com/viking-sudo-rm…
Paper: arxiv.org/abs/2406.13069
English
I attempted the Three Sisters Ski Traverse in one day with a buddy earlier this week. Despite the seemingly endless number of transitions between booting, skinning, and skiing, there were some great moments like standing on top of Middle Sister and skiing perfect corn snow ⛷️
English
Thankfully we got to the road just before sunset and got watch this very cool moonrise above Mt Bachelor to close out the day 🌔

English
It took us 14 hours to cover 18.5 miles with 7.5k of vertical gain, though we had to bail short of the summit of South Sister as we were running out of daylight.

English
But there were also many "wtf are we doing moments" like walking for hours to get to the snow line or realizing our planned route up the final peak (South Sister) and down to our pickup location wasn't going to be straightforward.




English
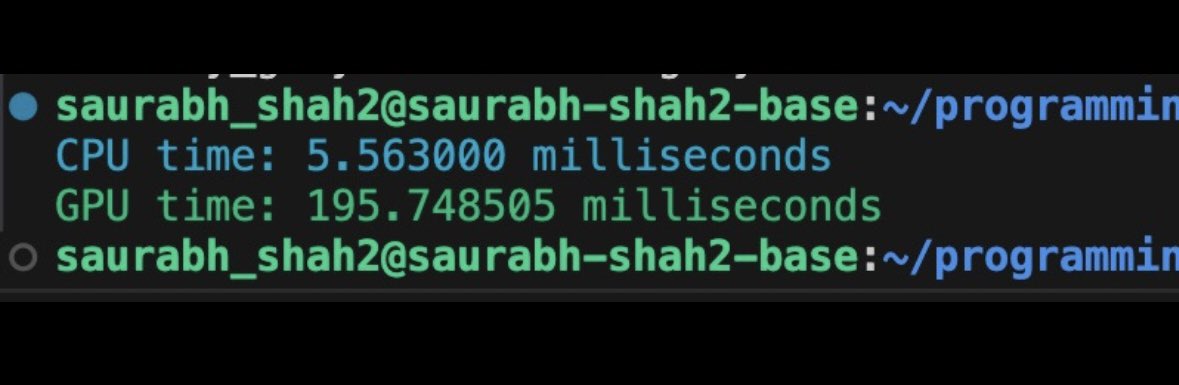
@saurabh_shah2 Oh cool I was just looking for some light reading material
English
@epwalsh LMAO it’s actually ~/programming-massively-parallel-processors which is the name of the textbook I’m learning from
English
@epwalsh Only thing that could make you cooler at this point is if you snowboarded instead of skied
English
To train a neural network you have to become one.
Feel the gradient descent for yourself.
Very bullish on AI2/olmo 🚀
Pete Walsh@epwalsh
Closing day pond skim at Mt Bachelor ⛷️
English